Graf kvantil-kvantil (q-q graf) je grafická metoda pro určení, zda soubor dat sleduje určité rozdělení pravděpodobnosti nebo zda dva vzorky dat pocházejí ze stejného populace nebo ne. Grafy Q-Q jsou zvláště užitečné pro posouzení, zda soubor dat je normálně distribuované nebo pokud následuje po nějaké jiné známé distribuci. Běžně se používají ve statistice, analýze dat a kontrole kvality ke kontrole předpokladů a identifikaci odchylek od očekávaných distribucí.
Kvantily A Percentily
Kvantily jsou body v datové sadě, které rozdělují data do intervalů obsahujících stejné pravděpodobnosti nebo podíly na celkové distribuci. Často se používají k popisu šíření nebo distribuce datové sady. Nejběžnější kvantily jsou:
- Medián (50. percentil) : Medián je střední hodnota datové sady, když je seřazena od nejmenší po největší. Rozdělí datovou sadu na dvě stejné poloviny.
- Kvartily (25., 50. a 75. percentil) : Kvartily rozdělují datovou sadu na čtyři stejné části. První kvartil (Q1) je hodnota, pod kterou spadá 25 % dat, druhý kvartil (Q2) je medián a třetí kvartil (Q3) je hodnota, pod kterou spadá 75 % dat.
- Percentily : Percentily jsou podobné kvartilům, ale rozdělují soubor dat na 100 stejných částí. Například 90. percentil je hodnota, pod kterou spadá 90 % dat.
Poznámka:
- q-q graf je graf kvantilů prvního souboru dat proti kvantilům druhého souboru dat.
- Pro referenční účely je také vykreslena 45% čára; Pro pokud jsou vzorky ze stejné populace, pak jsou body podél této linie.
Normální distribuce:
Normální rozdělení (neboli Gaussova distribuce Bellova křivka) je spojité rozdělení pravděpodobnosti reprezentující rozdělení získané z náhodně generovaných reálných hodnot.
. 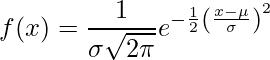

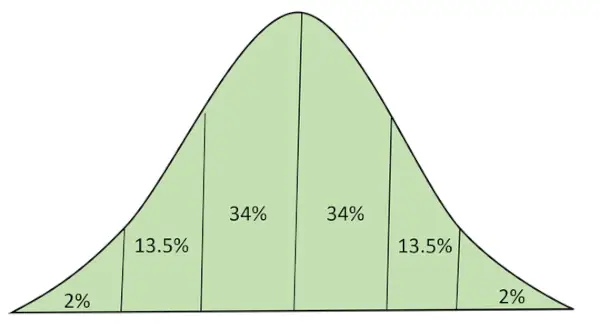
Normální rozložení s oblastí pod křivkou
Jak nakreslit Q-Q graf?
Chcete-li nakreslit kvantilově-kvantilový (Q-Q) graf, můžete postupovat takto:
- Sbírejte data : Shromážděte datovou sadu, pro kterou chcete vytvořit graf Q-Q. Ujistěte se, že data jsou číselná a představují náhodný vzorek ze sledované populace.
- Seřadit data : Uspořádejte data ve vzestupném nebo sestupném pořadí. Tento krok je nezbytný pro přesný výpočet kvantilů.
- Vyberte teoretické rozdělení : Určete teoretické rozdělení, se kterým chcete porovnat svou datovou sadu. Mezi běžné možnosti patří normální rozdělení, exponenciální rozdělení nebo jakékoli jiné rozdělení, které dobře odpovídá vašim datům.
- Vypočítejte teoretické kvantily : Vypočtěte kvantily pro zvolené teoretické rozdělení. Pokud například porovnáváte s normálním rozdělením, použijete k nalezení očekávaných kvantilů funkci inverzního kumulativního rozdělení (CDF) normálního rozdělení.
- Vykreslování :
- Vyneste setříděné hodnoty datové sady na osu x.
- Na osu y vyneste odpovídající teoretické kvantily.
- Každý datový bod (x, y) představuje dvojici pozorovaných a očekávaných hodnot.
- Spojte datové body a vizuálně zkontrolujte vztah mezi datovou sadou a teoretickou distribucí.
Interpretace grafu Q-Q
- Pokud body na grafu spadají přibližně podél přímky, znamená to, že vaše datová sada sleduje předpokládané rozložení.
