A hashovací tabulka je datová struktura, která umožňuje rychlé vkládání, mazání a načítání dat. Funguje pomocí hašovací funkce k mapování klíče na index v poli. V tomto článku implementujeme hashovací tabulku v Pythonu pomocí samostatného řetězení pro řešení kolizí.
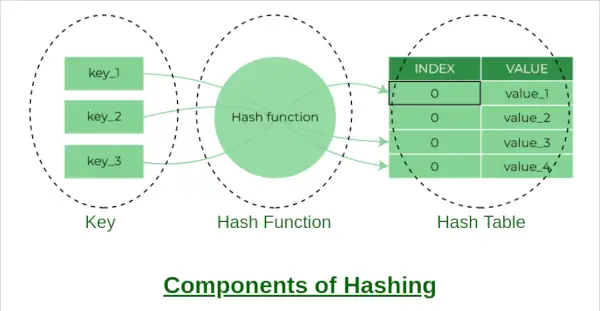
Komponenty hašování
Oddělené řetězení je technika používaná ke zpracování kolizí v hašovací tabulce. Když dva nebo více klíčů mapuje na stejný index v poli, uložíme je do propojeného seznamu v tomto indexu. To nám umožňuje uložit více hodnot do stejného indexu a stále je moci načíst pomocí jejich klíče.
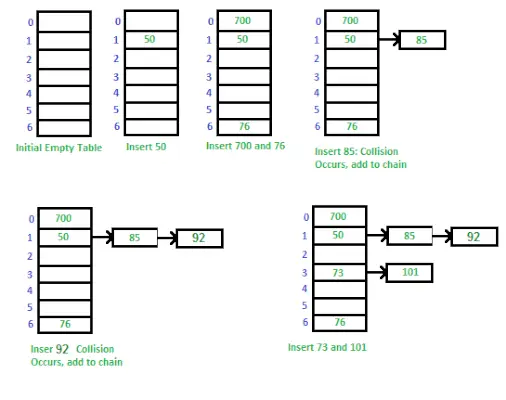
Způsob implementace tabulky hash pomocí samostatného řetězení
Způsob implementace tabulky hash pomocí samostatného řetězení:
Vytvořte dvě třídy: Uzel ' a ' HashTable '.
' Uzel Třída ‘ bude představovat uzel v propojeném seznamu. Každý uzel bude obsahovat pár klíč-hodnota a také ukazatel na další uzel v seznamu.
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> |
>
>
Třída „HashTable“ bude obsahovat pole, které bude obsahovat propojené seznamy, a také metody pro vkládání, načítání a odstraňování dat z tabulky hash.
Python3
class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> |
>
multiplexer
>
' __horký__ ‘ metoda inicializuje hashovací tabulku s danou kapacitou. Nastavuje „ kapacita ' a ' velikost ‘ proměnné a inicializuje pole na ‘Žádný’.
Další metodou je „ _hash ‘ metoda. Tato metoda vezme klíč a vrátí index v poli, kde by měl být pár klíč-hodnota uložen. Použijeme vestavěnou hašovací funkci Pythonu k hašování klíče a poté použijeme operátor modulo k získání indexu v poli.
Python3
def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> |
>
>
The 'vložit' metoda vloží do hashovací tabulky pár klíč-hodnota. Přebírá index, kam by měl být pár uložen, pomocí „ _hash ‘ metoda. Pokud v tomto indexu není žádný propojený seznam, vytvoří nový uzel s párem klíč–hodnota a nastaví jej jako hlavu seznamu. Pokud v tomto indexu existuje propojený seznam, iterujte seznamem, dokud nebude nalezen poslední uzel nebo klíč již neexistuje, a aktualizujte hodnotu, pokud klíč již existuje. Pokud klíč najde, aktualizuje hodnotu. Pokud klíč nenajde, vytvoří nový uzel a přidá jej na začátek seznamu.
Python3
def> insert(>self>, key, value):> >index>=> self>._hash(key)> >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> |
>
>
The Vyhledávání metoda načte hodnotu spojenou s daným klíčem. Nejprve získá index, kam by měl být pár klíč-hodnota uložen, pomocí _hash metoda. Poté vyhledá klíč v propojeném seznamu v tomto indexu. Pokud klíč najde, vrátí přidruženou hodnotu. Pokud klíč nenajde, vyvolá a KeyError .
Python3
repl v Javě
def> search(>self>, key):> >index>=> self>._hash(key)> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> >raise> KeyError(key)> |
>
>
The 'odstranit' metoda odstraní pár klíč-hodnota z hashovací tabulky. Nejprve získá index, kam by měl být pár uložen, pomocí ` _hash ` metoda. Poté vyhledá klíč v propojeném seznamu v tomto indexu. Pokud klíč najde, odebere uzel ze seznamu. Pokud klíč nenajde, vyvolá „ KeyError '.
