Kurzor v SQL Server je d atabase objekt, který nám umožňuje načíst každý řádek najednou a manipulovat s jeho daty . Kurzor není nic jiného než ukazatel na řádek. Vždy se používá ve spojení s příkazem SELECT. Obvykle se jedná o sbírku SQL logika, která prochází předem určeným počtem řádků jeden po druhém. Jednoduchá ilustrace kurzoru je, když máme rozsáhlou databázi záznamů pracovníků a chceme vypočítat mzdu každého pracovníka po odečtení daní a dovolené.
SQL Server Účelem kurzoru je aktualizovat data řádek po řádku, měnit je nebo provádět výpočty, které nejsou možné, když načteme všechny záznamy najednou . Je také užitečné pro provádění administrativních úloh, jako je zálohování databáze SQL Server v sekvenčním pořadí. Kurzory se používají hlavně ve vývojových, DBA a ETL procesech.
Tento článek vysvětluje vše o kurzoru SQL Server, jako je životní cyklus kurzoru, proč a kdy se kurzor používá, jak implementovat kurzory, jeho omezení a jak můžeme kurzor nahradit.
Životní cyklus kurzoru
Životní cyklus kurzoru můžeme popsat do pět různých sekcí jak následuje:
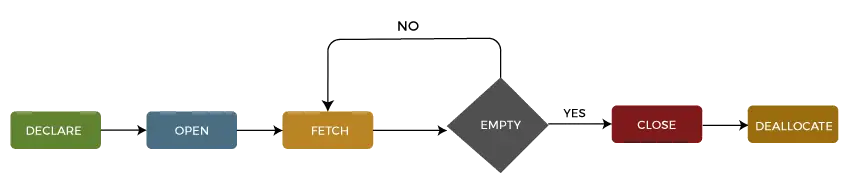
1: Deklarace kurzoru
Prvním krokem je deklarace kurzoru pomocí níže uvedeného příkazu SQL:
program v Javě
DECLARE cursor_name CURSOR FOR select_statement;
Kurzor můžeme deklarovat tak, že za klíčové slovo DECLARE uvedeme jeho název s datovým typem CURSOR. Poté napíšeme příkaz SELECT, který definuje výstup pro kurzor.
2: Otevřete kurzor
Je to druhý krok, ve kterém otevřeme kurzor pro uložení dat načtených ze sady výsledků. Můžeme to udělat pomocí níže uvedeného příkazu SQL:
OPEN cursor_name;
3: Načíst kurzor
Je to třetí krok, ve kterém lze načítat řádky jeden po druhém nebo v bloku za účelem manipulace s daty, jako je vkládání, aktualizace a mazání na aktuálně aktivním řádku kurzoru. Můžeme to udělat pomocí níže uvedeného příkazu SQL:
FETCH NEXT FROM cursor INTO variable_list;
Můžeme také použít Funkce @@FETCHSTATUS v SQL Server, abyste získali stav posledního kurzoru příkazu FETCH, který byl proveden proti kurzoru. The VYNÉST příkaz byl úspěšný, když @@FETCHSTATUS dává nulový výstup. The ZATÍMCO příkaz lze použít k načtení všech záznamů z kurzoru. Následující kód to vysvětluje jasněji:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: Zavřete kurzor
Je to čtvrtý krok, ve kterém by měl být kurzor uzavřen poté, co jsme dokončili práci s kurzorem. Můžeme to udělat pomocí níže uvedeného příkazu SQL:
CLOSE cursor_name;
5: Přidělte kurzor
Je to pátý a poslední krok, ve kterém vymažeme definici kurzoru a uvolníme všechny systémové prostředky spojené s kurzorem. Můžeme to udělat pomocí níže uvedeného příkazu SQL:
DEALLOCATE cursor_name;
Použití SQL Server Cursor
Víme, že systémy pro správu relačních databází, včetně SQL Serveru, jsou vynikající při práci s daty na sadě řádků nazývaných sady výsledků. Například , máme stůl product_table který obsahuje popis produktů. Pokud chceme aktualizovat cena produktu, pak níže uvedený „ AKTUALIZACE' dotaz aktualizuje všechny záznamy, které odpovídají podmínce v ' KDE' doložka:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Někdy aplikace potřebuje zpracovat řádky jediným způsobem, tj. řádek po řádku, nikoli celou sadu výsledků najednou. Tento proces můžeme provést pomocí kurzorů v SQL Server. Před použitím kurzoru musíme vědět, že kurzory mají velmi špatný výkon, takže by se měl vždy používat pouze v případě, že neexistuje žádná možnost kromě kurzoru.
Kurzor používá stejnou techniku jako my používáme smyčky jako FOREACH, FOR, WHILE, DO WHILE k iteraci jednoho objektu po druhém ve všech programovacích jazycích. Proto by mohl být vybrán, protože používá stejnou logiku jako proces smyčkování programovacího jazyka.
ctc plná forma
Typy kurzorů v SQL Server
Níže jsou uvedeny různé typy kurzorů v SQL Server:
- Statické kurzory
- Dynamické kurzory
- Kurzory pouze vpřed
- Kurzory sady kláves

