Tento tutoriál je průvodcem pro začátečníky učení datových struktur a algoritmů pomocí Pythonu. V tomto článku probereme vestavěné datové struktury, jako jsou seznamy, n-tice, slovníky atd., a některé uživatelsky definované datové struktury, jako je propojené seznamy , stromy , grafy , atd., a procházení stejně jako vyhledávací a třídicí algoritmy pomocí dobrých a dobře vysvětlených příkladů a praktických otázek.

Seznamy
Seznamy Pythonu jsou uspořádané kolekce dat stejně jako pole v jiných programovacích jazycích. Umožňuje různé typy prvků v seznamu. Implementace Python Listu je podobná jako Vectors v C++ nebo ArrayList v JAVA. Nákladnou operací je vložení nebo odstranění prvku ze začátku seznamu, protože je potřeba posunout všechny prvky. Vkládání a mazání na konci seznamu může být také nákladné v případě, že se předem přidělená paměť zaplní.
Příklad: Vytvoření seznamu Python
Python3 List = [1, 2, 3, 'GFG', 2.3] print(List)>
Výstup
[1, 2, 3, 'GFG', 2.3]>
Prvky seznamu jsou přístupné pomocí přiřazeného indexu. V pythonu počátečním indexu seznamu je sekvence 0 a koncový index je (pokud je tam N prvků) N-1.
Příklad: Operace seznamu v Pythonu
Python3 # Creating a List with # the use of multiple values List = ['Geeks', 'For', 'Geeks'] print('
List containing multiple values: ') print(List) # Creating a Multi-Dimensional List # (By Nesting a list inside a List) List2 = [['Geeks', 'For'], ['Geeks']] print('
Multi-Dimensional List: ') print(List2) # accessing a element from the # list using index number print('Accessing element from the list') print(List[0]) print(List[2]) # accessing a element using # negative indexing print('Accessing element using negative indexing') # print the last element of list print(List[-1]) # print the third last element of list print(List[-3])> Výstup
List containing multiple values: ['Geeks', 'For', 'Geeks'] Multi-Dimensional List: [['Geeks', 'For'], ['Geeks']] Accessing element from the list Geeks Geeks Accessing element using negative indexing Geeks Geeks>
Tuple
Pythonské n-tice jsou podobné seznamům, ale n-tice jsou neměnný v přírodě, tj. jakmile je jednou vytvořen, nemůže být modifikován. Stejně jako seznam může i Tuple obsahovat prvky různých typů.
V Pythonu se n-tice vytvářejí umístěním posloupnosti hodnot oddělených „čárkou“ s nebo bez použití závorek pro seskupování posloupnosti dat.
Poznámka: Pro vytvoření n-tice jednoho prvku musí být koncová čárka. Například (8,) vytvoří n-tici obsahující 8 jako prvek.
Příklad: Python Tuple Operations
Python3 # Creating a Tuple with # the use of Strings Tuple = ('Geeks', 'For') print('
Tuple with the use of String: ') print(Tuple) # Creating a Tuple with # the use of list list1 = [1, 2, 4, 5, 6] print('
Tuple using List: ') Tuple = tuple(list1) # Accessing element using indexing print('First element of tuple') print(Tuple[0]) # Accessing element from last # negative indexing print('
Last element of tuple') print(Tuple[-1]) print('
Third last element of tuple') print(Tuple[-3])> Výstup
Tuple with the use of String: ('Geeks', 'For') Tuple using List: First element of tuple 1 Last element of tuple 6 Third last element of tuple 4> Soubor
Sada Python je proměnlivý soubor dat, který neumožňuje žádnou duplikaci. Sady se v zásadě používají k testování členství a eliminaci duplicitních záznamů. Datová struktura použitá v tomto je hashování, populární technika k provádění vkládání, mazání a procházení v průměru v O(1).
Pokud je na stejné pozici indexu přítomno více hodnot, pak se hodnota připojí k této pozici indexu a vytvoří se propojený seznam. V sadách CPythonu jsou implementovány pomocí slovníku s fiktivními proměnnými, kde klíčové bytosti nastavují členové s větší optimalizací na časovou složitost.
Implementace sady:

Sady s mnoha operacemi v jedné hashTable:

Příklad: Operace sady Python
Python3 # Creating a Set with # a mixed type of values # (Having numbers and strings) Set = set([1, 2, 'Geeks', 4, 'For', 6, 'Geeks']) print('
Set with the use of Mixed Values') print(Set) # Accessing element using # for loop print('
Elements of set: ') for i in Set: print(i, end =' ') print() # Checking the element # using in keyword print('Geeks' in Set)> Výstup
Set with the use of Mixed Values {1, 2, 4, 6, 'For', 'Geeks'} Elements of set: 1 2 4 6 For Geeks True> Mražené sady
Zmrazené sady v Pythonu jsou neměnné objekty, které podporují pouze metody a operátory, které vytvářejí výsledek, aniž by ovlivnily zmrazenou sadu nebo sady, na které jsou aplikovány. Zatímco prvky sady lze kdykoli upravit, prvky zmrazené sady zůstanou po vytvoření stejné.
Příklad: sada Python Frozen
Python3 # Same as {'a', 'b','c'} normal_set = set(['a', 'b','c']) print('Normal Set') print(normal_set) # A frozen set frozen_set = frozenset(['e', 'f', 'g']) print('
Frozen Set') print(frozen_set) # Uncommenting below line would cause error as # we are trying to add element to a frozen set # frozen_set.add('h')> Výstup
Normal Set {'a', 'b', 'c'} Frozen Set frozenset({'f', 'g', 'e'})> Tětiva
Python řetězce je neměnné pole bajtů představujících znaky Unicode. Python nemá datový typ znak, jeden znak je prostě řetězec o délce 1.
Poznámka: Protože řetězce jsou neměnné, úprava řetězce povede k vytvoření nové kopie.
Příklad: Operace s řetězci Pythonu
Python3 String = 'Welcome to GeeksForGeeks' print('Creating String: ') print(String) # Printing First character print('
First character of String is: ') print(String[0]) # Printing Last character print('
Last character of String is: ') print(String[-1])> Výstup
Creating String: Welcome to GeeksForGeeks First character of String is: W Last character of String is: s>
Slovník
Pythonský slovník je neuspořádaná kolekce dat, která ukládá data ve formátu páru klíč:hodnota. Je to jako hashovací tabulky v jakémkoli jiném jazyce s časovou složitostí O(1). Indexování Python Dictionary se provádí pomocí klíčů. Jsou libovolného hašovatelného typu, tj. objekt, který se nikdy nemůže změnit jako řetězce, čísla, n-tice atd. Slovník můžeme vytvořit pomocí složených závorek ({}) nebo porozumění slovníku.
Příklad: Operace slovníku Python
Python3 # Creating a Dictionary Dict = {'Name': 'Geeks', 1: [1, 2, 3, 4]} print('Creating Dictionary: ') print(Dict) # accessing a element using key print('Accessing a element using key:') print(Dict['Name']) # accessing a element using get() # method print('Accessing a element using get:') print(Dict.get(1)) # creation using Dictionary comprehension myDict = {x: x**2 for x in [1,2,3,4,5]} print(myDict)> Výstup
Creating Dictionary: {'Name': 'Geeks', 1: [1, 2, 3, 4]} Accessing a element using key: Geeks Accessing a element using get: [1, 2, 3, 4] {1: 1, 2: 4, 3: 9, 4: 16, 5: 25}> Matice
Matice je 2D pole, kde má každý prvek striktně stejnou velikost. K vytvoření matice použijeme Balíček NumPy .
Příklad: Python NumPy Matrix Operations
Python3 import numpy as np a = np.array([[1,2,3,4],[4,55,1,2], [8,3,20,19],[11,2,22,21]]) m = np.reshape(a,(4, 4)) print(m) # Accessing element print('
Accessing Elements') print(a[1]) print(a[2][0]) # Adding Element m = np.append(m,[[1, 15,13,11]],0) print('
Adding Element') print(m) # Deleting Element m = np.delete(m,[1],0) print('
Deleting Element') print(m)> Výstup
[[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21]] Accessing Elements [ 4 55 1 2] 8 Adding Element [[ 1 2 3 4] [ 4 55 1 2] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]] Deleting Element [[ 1 2 3 4] [ 8 3 20 19] [11 2 22 21] [ 1 15 13 11]]>
Bytearray
Python Bytearray poskytuje proměnlivou sekvenci celých čísel v rozsahu 0 <= x < 256.
substring_index v sql
Příklad: Operace Python Bytearray
Python3 # Creating bytearray a = bytearray((12, 8, 25, 2)) print('Creating Bytearray:') print(a) # accessing elements print('
Accessing Elements:', a[1]) # modifying elements a[1] = 3 print('
After Modifying:') print(a) # Appending elements a.append(30) print('
After Adding Elements:') print(a)> Výstup
Creating Bytearray: bytearray(b'x0cx08x19x02') Accessing Elements: 8 After Modifying: bytearray(b'x0cx03x19x02') After Adding Elements: bytearray(b'x0cx03x19x02x1e')>
Spojový seznam
A spojový seznam je lineární datová struktura, ve které nejsou prvky uloženy na souvislých paměťových místech. Prvky v propojeném seznamu jsou propojeny pomocí ukazatelů, jak je znázorněno na obrázku níže:

Propojený seznam je reprezentován ukazatelem na první uzel propojeného seznamu. První uzel se nazývá hlava. Pokud je propojený seznam prázdný, pak je hodnota hlavičky NULL. Každý uzel v seznamu se skládá alespoň ze dvou částí:
- Data
- Ukazatel (nebo odkaz) na další uzel
Příklad: Definování propojeného seznamu v Pythonu
Python3 # Node class class Node: # Function to initialize the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize # next as null # Linked List class class LinkedList: # Function to initialize the Linked # List object def __init__(self): self.head = None>
Vytvořme jednoduchý propojený seznam se 3 uzly.
Python3 # A simple Python program to introduce a linked list # Node class class Node: # Function to initialise the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize next as null # Linked List class contains a Node object class LinkedList: # Function to initialize head def __init__(self): self.head = None # Code execution starts here if __name__=='__main__': # Start with the empty list llist = LinkedList() llist.head = Node(1) second = Node(2) third = Node(3) ''' Three nodes have been created. We have references to these three blocks as head, second and third llist.head second third | | | | | | +----+------+ +----+------+ +----+------+ | 1 | None | | 2 | None | | 3 | None | +----+------+ +----+------+ +----+------+ ''' llist.head.next = second; # Link first node with second ''' Now next of first Node refers to second. So they both are linked. llist.head second third | | | | | | +----+------+ +----+------+ +----+------+ | 1 | o-------->| 2 | null | | 3 | null | +----+------+ +----+------+ +----+------+ ''' druhý.další = třetí ; # Propojit druhý uzel s třetím uzlem ''' Nyní další z druhého uzlu odkazuje na třetí. Všechny tři uzly jsou tedy propojeny. llist.hlava druhá třetina | | | | | | +----+------+ +----+------+ +----+------+ | 1 | o-------->| 2 | o-------->| 3 | null | +----+------+ +----+------+ +----+------+ '''>
Procházení propojeného seznamu
V předchozím programu jsme vytvořili jednoduchý propojený seznam se třemi uzly. Projdeme vytvořený seznam a vytiskneme data každého uzlu. Pro procházení si napišme obecnou funkci printList(), která vytiskne libovolný daný seznam.
Python3 # A simple Python program for traversal of a linked list # Node class class Node: # Function to initialise the node object def __init__(self, data): self.data = data # Assign data self.next = None # Initialize next as null # Linked List class contains a Node object class LinkedList: # Function to initialize head def __init__(self): self.head = None # This function prints contents of linked list # starting from head def printList(self): temp = self.head while (temp): print (temp.data) temp = temp.next # Code execution starts here if __name__=='__main__': # Start with the empty list llist = LinkedList() llist.head = Node(1) second = Node(2) third = Node(3) llist.head.next = second; # Link first node with second second.next = third; # Link second node with the third node llist.printList()>
Výstup
1 2 3>
Další články na Linked List
- Vložení propojeného seznamu
- Smazání propojeného seznamu (smazání daného klíče)
- Smazání propojeného seznamu (smazání klíče na dané pozici)
- Najít délku propojeného seznamu (iterativní a rekurzivní)
- Hledání prvku v propojeném seznamu (iterativní a rekurzivní)
- N-tý uzel z konce propojeného seznamu
- Obrátit propojený seznam

Funkce spojené se zásobníkem jsou:
- empty() – Vrací, zda je zásobník prázdný – Časová složitost: O(1)
- velikost () – Vrátí velikost zásobníku – časová složitost: O(1)
- horní() - Vrátí odkaz na nejvyšší prvek zásobníku – Časová složitost: O(1)
- tlačit (a) – Vloží prvek „a“ do horní části zásobníku – Časová složitost: O(1)
- pop() – Odstraní nejvyšší prvek zásobníku – Časová složitost: O(1)
stack = [] # append() function to push # element in the stack stack.append('g') stack.append('f') stack.append('g') print('Initial stack') print(stack) # pop() function to pop # element from stack in # LIFO order print('
Elements popped from stack:') print(stack.pop()) print(stack.pop()) print(stack.pop()) print('
Stack after elements are popped:') print(stack) # uncommenting print(stack.pop()) # will cause an IndexError # as the stack is now empty> Výstup
Initial stack ['g', 'f', 'g'] Elements popped from stack: g f g Stack after elements are popped: []>
Další články na Stack
- Převod Infixu na Postfix pomocí Stack
- Konverze předpony na infix
- Konverze prefixu na Postfix
- Konverze postfixu na prefix
- Postfix na Infix
- Zkontrolujte vyvážené závorky ve výrazu
- Vyhodnocení Postfixového výrazu
Jako zásobník, fronta je lineární datová struktura, která ukládá položky způsobem First In First Out (FIFO). U fronty je jako první odstraněna nejméně nedávno přidaná položka. Dobrým příkladem fronty je jakákoli fronta spotřebitelů pro zdroj, kde je jako první obsluhován spotřebitel, který přišel jako první.