- Odchylky od přímky indikují odchylky od předpokládaného rozložení, což vyžaduje další zkoumání.
Zkoumání podobnosti distribuce pomocí grafů Q-Q
Zkoumání podobnosti distribuce pomocí Q-Q grafů je základním úkolem ve statistice. Porovnání dvou datových souborů za účelem zjištění, zda pocházejí ze stejné distribuce, je nezbytné pro různé analytické účely. Pokud platí předpoklad společného rozdělení, sloučení datových sad může zlepšit přesnost odhadu parametrů, jako je umístění a měřítko. Q-Q grafy, zkratka pro kvantil-kvantilové grafy, nabízejí vizuální metodu pro hodnocení podobnosti distribuce. V těchto grafech jsou kvantily z jednoho souboru dat vyneseny proti kvantilům z jiného souboru. Pokud jsou body těsně zarovnány podél diagonální čáry, naznačuje to podobnost mezi distribucemi. Odchylky od této diagonální čáry indikují rozdíly v distribučních charakteristikách.
Zatímco testy jako např chí-kvadrát a Kolmogorov-Smirnov testy mohou vyhodnotit celkové rozdíly v distribuci, grafy Q-Q poskytují nuancovanou perspektivu přímým porovnáním kvantilů. To umožňuje analytikům rozeznat specifické rozdíly, jako jsou posuny v umístění nebo změny v měřítku, které nemusí být zřejmé pouze z formálních statistických testů.
Python Implementace Q-Q Plotu
Python3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate example data> np.random.seed(>0>)> data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Create Q-Q plot> stats.probplot(data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Normal Q-Q plot'>)> plt.xlabel(>'Theoretical quantiles'>)> plt.ylabel(>'Ordered Values'>)> plt.grid(>True>)> plt.show()> |
>
>
Výstup:
Q-Q graf
Zde, protože datové body přibližně sledují přímku v grafu Q-Q, naznačuje to, že soubor dat je v souladu s předpokládaným teoretickým rozdělením, které jsme v tomto případě považovali za normální rozdělení.
Výhody Q-Q grafu
- Flexibilní srovnání : Q-Q grafy mohou porovnávat datové sady různých velikostí bez vyžadující stejnou velikost vzorků.
- Bezrozměrná analýza : Jsou bezrozměrné, takže jsou vhodné pro porovnávání datových sad s různé jednotky nebo měřítka.
- Vizuální interpretace : Poskytuje jasnou vizuální reprezentaci distribuce dat ve srovnání s teoretickou distribucí.
- Citlivé na odchylky : Snadno detekuje odchylky od předpokládaných distribucí a pomáhá při identifikaci nesrovnalostí v datech.
- Diagnostický nástroj : Pomáhá při posuzování distribučních předpokladů, identifikaci odlehlých hodnot a pochopení vzorců dat.
Aplikace Quantile-Quantile Plot
Kvantilový-kvantilový graf se používá pro následující účel:
- Posouzení distribučních předpokladů : Grafy Q-Q se často používají k vizuální kontrole, zda soubor dat sleduje určité rozdělení pravděpodobnosti, jako je normální rozdělení. Porovnáním kvantilů pozorovaných dat s kvantily předpokládaného rozdělení lze zjistit odchylky od předpokládaného rozdělení. To je zásadní v mnoha statistických analýzách, kde platnost distribučních předpokladů ovlivňuje přesnost statistických závěrů.
- Detekce odlehlých hodnot : Odlehlé hodnoty jsou datové body, které se výrazně liší od zbytku datové sady. Q-Q grafy mohou pomoci identifikovat odlehlé hodnoty tím, že odhalí datové body, které jsou daleko od očekávaného vzoru distribuce. Odlehlé hodnoty se mohou objevit jako body, které se odchylují od očekávané přímky v grafu.
- Porovnání distribucí : Q-Q grafy lze použít k porovnání dvou datových sad a zjistit, zda pocházejí ze stejné distribuce. Toho je dosaženo vynesením kvantilů jednoho souboru dat proti kvantilům jiného souboru dat. Pokud body padají přibližně podél přímky, naznačuje to, že oba soubory dat jsou nakresleny ze stejného rozložení.