Statické kurzory
Sada výsledků zobrazená statickým kurzorem je vždy stejná jako při prvním otevření kurzoru. Protože statický kurzor uloží výsledek do tempdb , jsou vždy pouze ke čtení . Pro pohyb vpřed i vzad můžeme použít statický kurzor. Oproti ostatním kurzorům je pomalejší a spotřebovává více paměti. V důsledku toho jej můžeme použít pouze tehdy, když je nutné rolování a jiné kurzory nejsou vhodné.
Tento kurzor zobrazuje řádky, které byly z databáze odstraněny po jejím otevření. Statický kurzor nepředstavuje žádné operace INSERT, UPDATE nebo DELETE (pokud kurzor nezavřete a znovu neotevřete).
Dynamické kurzory
Dynamické kurzory jsou opačné než statické kurzory, které nám umožňují provádět operace aktualizace, mazání a vkládání dat, když je kurzor otevřený. to je ve výchozím nastavení rolovatelné . Dokáže detekovat všechny změny provedené v řádcích, pořadí a hodnotách v sadě výsledků, ať už ke změnám dojde uvnitř kurzoru nebo mimo něj. Mimo kurzor nevidíme aktualizace, dokud nejsou potvrzeny.
Kurzory pouze vpřed
Je to výchozí a nejrychlejší typ kurzoru mezi všemi kurzory. Říká se tomu kurzor pouze vpřed, protože je se posouvá pouze dopředu přes sadu výsledků . Tento kurzor nepodporuje rolování. Může načíst pouze řádky od začátku do konce sady výsledků. Umožňuje nám provádět operace vkládání, aktualizace a mazání. Zde je efekt operací vložení, aktualizace a odstranění provedených uživatelem, které ovlivňují řádky v sadě výsledků, viditelný, když jsou řádky načteny z kurzoru. Když byl řádek načten, nevidíme změny provedené v řádcích přes kurzor.
Kurzory pouze vpřed jsou tři kategorizované do tří typů:
- Forward_Only Keyset
- Forward_Only Static
- Rychle vpřed

Kurzory řízené sadou kláves
Tato funkce kurzoru leží mezi statickým a dynamickým kurzorem o jeho schopnosti detekovat změny. Nemůže vždy detekovat změny v členství a pořadí sady výsledků jako statický kurzor. Dokáže detekovat změny v hodnotách řádků sady výsledků jako dynamický kurzor. Může jen přesunout z první do poslední a poslední do první řady . Pokaždé, když se otevře tento kurzor, je pořadí a členství pevné.
Je ovládán sadou jedinečných identifikátorů stejných jako klíče v sadě klíčů. Sada klíčů je určena všemi řádky, které kvalifikovaly příkaz SELECT při prvním otevření kurzoru. Dokáže také detekovat jakékoli změny ve zdroji dat, který podporuje operace aktualizace a odstranění. Ve výchozím nastavení je rolovací.
Implementace příkladu
Implementujme příklad kurzoru na SQL serveru. Můžeme to udělat tak, že nejprve vytvoříme tabulku s názvem ' zákazník “ pomocí níže uvedeného prohlášení:
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Dále do tabulky vložíme hodnoty. Pro přidání dat do tabulky můžeme provést následující příkaz:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Údaje můžeme ověřit provedením VYBRAT prohlášení:
SELECT * FROM customer;
Po provedení dotazu můžeme vidět níže uvedený výstup, kde máme osm řádků do tabulky:

Nyní vytvoříme kurzor pro zobrazení záznamů zákazníků. Níže uvedené úryvky kódu vysvětlují všechny kroky deklarace nebo vytvoření kurzoru tím, že vše dají dohromady:
typ proměnné java
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Po provedení kurzoru získáme následující výstup:

Omezení SQL Server Cursor
Kurzor má určitá omezení, takže by se měl vždy používat pouze v případě, že neexistuje žádná možnost kromě kurzoru. Tato omezení jsou:
- Cursor spotřebovává síťové zdroje tím, že vyžaduje zpáteční síť pokaždé, když načte záznam.
- Kurzor je v paměti rezidentní sada ukazatelů, což znamená, že zabírá určitou paměť, kterou by na našem počítači mohly využít jiné procesy.
- Při zpracování dat uvaluje zámky na část tabulky nebo na celou tabulku.
- Výkon a rychlost kurzoru jsou pomalejší, protože aktualizují záznamy tabulky jeden řádek po druhém.
- Kurzory jsou rychlejší než smyčky while, ale mají větší režii.
- Počet řádků a sloupců přenesených do kurzoru je dalším aspektem, který ovlivňuje rychlost kurzoru. Udává, jak dlouho trvá otevření kurzoru a provedení příkazu načtení.
Jak se můžeme vyhnout kurzorům?
Hlavním úkolem kurzorů je procházet tabulkou řádek po řádku. Nejjednodušší způsob, jak se vyhnout kurzorům, je uveden níže:
Použití smyčky SQL while
Nejjednodušší způsob, jak se vyhnout použití kurzoru, je použít cyklus while, který umožňuje vložení sady výsledků do dočasné tabulky.
Uživatelsky definované funkce
Někdy se k výpočtu výsledné sady řádků používají kurzory. Toho můžeme dosáhnout použitím uživatelem definované funkce, která splňuje požadavky.
Pomocí spojení
Join zpracovává pouze ty sloupce, které splňují zadanou podmínku, a tím redukuje řádky kódu, které poskytují rychlejší výkon než kurzory v případě, že je třeba zpracovat velké záznamy.