Operace spojené s frontou jsou:
- Zařadit do fronty: Přidá položku do fronty. Pokud je fronta plná, jedná se o podmínku přetečení – časová složitost: O(1)
- Podle toho: Odebere položku z fronty. Položky jsou vyskakovány ve stejném pořadí, v jakém byly vytlačovány. Pokud je fronta prázdná, jedná se o podmínku podtečení – časová složitost: O(1)
- Přední: Získejte přední položku z fronty – Časová složitost: O(1)
- Zadní: Získejte poslední položku z fronty – Časová složitost: O(1)
# Initializing a queue queue = [] # Adding elements to the queue queue.append('g') queue.append('f') queue.append('g') print('Initial queue') print(queue) # Removing elements from the queue print('
Elements dequeued from queue') print(queue.pop(0)) print(queue.pop(0)) print(queue.pop(0)) print('
Queue after removing elements') print(queue) # Uncommenting print(queue.pop(0)) # will raise and IndexError # as the queue is now empty> Výstup
Initial queue ['g', 'f', 'g'] Elements dequeued from queue g f g Queue after removing elements []>
Další články o Queue
- Implementujte frontu pomocí zásobníků
- Implementujte Stack pomocí front
- Implementujte zásobník pomocí jedné fronty
Prioritní fronta
Prioritní fronty jsou abstraktní datové struktury, kde každá data/hodnota ve frontě má určitou prioritu. Například u leteckých společností dorazí zavazadla s názvem Business nebo First-class dříve než ostatní. Prioritní fronta je rozšířením fronty s následujícími vlastnostmi.
- Prvek s vysokou prioritou je vyřazen z fronty před prvkem s nízkou prioritou.
- Pokud mají dva prvky stejnou prioritu, jsou obsluhovány podle pořadí ve frontě.
# A simple implementation of Priority Queue # using Queue. class PriorityQueue(object): def __init__(self): self.queue = [] def __str__(self): return ' '.join([str(i) for i in self.queue]) # for checking if the queue is empty def isEmpty(self): return len(self.queue) == 0 # for inserting an element in the queue def insert(self, data): self.queue.append(data) # for popping an element based on Priority def delete(self): try: max = 0 for i in range(len(self.queue)): if self.queue[i]>self.queue[max]: max = i item = self.queue[max] del self.queue[max] návratová položka kromě IndexError: print() exit() if __name__ == '__main__': myQueue = PriorityQueue( ) myQueue.insert(12) myQueue.insert(1) myQueue.insert(14) myQueue.insert(7) print(myQueue) zatímco ne myQueue.isEmpty(): print(myQueue.delete())>
Výstup
12 1 14 7 14 12 7 1>
Halda
modul heapq v Pythonu poskytuje datovou strukturu haldy, která se používá hlavně k reprezentaci prioritní fronty. Vlastností této datové struktury je to, že vždy dává nejmenší prvek (min haldu), kdykoli je prvek vyskakován. Kdykoli jsou prvky zatlačeny nebo vyskočeny, struktura haldy je zachována. Prvek haldy[0] také pokaždé vrátí nejmenší prvek. Podporuje extrakci a vložení nejmenšího prvku v časech O(log n).
Obecně mohou být haldy dvou typů:
- Max-Heap: V Max-Heap musí být klíč přítomný v kořenovém uzlu největší mezi klíči přítomnými u všech jeho potomků. Stejná vlastnost musí být rekurzivně pravdivá pro všechny podstromy v tomto binárním stromu.
- Min-Hromad: V Min-Heap musí být klíč přítomný v kořenovém uzlu minimální mezi klíči přítomnými u všech jeho potomků. Stejná vlastnost musí být rekurzivně pravdivá pro všechny podstromy v tomto binárním stromu.