- Posuzování normality : Q-Q grafy jsou zvláště užitečné pro posouzení normality souboru dat. Pokud datové body v grafu těsně sledují přímku, znamená to, že soubor dat je přibližně normálně distribuován. Odchylky od linie naznačují odchylky od normality, což může vyžadovat další zkoumání nebo neparametrické statistické techniky.
- Validace modelu : V oborech, jako je ekonometrie a strojové učení, se grafy Q-Q používají k ověření prediktivních modelů. Porovnáním kvantilů pozorovaných odezev s kvantily předpovězenými modelem lze posoudit, jak dobře model odpovídá datům. Odchylky od očekávaného vzoru mohou naznačovat oblasti, kde je třeba model zlepšit.
- Kontrola kvality : Q-Q grafy se používají v procesech kontroly kvality ke sledování distribuce naměřených nebo pozorovaných hodnot v čase nebo napříč různými šaržemi. Odchylky od očekávaných vzorců v grafu mohou signalizovat změny v základních procesech, což vede k dalšímu zkoumání.
Typy Q-Q grafů
Ve statistice a analýze dat se běžně používá několik typů grafů Q-Q, z nichž každý je vhodný pro různé scénáře nebo účely:
- Normální distribuce : Symetrické rozdělení, kde graf Q-Q ukazuje body přibližně podél diagonální čáry, pokud data dodržují normální rozdělení.
- Pravoúhlé rozdělení : Distribuce, kde by graf Q-Q zobrazoval vzor, kde se pozorované kvantily odchylují od přímky směrem k hornímu konci, což ukazuje na delší konec na pravé straně.
- Distribuce zkosená doleva : Distribuce, kde by graf Q-Q vykazoval vzor, kdy se pozorované kvantily odchylují od přímky směrem ke spodnímu konci, což naznačuje delší konec na levé straně.
- Nedostatečně rozptýlená distribuce : Distribuce, kde graf Q-Q ukazuje pozorované kvantily seskupené těsněji kolem diagonální čáry ve srovnání s teoretickými kvantily, což naznačuje nižší rozptyl.
- Příliš rozptýlená distribuce : Distribuce, kde by graf Q-Q zobrazoval pozorované kvantily více rozložené nebo odchylující se od diagonální čáry, což ukazuje na vyšší rozptyl nebo disperzi ve srovnání s teoretickou distribucí.
Python3
import> numpy as np> import> matplotlib.pyplot as plt> import> scipy.stats as stats> # Generate a random sample from a normal distribution> normal_data>=> np.random.normal(loc>=>0>, scale>=>1>, size>=>1000>)> # Generate a random sample from a right-skewed distribution (exponential distribution)> right_skewed_data>=> np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from a left-skewed distribution (negative exponential distribution)> left_skewed_data>=> ->np.random.exponential(scale>=>1>, size>=>1000>)> # Generate a random sample from an under-dispersed distribution (truncated normal distribution)> under_dispersed_data>=> np.random.normal(loc>=>0>, scale>=>0.5>, size>=>1000>)> under_dispersed_data>=> under_dispersed_data[(under_dispersed_data>>->1>) & (under_dispersed_data <>1>)]># Truncate> # Generate a random sample from an over-dispersed distribution (mixture of normals)> over_dispersed_data>=> np.concatenate((np.random.normal(loc>=>->2>, scale>=>1>, size>=>500>),> >np.random.normal(loc>=>2>, scale>=>1>, size>=>500>)))> # Create Q-Q plots> plt.figure(figsize>=>(>15>,>10>))> plt.subplot(>2>,>3>,>1>)> stats.probplot(normal_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Normal Distribution'>)> plt.subplot(>2>,>3>,>2>)> stats.probplot(right_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Right-skewed Distribution'>)> plt.subplot(>2>,>3>,>3>)> stats.probplot(left_skewed_data, dist>=>'expon'>, plot>=>plt)> plt.title(>'Q-Q Plot - Left-skewed Distribution'>)> plt.subplot(>2>,>3>,>4>)> stats.probplot(under_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Under-dispersed Distribution'>)> plt.subplot(>2>,>3>,>5>)> stats.probplot(over_dispersed_data, dist>=>'norm'>, plot>=>plt)> plt.title(>'Q-Q Plot - Over-dispersed Distribution'>)> plt.tight_layout()> plt.show()> |
>
>
Výstup:
Q-Q graf pro různá rozdělení
co je případ v sql