Python3
def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> |
>
>
„__str__“ metoda, která vrací řetězcovou reprezentaci hash tabulky.
Python3
pružinové moduly
def> __str__(>self>):> >elements>=> []> >for> i>in> range>(>self>.capacity):> >current>=> self>.table[i]> >while> current:> >elements.append((current.key, current.value))> >current>=> current.>next> >return> str>(elements)> |
>
>
Zde je kompletní implementace třídy „HashTable“:
Python3
class> Node:> >def> __init__(>self>, key, value):> >self>.key>=> key> >self>.value>=> value> >self>.>next> => None> > > class> HashTable:> >def> __init__(>self>, capacity):> >self>.capacity>=> capacity> >self>.size>=> 0> >self>.table>=> [>None>]>*> capacity> > >def> _hash(>self>, key):> >return> hash>(key)>%> self>.capacity> > >def> insert(>self>, key, value):> >index>=> self>._hash(key)> > >if> self>.table[index]>is> None>:> >self>.table[index]>=> Node(key, value)> >self>.size>+>=> 1> >else>:> >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >current.value>=> value> >return> >current>=> current.>next> >new_node>=> Node(key, value)> >new_node.>next> => self>.table[index]> >self>.table[index]>=> new_node> >self>.size>+>=> 1> > >def> search(>self>, key):> >index>=> self>._hash(key)> > >current>=> self>.table[index]> >while> current:> >if> current.key>=>=> key:> >return> current.value> >current>=> current.>next> > >raise> KeyError(key)> > >def> remove(>self>, key):> >index>=> self>._hash(key)> > >previous>=> None> >current>=> self>.table[index]> > >while> current:> >if> current.key>=>=> key:> >if> previous:> >previous.>next> => current.>next> >else>:> >self>.table[index]>=> current.>next> >self>.size>->=> 1> >return> >previous>=> current> >current>=> current.>next> > >raise> KeyError(key)> > >def> __len__(>self>):> >return> self>.size> > >def> __contains__(>self>, key):> >try>:> >self>.search(key)> >return> True> >except> KeyError:> >return> False> > > # Driver code> if> __name__>=>=> '__main__'>:> > ># Create a hash table with> ># a capacity of 5> >ht>=> HashTable(>5>)> > ># Add some key-value pairs> ># to the hash table> >ht.insert(>'apple'>,>3>)> >ht.insert(>'banana'>,>2>)> >ht.insert(>'cherry'>,>5>)> > ># Check if the hash table> ># contains a key> >print>(>'apple'> in> ht)># True> >print>(>'durian'> in> ht)># False> > ># Get the value for a key> >print>(ht.search(>'banana'>))># 2> > ># Update the value for a key> >ht.insert(>'banana'>,>4>)> >print>(ht.search(>'banana'>))># 4> > >ht.remove(>'apple'>)> ># Check the size of the hash table> >print>(>len>(ht))># 3> |
>
>Výstup
True False 2 4 3>
Časová a prostorová složitost:
- The časovou složitost z vložit , Vyhledávání a odstranit metody v hašovací tabulce používající samostatné řetězení závisí na velikosti hašovací tabulky, počtu párů klíč-hodnota v hašovací tabulce a délce propojeného seznamu u každého indexu.
- Za předpokladu dobré hashovací funkce a rovnoměrného rozložení klíčů je předpokládaná časová náročnost těchto metod O(1) pro každou operaci. V horším případě však může být časová náročnost Na) , kde n je počet párů klíč–hodnota v hašovací tabulce.
- Je však důležité zvolit dobrou hašovací funkci a vhodnou velikost hašovací tabulky, aby se minimalizovala pravděpodobnost kolizí a zajistil se dobrý výkon.
- The prostorová složitost hašovací tabulky pomocí samostatného řetězení závisí na velikosti hašovací tabulky a počtu párů klíč-hodnota uložených v hašovací tabulce.
- Samotná hashovací tabulka bere O(m) prostor, kde m je kapacita hashovací tabulky. Každý uzel propojeného seznamu trvá O(1) prostoru a v propojených seznamech může být nejvýše n uzlů, kde n je počet párů klíč-hodnota uložených v hašovací tabulce.
- Celková složitost prostoru tedy je O(m + n) .
Závěr:
V praxi je důležité zvolit vhodnou kapacitu hashovací tabulky, aby se vyrovnalo využití prostoru a pravděpodobnost kolizí. Pokud je kapacita příliš malá, zvyšuje se pravděpodobnost kolize, což může způsobit snížení výkonu. Na druhou stranu, pokud je kapacita příliš velká, hashovací tabulka může spotřebovat více paměti, než je nutné.