# importing 'heapq' to implement heap queue import heapq # initializing list li = [5, 7, 9, 1, 3] # using heapify to convert list into heap heapq.heapify(li) # printing created heap print ('The created heap is : ',end='') print (list(li)) # using heappush() to push elements into heap # pushes 4 heapq.heappush(li,4) # printing modified heap print ('The modified heap after push is : ',end='') print (list(li)) # using heappop() to pop smallest element print ('The popped and smallest element is : ',end='') print (heapq.heappop(li))> Výstup
The created heap is : [1, 3, 9, 7, 5] The modified heap after push is : [1, 3, 4, 7, 5, 9] The popped and smallest element is : 1>
Další články o haldě
- Binární halda
- K’th největší prvek v poli
- K’th nejmenší/největší prvek v netříděném poli
- Seřadit téměř seřazené pole
- K-té souvislé dílčí pole s největším součtem
- Minimální součet dvou čísel vytvořených z číslic pole
Strom je hierarchická datová struktura, která vypadá jako na obrázku níže –
tree ---- j <-- root / f k / a h z <-- leaves>
Nejvyšší uzel stromu se nazývá kořen, zatímco nejspodnější uzly nebo uzly bez potomků se nazývají listové uzly. Uzly, které jsou přímo pod uzlem, se nazývají jeho potomci a uzly, které jsou přímo nad něčím, se nazývají jeho rodiče.
A binární strom je strom, jehož prvky mohou mít téměř dvě děti. Protože každý prvek v binárním stromě může mít pouze 2 potomky, obvykle je pojmenováváme jako levé a pravé potomky. Uzel binárního stromu obsahuje následující části.
- Data
- Ukazatel na levé dítě
- Ukazatel na správné dítě
Příklad: Definování třídy uzlu
Python3 # A Python class that represents an individual node # in a Binary Tree class Node: def __init__(self,key): self.left = None self.right = None self.val = key>
Nyní vytvoříme strom se 4 uzly v Pythonu. Předpokládejme, že stromová struktura vypadá níže –
tree ---- 1 <-- root / 2 3 / 4>
Příklad: Přidání dat do stromu
Python3 # Python program to introduce Binary Tree # A class that represents an individual node in a # Binary Tree class Node: def __init__(self,key): self.left = None self.right = None self.val = key # create root root = Node(1) ''' following is the tree after above statement 1 / None None''' root.left = Node(2); root.right = Node(3); ''' 2 and 3 become left and right children of 1 1 / 2 3 / / None None None None''' root.left.left = Node(4); '''4 becomes left child of 2 1 / 2 3 / / 4 None None None / None None'''>
Procházení stromů
Stromy lze přecházet v různých cestách. Následují obecně používané způsoby procházení stromů. Podívejme se na níže uvedený strom -
tree ---- 1 <-- root / 2 3 / 4 5>
První procházení hloubky:
- Pořadí (vlevo, kořen, vpravo): 4 2 5 1 3
- Předobjednávka (kořen, vlevo, vpravo) : 1 2 4 5 3
- Postorder (levý, pravý, kořenový) : 4 5 2 3 1
Algoritmus Inorder (strom)
- Projděte levý podstrom, tj. zavolejte Inorder (levý podstrom)
- Navštivte kořen.
- Projděte pravý podstrom, tj. zavolejte Inorder (pravý podstrom)
Předobjednávka algoritmu (strom)
- Navštivte kořen.
- Projděte levý podstrom, tj. zavolejte Preorder (levý podstrom)
- Projděte pravý podstrom, tj. zavolejte Preorder (pravý podstrom)
Algoritmus Poštovní poukázka (strom)
- Projděte levý podstrom, tj. zavolejte Postorder (levý podstrom)
- Projděte pravý podstrom, tj. zavolejte Postorder (pravý podstrom)
- Navštivte kořen.
# Python program to for tree traversals # A class that represents an individual node in a # Binary Tree class Node: def __init__(self, key): self.left = None self.right = None self.val = key # A function to do inorder tree traversal def printInorder(root): if root: # First recur on left child printInorder(root.left) # then print the data of node print(root.val), # now recur on right child printInorder(root.right) # A function to do postorder tree traversal def printPostorder(root): if root: # First recur on left child printPostorder(root.left) # the recur on right child printPostorder(root.right) # now print the data of node print(root.val), # A function to do preorder tree traversal def printPreorder(root): if root: # First print the data of node print(root.val), # Then recur on left child printPreorder(root.left) # Finally recur on right child printPreorder(root.right) # Driver code root = Node(1) root.left = Node(2) root.right = Node(3) root.left.left = Node(4) root.left.right = Node(5) print('Preorder traversal of binary tree is') printPreorder(root) print('
Inorder traversal of binary tree is') printInorder(root) print('
Postorder traversal of binary tree is') printPostorder(root)> Výstup
Preorder traversal of binary tree is 1 2 4 5 3 Inorder traversal of binary tree is 4 2 5 1 3 Postorder traversal of binary tree is 4 5 2 3 1>
Časová složitost – O(n)
Procházení pořadím do šířky nebo úrovně
Průchod úrovňovým příkazem stromu je pro strom projížděním napřed na šířku. Procházení pořadí úrovní výše uvedeného stromu je 1 2 3 4 5.
Pro každý uzel je nejprve navštíven uzel a poté jsou jeho podřízené uzly umístěny do fronty FIFO. Níže je algoritmus pro totéž -
- Vytvořte prázdnou frontu q
- temp_node = root /*začít od root*/
- Smyčka, zatímco temp_node není NULL
- vytisknout temp_node->data.
- Zařaďte potomky temp_node (nejprve levé potom pravé potomky) do q
- Seřadit uzel z q
# Python program to print level # order traversal using Queue # A node structure class Node: # A utility function to create a new node def __init__(self ,key): self.data = key self.left = None self.right = None # Iterative Method to print the # height of a binary tree def printLevelOrder(root): # Base Case if root is None: return # Create an empty queue # for level order traversal queue = [] # Enqueue Root and initialize height queue.append(root) while(len(queue)>0): # Vytisknout přední část fronty a # odstranit ji z fronty tisknout (queue[0].data) node = queue.pop(0) # Zařadit do fronty levého potomka, pokud node.left není Žádný: queue.append(node.left ) # Zařadit do fronty pravého potomka, pokud node.right není Žádný: queue.append(node.right) # Program ovladače k otestování výše uvedené funkce root = Node(1) root.left = Node(2) root.right = Node(3) root.left.left = Node(4) root.left.right = Node(5) tisk ('Přechod pořadí úrovní binárním stromem je -') printLevelOrder(kořen)> Výstup
Level Order Traversal of binary tree is - 1 2 3 4 5>
Časová složitost: O(n)
Další články na téma Binární strom
- Vložení do binárního stromu
- Odstranění v binárním stromu
- Procházení stromu v řádu bez rekurze
- Inorder Tree Traversal bez rekurze a bez zásobníku!
- Tisk Postorder traversal z daných Inorder a Preorder traversals
- Najděte postorder traversal BST z preorder traversal
- Levý podstrom uzlu obsahuje pouze uzly s klíči menšími, než je klíč uzlu.
- Pravý podstrom uzlu obsahuje pouze uzly s klíči většími, než je klíč uzlu.
- Levý a pravý podstrom musí být také binárním vyhledávacím stromem.

stáhněte si youtube pomocí vlc
Výše uvedené vlastnosti stromu binárního vyhledávání poskytují řazení mezi klíči, takže operace jako vyhledávání, minimum a maximum lze provádět rychle. Pokud neexistuje pořadí, pak možná budeme muset porovnat každý klíč, abychom daný klíč našli.
Vyhledávací prvek
- Začněte od kořene.
- Porovnejte hledaný prvek s rootem, pokud je menší než root, pak recurse pro levý, jinak recurse pro pravý.
- Pokud je prvek k hledání kdekoli nalezen, vraťte hodnotu true, jinak vraťte hodnotu false.
# A utility function to search a given key in BST def search(root,key): # Base Cases: root is null or key is present at root if root is None or root.val == key: return root # Key is greater than root's key if root.val < key: return search(root.right,key) # Key is smaller than root's key return search(root.left,key)>
Vložení klíče
- Začněte od kořene.
- Porovnejte vkládaný prvek s rootem, pokud je menší než root, pak recurse pro levý, jinak recurse pro pravý.
- Po dosažení konce stačí vložit tento uzel vlevo (pokud je menší než aktuální), jinak vpravo.
# Python program to demonstrate # insert operation in binary search tree # A utility class that represents # an individual node in a BST class Node: def __init__(self, key): self.left = None self.right = None self.val = key # A utility function to insert # a new node with the given key def insert(root, key): if root is None: return Node(key) else: if root.val == key: return root elif root.val < key: root.right = insert(root.right, key) else: root.left = insert(root.left, key) return root # A utility function to do inorder tree traversal def inorder(root): if root: inorder(root.left) print(root.val) inorder(root.right) # Driver program to test the above functions # Let us create the following BST # 50 # / # 30 70 # / / # 20 40 60 80 r = Node(50) r = insert(r, 30) r = insert(r, 20) r = insert(r, 40) r = insert(r, 70) r = insert(r, 60) r = insert(r, 80) # Print inorder traversal of the BST inorder(r)>
Výstup
20 30 40 50 60 70 80>
Další články o binárním vyhledávacím stromu
- Binární vyhledávací strom – Delete Key
- Sestavte BST z daného průchodu předobjednávky | Sada 1
- Konverze binárního stromu na binární vyhledávací strom
- Najděte uzel s minimální hodnotou ve stromu binárního vyhledávání
- Program pro kontrolu, zda je binární strom BST nebo ne
A graf je nelineární datová struktura sestávající z uzlů a hran. Uzly jsou někdy také označovány jako vrcholy a hrany jsou čáry nebo oblouky, které spojují libovolné dva uzly v grafu. Formálněji lze graf definovat jako graf skládající se z konečné množiny vrcholů (nebo uzlů) a množiny hran, které spojují dvojici uzlů.

Ve výše uvedeném grafu je množina vrcholů V = {0,1,2,3,4} a množina hran E = {01, 12, 23, 34, 04, 14, 13}. Následující dva jsou nejběžněji používané reprezentace grafu.
- Matice sousedství
- Seznam sousedství
Matice sousedství
Matice sousedství je 2D pole o velikosti V x V, kde V je počet vrcholů v grafu. Nechť je 2D pole adj[][], slot adj[i][j] = 1 znamená, že od vrcholu i k vrcholu j existuje hrana. Matice sousedství pro neorientovaný graf je vždy symetrická. Matice sousedství se také používá k reprezentaci vážených grafů. Jestliže adj[i][j] = w, pak z vrcholu i do vrcholu j existuje hrana s váhou w.
Python3 # A simple representation of graph using Adjacency Matrix class Graph: def __init__(self,numvertex): self.adjMatrix = [[-1]*numvertex for x in range(numvertex)] self.numvertex = numvertex self.vertices = {} self.verticeslist =[0]*numvertex def set_vertex(self,vtx,id): if 0<=vtx<=self.numvertex: self.vertices[id] = vtx self.verticeslist[vtx] = id def set_edge(self,frm,to,cost=0): frm = self.vertices[frm] to = self.vertices[to] self.adjMatrix[frm][to] = cost # for directed graph do not add this self.adjMatrix[to][frm] = cost def get_vertex(self): return self.verticeslist def get_edges(self): edges=[] for i in range (self.numvertex): for j in range (self.numvertex): if (self.adjMatrix[i][j]!=-1): edges.append((self.verticeslist[i],self.verticeslist[j],self.adjMatrix[i][j])) return edges def get_matrix(self): return self.adjMatrix G =Graph(6) G.set_vertex(0,'a') G.set_vertex(1,'b') G.set_vertex(2,'c') G.set_vertex(3,'d') G.set_vertex(4,'e') G.set_vertex(5,'f') G.set_edge('a','e',10) G.set_edge('a','c',20) G.set_edge('c','b',30) G.set_edge('b','e',40) G.set_edge('e','d',50) G.set_edge('f','e',60) print('Vertices of Graph') print(G.get_vertex()) print('Edges of Graph') print(G.get_edges()) print('Adjacency Matrix of Graph') print(G.get_matrix())> Výstup
Vrcholy grafu
['a B c d e f']
Okraje grafu
[('a', 'c', 20), ('a', 'e', 10), ('b', 'c', 30), ('b', 'e', 40), ( 'c', 'a', 20), ('c', 'b', 30), ('d', 'e', 50), ('e', 'a', 10), ('e ', 'b', 40), ('e', 'd', 50), ('e', 'f', 60), ('f', 'e', 60)]
Matice sousedství grafu
[[-1, -1, 20, -1, 10, -1], [-1, -1, 30, -1, 40, -1], [20, 30, -1, -1, -1 , -1], [-1, -1, -1, -1, 50, -1], [10, 40, -1, 50, -1, 60], [-1, -1, -1, -1, 60, -1]]
Seznam sousedství
Používá se řada seznamů. Velikost pole se rovná počtu vrcholů. Nechť pole je pole[]. Vstupní pole[i] představuje seznam vrcholů sousedících s i-tým vrcholem. Tuto reprezentaci lze také použít k reprezentaci váženého grafu. Váhy hran mohou být reprezentovány jako seznamy dvojic. Následuje znázornění seznamu sousedství výše uvedeného grafu.

# A class to represent the adjacency list of the node class AdjNode: def __init__(self, data): self.vertex = data self.next = None # A class to represent a graph. A graph # is the list of the adjacency lists. # Size of the array will be the no. of the # vertices 'V' class Graph: def __init__(self, vertices): self.V = vertices self.graph = [None] * self.V # Function to add an edge in an undirected graph def add_edge(self, src, dest): # Adding the node to the source node node = AdjNode(dest) node.next = self.graph[src] self.graph[src] = node # Adding the source node to the destination as # it is the undirected graph node = AdjNode(src) node.next = self.graph[dest] self.graph[dest] = node # Function to print the graph def print_graph(self): for i in range(self.V): print('Adjacency list of vertex {}
head'.format(i), end='') temp = self.graph[i] while temp: print(' ->{}'.format(temp.vertex), end='') temp = temp.next print('
') # Program ovladače pro výše uvedenou třídu grafu if __name__ == '__main__' : V = 5 graf = Graph(V) graph.add_edge(0, 1) graph.add_edge(0, 4) graph.add_edge(1, 2) graph.add_edge(1, 3) graph.add_edge(1, 4) graph.add_edge(2, 3) graph.add_edge(3, 4) graph.print_graph()> Výstup
Adjacency list of vertex 0 head ->4 -> 1 Seznam sousedství hlavy 1 hlavy -> 4 -> 3 -> 2 -> 0 Seznam sousedství hlavy 2 -> 3 -> 1 Seznam sousedství hlavy 3 -> 4 -> 2 -> 1 seznam vertex 4 head -> 3 -> 1 -> 0>
Procházení grafu
Breadth-First Search nebo BFS
Přechod do šířky protože graf je podobný přechodu stromu do šířky. Jediný háček je v tom, že na rozdíl od stromů mohou grafy obsahovat cykly, takže se můžeme znovu dostat do stejného uzlu. Abychom se vyhnuli zpracování uzlu více než jednou, používáme booleovské navštívené pole. Pro jednoduchost se předpokládá, že všechny vrcholy jsou dosažitelné z počátečního vrcholu.
Například v následujícím grafu začneme procházení od vrcholu 2. Když dojdeme k vrcholu 0, hledáme všechny jeho sousední vrcholy. 2 je také sousedním vrcholem 0. Pokud neoznačíme navštívené vrcholy, pak se 2 zpracuje znovu a stane se neukončujícím procesem. Průchod na první šířku následujícího grafu je 2, 0, 3, 1.

# Python3 Program to print BFS traversal # from a given source vertex. BFS(int s) # traverses vertices reachable from s. from collections import defaultdict # This class represents a directed graph # using adjacency list representation class Graph: # Constructor def __init__(self): # default dictionary to store graph self.graph = defaultdict(list) # function to add an edge to graph def addEdge(self,u,v): self.graph[u].append(v) # Function to print a BFS of graph def BFS(self, s): # Mark all the vertices as not visited visited = [False] * (max(self.graph) + 1) # Create a queue for BFS queue = [] # Mark the source node as # visited and enqueue it queue.append(s) visited[s] = True while queue: # Dequeue a vertex from # queue and print it s = queue.pop(0) print (s, end = ' ') # Get all adjacent vertices of the # dequeued vertex s. If a adjacent # has not been visited, then mark it # visited and enqueue it for i in self.graph[s]: if visited[i] == False: queue.append(i) visited[i] = True # Driver code # Create a graph given in # the above diagram g = Graph() g.addEdge(0, 1) g.addEdge(0, 2) g.addEdge(1, 2) g.addEdge(2, 0) g.addEdge(2, 3) g.addEdge(3, 3) print ('Following is Breadth First Traversal' ' (starting from vertex 2)') g.BFS(2)> Výstup
Following is Breadth First Traversal (starting from vertex 2) 2 0 3 1>
Časová složitost: O(V+E) kde V je počet vrcholů v grafu a E je počet hran v grafu.
Depth First Search nebo DFS
Hloubka první průchod protože graf je podobný jako Hloubka prvního průchodu stromu. Jediný háček je, že na rozdíl od stromů mohou grafy obsahovat cykly, uzel lze navštívit dvakrát. Chcete-li se vyhnout zpracování uzlu více než jednou, použijte booleovské navštívené pole.
Algoritmus:
- Vytvořte rekurzivní funkci, která vezme index uzlu a navštívené pole.
- Označte aktuální uzel jako navštívený a vytiskněte uzel.
- Projděte všechny sousední a neoznačené uzly a zavolejte rekurzivní funkci s indexem sousedního uzlu.
# Python3 program to print DFS traversal # from a given graph from collections import defaultdict # This class represents a directed graph using # adjacency list representation class Graph: # Constructor def __init__(self): # default dictionary to store graph self.graph = defaultdict(list) # function to add an edge to graph def addEdge(self, u, v): self.graph[u].append(v) # A function used by DFS def DFSUtil(self, v, visited): # Mark the current node as visited # and print it visited.add(v) print(v, end=' ') # Recur for all the vertices # adjacent to this vertex for neighbour in self.graph[v]: if neighbour not in visited: self.DFSUtil(neighbour, visited) # The function to do DFS traversal. It uses # recursive DFSUtil() def DFS(self, v): # Create a set to store visited vertices visited = set() # Call the recursive helper function # to print DFS traversal self.DFSUtil(v, visited) # Driver code # Create a graph given # in the above diagram g = Graph() g.addEdge(0, 1) g.addEdge(0, 2) g.addEdge(1, 2) g.addEdge(2, 0) g.addEdge(2, 3) g.addEdge(3, 3) print('Following is DFS from (starting from vertex 2)') g.DFS(2)> Výstup
Following is DFS from (starting from vertex 2) 2 0 1 3>
Další články o grafu
- Reprezentace grafů pomocí sady a hash
- Najděte Mother Vertex v grafu
- Iterativní hloubka první hledání
- Spočítejte počet uzlů na dané úrovni ve stromu pomocí BFS
- Spočítejte všechny možné cesty mezi dvěma vrcholy
Proces, ve kterém se funkce přímo nebo nepřímo volá, se nazývá rekurze a odpovídající funkce se nazývá a rekurzivní funkce . Pomocí rekurzivních algoritmů lze některé problémy vyřešit poměrně snadno. Příklady takových problémů jsou Towers of Hanoi (TOH), Inorder/Preorder/Postorder Tree Traversals, DFS of Graph atd.
Jaká je základní podmínka v rekurzi?
V rekurzivním programu je zajištěno řešení základního případu a řešení většího problému je vyjádřeno pomocí menších problémů.
def fact(n): # base case if (n <= 1) return 1 else return n*fact(n-1)>
Ve výše uvedeném příkladu je definován základní případ pro n <= 1 a větší hodnotu čísla lze řešit převodem na menší, dokud není dosaženo základního případu.
Jak je paměť přidělena různým voláním funkcí v rekurzi?
Když je jakákoli funkce volána z main(), je jí přidělena paměť na zásobníku. Rekurzivní funkce volá sama sebe, paměť pro volanou funkci je alokována nad pamětí přidělenou volající funkci a pro každé volání funkce je vytvořena jiná kopie lokálních proměnných. Když je dosaženo základního případu, funkce vrátí svou hodnotu funkci, kterou byla volána, a paměť je uvolněna a proces pokračuje.
Vezměme si příklad toho, jak funguje rekurze pomocí jednoduché funkce.
Python3 # A Python 3 program to # demonstrate working of # recursion def printFun(test): if (test < 1): return else: print(test, end=' ') printFun(test-1) # statement 2 print(test, end=' ') return # Driver Code test = 3 printFun(test)>
Výstup
3 2 1 1 2 3>
Paměťový zásobník je znázorněn na obrázku níže.
Další články o rekurzi
- Rekurze
- Rekurze v Pythonu
- Cvičné otázky pro rekurzi | Sada 1
- Cvičné otázky pro rekurzi | Sada 2
- Cvičné otázky pro rekurzi | Sada 3
- Cvičné otázky pro rekurzi | Sada 4
- Cvičné otázky pro rekurzi | Sada 5
- Cvičné otázky pro rekurzi | Sada 6
- Cvičné otázky pro rekurzi | Sada 7
>>> Více
Dynamické programování
Dynamické programování je hlavně optimalizace přes prostou rekurzi. Kdekoli vidíme rekurzivní řešení, které má opakované volání pro stejné vstupy, můžeme jej optimalizovat pomocí dynamického programování. Cílem je jednoduše uložit výsledky dílčích problémů, abychom je nemuseli v případě potřeby později znovu počítat. Tato jednoduchá optimalizace snižuje časovou složitost z exponenciální na polynomiální. Pokud například napíšeme jednoduché rekurzivní řešení pro Fibonacciho čísla, dostaneme exponenciální časovou složitost a pokud ji optimalizujeme ukládáním řešení podproblémů, časová složitost se sníží na lineární.

Tabulování vs memoizace
Existují dva různé způsoby uložení hodnot, aby bylo možné znovu použít hodnoty dílčího problému. Zde probereme dva vzorce řešení problému dynamického programování (DP):
- Tabulka: Zdola nahoru
- Memorizace: Vzhůru nohama
Tabulování
Jak sám název napovídá, začít odspoda a shromažďovat odpovědi nahoru. Pojďme diskutovat o přechodu státu.
Popišme stav našeho problému DP jako dp[x] s dp[0] jako základním stavem a dp[n] jako naším cílovým stavem. Potřebujeme tedy najít hodnotu cílového stavu, tj. dp[n].
Pokud začneme náš přechod z našeho základního stavu, tj. dp[0] a sledujeme náš vztah přechodu stavu, abychom dosáhli našeho cílového stavu dp[n], nazýváme to přístup zdola nahoru, protože je zcela jasné, že jsme zahájili náš přechod z spodní základní stav a dosáhl nejvyššího požadovaného stavu.
Proč tomu říkáme tabelační metoda?
Abychom to věděli, napíšeme nejprve nějaký kód pro výpočet faktoriálu čísla pomocí přístupu zdola nahoru. Ještě jednou, jako náš obecný postup pro řešení DP, nejprve definujeme stav. V tomto případě definujeme stav jako dp[x], kde dp[x] má najít faktoriál x.
Nyní je zcela zřejmé, že dp[x+1] = dp[x] * (x+1)
# Tabulated version to find factorial x. dp = [0]*MAXN # base case dp[0] = 1; for i in range(n+1): dp[i] = dp[i-1] * i>
Memorizace
Ještě jednou to popišme z hlediska přechodu stavu. Pokud potřebujeme najít hodnotu pro nějaký stav, řekněme dp[n] a místo toho, abychom začali od základního stavu, tj. dp[0], požádáme o odpověď od států, které mohou po přechodu stavu dosáhnout cílového stavu dp[n] vztahu, pak je to způsob DP shora dolů.
Zde začneme naši cestu od nejvyššího cílového stavu a vypočítáme její odpověď tím, že budeme počítat hodnoty stavů, které mohou dosáhnout cílového stavu, dokud nedosáhneme nejnižšího základního stavu.
Ještě jednou, pojďme napsat kód pro faktoriální problém způsobem shora dolů
# Memoized version to find factorial x. # To speed up we store the values # of calculated states # initialized to -1 dp[0]*MAXN # return fact x! def solve(x): if (x==0) return 1 if (dp[x]!=-1) return dp[x] return (dp[x] = x * solve(x-1))>

Další články o dynamickém programování
- Optimální vlastnost spodní stavby
- Vlastnost překrývajících se dílčích problémů
- Fibonacciho čísla
- Podmnožina se součtem dělitelným m
- Maximální součet rostoucí dílčí posloupnost
- Nejdelší společný podřetězec
Algoritmy vyhledávání
Lineární vyhledávání
- Začněte od levého prvku arr[] a jeden po druhém porovnejte x s každým prvkem arr[]
- Pokud se x shoduje s prvkem, vraťte index.
- Pokud x neodpovídá žádnému z prvků, vraťte -1.

# Python3 code to linearly search x in arr[]. # If x is present then return its location, # otherwise return -1 def search(arr, n, x): for i in range(0, n): if (arr[i] == x): return i return -1 # Driver Code arr = [2, 3, 4, 10, 40] x = 10 n = len(arr) # Function call result = search(arr, n, x) if(result == -1): print('Element is not present in array') else: print('Element is present at index', result)> Výstup
Element is present at index 3>
Časová složitost výše uvedeného algoritmu je O(n).
Další informace viz Lineární vyhledávání .
Binární vyhledávání
Prohledejte seřazené pole opakovaným dělením intervalu hledání na polovinu. Začněte s intervalem pokrývajícím celé pole. Pokud je hodnota vyhledávacího klíče menší než hodnota uprostřed intervalu, zúžte interval na spodní polovinu. V opačném případě jej zužte na horní polovinu. Opakovaně kontrolujte, dokud nebude hodnota nalezena nebo dokud nebude interval prázdný.

# Python3 Program for recursive binary search. # Returns index of x in arr if present, else -1 def binarySearch (arr, l, r, x): # Check base case if r>= l: mid = l + (r - l) // 2 # Pokud je prvek přítomen sám uprostřed if arr[mid] == x: return mid # Pokud je prvek menší než uprostřed, pak # může být pouze přítomen v levém dílčím poli elif arr[mid]> x: return binarySearch(arr, l, mid-1, x) # Jinak prvek může být přítomen pouze # v pravém podpole else: return binarySearch(arr, mid + 1, r, x ) else: # Prvek není v poli přítomen return -1 # Kód ovladače arr = [ 2, 3, 4, 10, 40 ] x = 10 # Výsledek volání funkce = binarySearch(arr, 0, len(arr)-1 , x) if result != -1: print ('Prvek je přítomen na indexu % d' % result) else: print ('Element není přítomen v poli')> Výstup
Element is present at index 3>
Časová složitost výše uvedeného algoritmu je O(log(n)).
vymazání mezipaměti npm
Další informace viz Binární vyhledávání .
Algoritmy řazení
Výběr Seřadit
The výběr řazení Algoritmus třídí pole opakovaným nalezením minimálního prvku (s ohledem na vzestupné pořadí) z neseřazené části a jeho umístěním na začátek. V každé iteraci řazení výběru se vybere minimální prvek (s ohledem na vzestupné pořadí) z neseřazeného podpole a přesune se do seřazeného podpole.
Vývojový diagram třídění výběru:
# Python program for implementation of Selection # Sort import sys A = [64, 25, 12, 22, 11] # Traverse through all array elements for i in range(len(A)): # Find the minimum element in remaining # unsorted array min_idx = i for j in range(i+1, len(A)): if A[min_idx]>A[j]: min_idx = j # Prohoďte nalezený minimální prvek s # prvním prvkem A[i], A[min_idx] = A[min_idx], A[i] # Kód ovladače k otestování nad tiskem ('Sorted array ') pro i v rozsahu(len(A)): print('%d' %A[i]),> Výstup
Sorted array 11 12 22 25 64>
Časová náročnost: Na2), protože existují dvě vnořené smyčky.
Pomocný prostor: O(1)
Bublinové řazení
Bublinové řazení je nejjednodušší třídicí algoritmus, který funguje tak, že opakovaně zaměňuje sousední prvky, pokud jsou ve špatném pořadí.
ilustrace :

# Python program for implementation of Bubble Sort def bubbleSort(arr): n = len(arr) # Traverse through all array elements for i in range(n): # Last i elements are already in place for j in range(0, n-i-1): # traverse the array from 0 to n-i-1 # Swap if the element found is greater # than the next element if arr[j]>arr[j+1] : arr[j], arr[j+1] = arr[j+1], arr[j] # Kód ovladače k otestování výše arr = [64, 34, 25, 12, 22, 11 , 90] bubbleSort(arr) print ('Sorted array is:') for i in range(len(arr)): print ('%d' %arr[i]),> Výstup
Sorted array is: 11 12 22 25 34 64 90>
Časová náročnost: Na2)
Řazení vkládání
Chcete-li seřadit pole velikosti n vzestupně pomocí řazení vložení :
- Iterujte z arr[1] do arr[n] přes pole.
- Porovnejte aktuální prvek (klíč) s jeho předchůdcem.
- Pokud je klíčový prvek menší než jeho předchůdce, porovnejte jej s prvky dříve. Posuňte větší prvky o jednu pozici nahoru, abyste vytvořili místo pro vyměněný prvek.
Ilustrace:

# Python program for implementation of Insertion Sort # Function to do insertion sort def insertionSort(arr): # Traverse through 1 to len(arr) for i in range(1, len(arr)): key = arr[i] # Move elements of arr[0..i-1], that are # greater than key, to one position ahead # of their current position j = i-1 while j>= 0 a klíč< arr[j] : arr[j + 1] = arr[j] j -= 1 arr[j + 1] = key # Driver code to test above arr = [12, 11, 13, 5, 6] insertionSort(arr) for i in range(len(arr)): print ('% d' % arr[i])> Výstup
5 6 11 12 13>
Časová náročnost: Na2))
Sloučit třídění
Stejně jako QuickSort, Sloučit třídění je algoritmus rozděl a panuj. Rozdělí vstupní pole na dvě poloviny, zavolá se pro obě poloviny a poté sloučí dvě seřazené poloviny. Funkce merge() se používá pro sloučení dvou polovin. Sloučení (arr, l, m, r) je klíčový proces, který předpokládá, že arr[l..m] a arr[m+1..r] jsou setříděny a sloučí dvě seřazená dílčí pole do jednoho.
MergeSort(arr[], l, r) If r>l 1. Najděte prostřední bod pro rozdělení pole na dvě poloviny: middle m = l+ (r-l)/2 2. Volejte mergeSort pro první polovinu: Volejte mergeSort(arr, l, m) 3. Volejte mergeSort pro druhou polovinu: Volejte mergeSort(arr, m+1, r) 4. Sloučte dvě poloviny seřazené v kroku 2 a 3: Zavolejte merge(arr, l, m, r)>
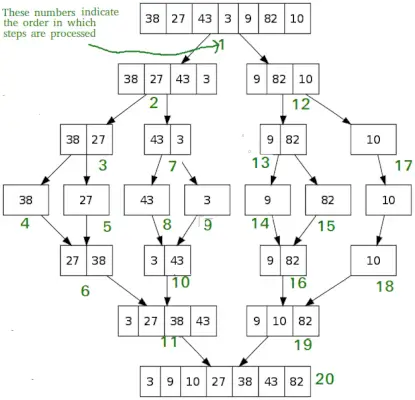
# Python program for implementation of MergeSort def mergeSort(arr): if len(arr)>1: # Nalezení středu pole mid = len(arr)//2 # Rozdělení prvků pole L = arr[:mid] # na 2 poloviny R = arr[mid:] # Seřazení první poloviny mergeSort(L) # Třídění druhé poloviny mergeSort(R) i = j = k = 0 # Kopírování dat do temp polí L[] a R[], zatímco i< len(L) and j < len(R): if L[i] < R[j]: arr[k] = L[i] i += 1 else: arr[k] = R[j] j += 1 k += 1 # Checking if any element was left while i < len(L): arr[k] = L[i] i += 1 k += 1 while j < len(R): arr[k] = R[j] j += 1 k += 1 # Code to print the list def printList(arr): for i in range(len(arr)): print(arr[i], end=' ') print() # Driver Code if __name__ == '__main__': arr = [12, 11, 13, 5, 6, 7] print('Given array is', end='
') printList(arr) mergeSort(arr) print('Sorted array is: ', end='
') printList(arr)> Výstup
Given array is 12 11 13 5 6 7 Sorted array is: 5 6 7 11 12 13>
Časová náročnost: O(n(logn))
Rychlé třídění
Jako Merge Sort, Rychlé třídění je algoritmus rozděl a panuj. Vybere prvek jako pivot a rozdělí dané pole kolem vybraného pivotu. Existuje mnoho různých verzí quickSort, které vybírají pivot různými způsoby.
Vždy vyberte první prvek jako pivot.
- Vždy vybrat poslední prvek jako pivot (implementováno níže)
- Vyberte náhodný prvek jako pivot.
- Vyberte medián jako pivot.
Klíčovým procesem v quickSortu je partition(). Cílem oddílů je, když je dáno pole a prvek x pole jako pivot, umístit x na správnou pozici v seřazeném poli a všechny menší prvky (menší než x) umístit před x a všechny větší prvky (větší než x) umístit za X. To vše by mělo být provedeno v lineárním čase.
/* low -->Počáteční index, vysoký --> Koncový index */ quickSort(arr[], low, high) { if (low { /* pi je index rozdělení, arr[pi] je nyní na správném místě */ pi = partition(arr, low, high; quickSort(arr, low, pi - 1); // Před pi quickSort(arr, pi + 1, high); 
Algoritmus rozdělení
Existuje mnoho způsobů, jak provést rozdělení, následující pseudo kód přebírá metodu uvedenou v knize CLRS. Logika je jednoduchá, začínáme od prvku zcela vlevo a sledujeme index menších (nebo rovných) prvků jako i. Pokud při procházení najdeme menší prvek, prohodíme aktuální prvek s arr[i]. Jinak aktuální prvek ignorujeme.
# Python3 implementation of QuickSort # This Function handles sorting part of quick sort # start and end points to first and last element of # an array respectively def partition(start, end, array): # Initializing pivot's index to start pivot_index = start pivot = array[pivot_index] # This loop runs till start pointer crosses # end pointer, and when it does we swap the # pivot with element on end pointer while start < end: # Increment the start pointer till it finds an # element greater than pivot while start < len(array) and array[start] <= pivot: start += 1 # Decrement the end pointer till it finds an # element less than pivot while array[end]>pivot: end -= 1 # Pokud se začátek a konec navzájem nekřížily, # prohoďte čísla na začátku a konci if(start< end): array[start], array[end] = array[end], array[start] # Swap pivot element with element on end pointer. # This puts pivot on its correct sorted place. array[end], array[pivot_index] = array[pivot_index], array[end] # Returning end pointer to divide the array into 2 return end # The main function that implements QuickSort def quick_sort(start, end, array): if (start < end): # p is partitioning index, array[p] # is at right place p = partition(start, end, array) # Sort elements before partition # and after partition quick_sort(start, p - 1, array) quick_sort(p + 1, end, array) # Driver code array = [ 10, 7, 8, 9, 1, 5 ] quick_sort(0, len(array) - 1, array) print(f'Sorted array: {array}')>
Výstup Sorted array: [1, 5, 7, 8, 9, 10]>
Časová náročnost: O(n(logn))
ShellSort
ShellSort je hlavně variantou řazení vložení. Při řazení vložení přesouváme prvky pouze o jednu pozici dopředu. Když se prvek musí posunout daleko dopředu, jde o mnoho pohybů. Myšlenka shellSort je umožnit výměnu vzdálených položek. V shellSort uděláme pole h-tříděné pro velkou hodnotu h. Stále snižujeme hodnotu h, dokud se nestane 1. Pole se nazývá h-tříděné, pokud všechny podseznamy každého hčtprvek je seřazen.
Python3 # Python3 program for implementation of Shell Sort def shellSort(arr): gap = len(arr) // 2 # initialize the gap while gap>0: i = 0 j = mezera # zkontrolujte pole zleva doprava # až do posledního možného indexu j, zatímco j< len(arr): if arr[i]>arr[j]: arr[i],arr[j] = arr[j],arr[i] i += 1 j += 1 # nyní se podíváme zpět od i-tého indexu doleva # prohodíme hodnoty, které nejsou ve správném pořadí. k = i, zatímco k - mezera> -1: if arr[k - mezera]> arr[k]: arr[k-mezera],arr[k] = arr[k],arr[k-mezera] k -= 1 mezera //= 2 # ovladač pro kontrolu kódu arr2 = [12, 34, 54, 2, 3] print('vstupní pole:',arr2) shellSort(arr2) print('tříděné pole', arr2)>
Výstup input array: [12, 34, 54, 2, 3] sorted array [2, 3, 12, 34, 54]>
Časová náročnost: Na2).
