V reálném světě ne všechna data, se kterými pracujeme, mají cílovou proměnnou. Tento druh dat nelze analyzovat pomocí algoritmů učení pod dohledem. Potřebujeme pomoc neřízených algoritmů. Jedním z nejpopulárnějších typů analýzy v rámci učení bez dozoru je segmentace zákazníků pro cílené reklamy nebo v lékařském zobrazování k nalezení neznámých nebo nově infikovaných oblastí a mnoho dalších případů použití, o kterých budeme dále diskutovat v tomto článku.
Obsah
- Co je Clustering?
- Typy shlukování
- Využití shlukování
- Typy shlukovacích algoritmů
- Aplikace Clusteringu v různých oblastech:
- Často kladené otázky (FAQ) o shlukování
Co je Clustering?
Úkol seskupování datových bodů na základě jejich vzájemné podobnosti se nazývá Clustering nebo Cluster Analysis. Tato metoda je definována pod větví Učení bez dozoru , jehož cílem je získat poznatky z neoznačených datových bodů, tedy na rozdíl od učení pod dohledem nemáme cílovou proměnnou.
Clustering se zaměřuje na vytváření skupin homogenních datových bodů z heterogenního souboru dat. Vyhodnocuje podobnost na základě metriky, jako je euklidovská vzdálenost, kosinová podobnost, vzdálenost na Manhattanu atd., a poté seskupuje body s nejvyšším skóre podobnosti.
Například v níže uvedeném grafu jasně vidíme, že existují 3 kruhové shluky tvořící se na základě vzdálenosti.
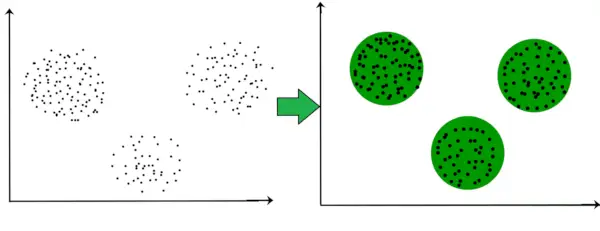
Nyní již není nutné, aby vytvořené shluky musely mít kruhový tvar. Tvar shluků může být libovolný. Existuje mnoho algoritmů, které dobře fungují s detekcí shluků libovolného tvaru.
java mvc
Například v níže uvedeném grafu můžeme vidět, že vytvořené shluky nemají kruhový tvar.

Typy shlukování
Obecně řečeno, existují 2 typy shlukování, které lze provést pro seskupení podobných datových bodů:
- Tvrdé shlukování: V tomto typu shlukování každý datový bod patří do shluku zcela nebo ne. Řekněme například, že existují 4 datové body a musíme je seskupit do 2 shluků. Takže každý datový bod bude patřit buď do clusteru 1, nebo do clusteru 2.
| Datové body | Shluky |
|---|---|
| A | C1 |
| B | C2 |
| C | C2 |
| D | C1 |
- Měkké shlukování: V tomto typu shlukování se místo přiřazení každého datového bodu do samostatného shluku vyhodnocuje pravděpodobnost nebo pravděpodobnost, že tento bod je daným shlukem. Řekněme například, že existují 4 datové body a musíme je seskupit do 2 shluků. Budeme tedy vyhodnocovat pravděpodobnost, že datový bod patří do obou shluků. Tato pravděpodobnost se vypočítá pro všechny datové body.
| Datové body | Pravděpodobnost C1 | Pravděpodobnost C2 |
| A | 0,91 | 0,09 |
| B | 0,3 | 0,7 |
| C | 0,17 | 0,83 |
| D | 1 | 0 |
Využití shlukování
Než začneme s typy shlukovacích algoritmů, projdeme si případy použití shlukovacích algoritmů. Shlukovací algoritmy se používají hlavně pro:
- Segmentace trhu – Firmy využívají seskupování k seskupování svých zákazníků a využívají cílené reklamy k přilákání většího publika.
- Analýza sociálních sítí – Stránky sociálních médií používají vaše data k pochopení vašeho chování při procházení a poskytují vám cílená doporučení přátel nebo doporučení obsahu.
- Lékařské zobrazování – Lékaři používají Clustering k nalezení nemocných oblastí na diagnostických snímcích, jako jsou rentgenové paprsky.
- Detekce anomálií – Abychom našli odlehlé hodnoty v proudu datové sady v reálném čase nebo předpověděli podvodné transakce, můžeme k jejich identifikaci použít shlukování.
- Zjednodušte práci s velkými datovými sadami – Po dokončení shlukování je každému clusteru přiděleno jeho ID. Nyní můžete zredukovat celou sadu funkcí na její cluster ID. Clustering je efektivní, když může představovat komplikovaný případ s přímočarým ID clusteru. Pomocí stejného principu může shlukování dat zjednodušit složité datové sady.
Existuje mnohem více případů použití pro shlukování, ale existují některé z hlavních a běžných případů použití shlukování. V budoucnu budeme diskutovat o shlukovacích algoritmech, které vám pomohou provést výše uvedené úkoly.
Typy shlukovacích algoritmů
Na povrchové úrovni pomáhá shlukování při analýze nestrukturovaných dat. Grafy, nejkratší vzdálenost a hustota datových bodů jsou některé z prvků, které ovlivňují tvorbu shluků. Shlukování je proces určování, jak jsou objekty příbuzné, na základě metriky zvané míra podobnosti. Metriky podobnosti lze snáze najít v menších sadách funkcí. Se zvyšujícím se počtem prvků je stále obtížnější vytvářet míry podobnosti. V závislosti na typu shlukovacího algoritmu používaného při dolování dat se k seskupování dat z datových sad používá několik technik. V této části jsou popsány techniky shlukování. Různé typy shlukovacích algoritmů jsou:
- Clustering na bázi centroidů (metody dělení)
- Shlukování na základě hustoty (metody založené na modelu)
- Clustering na základě konektivity (hierarchické shlukování)
- Clustering založený na distribuci
Každý z těchto typů si ve stručnosti projdeme.
1. Dělicí metody jsou nejjednodušší shlukovací algoritmy. Seskupují datové body na základě jejich blízkosti. Obecně jsou míry podobnosti zvolené pro tyto algoritmy Euklidovská vzdálenost, Manhattanská vzdálenost nebo Minkowského vzdálenost. Soubory dat jsou rozděleny do předem určeného počtu shluků a na každý shluk se odkazuje vektor hodnot. Ve srovnání s hodnotou vektoru nevykazuje proměnná vstupních dat žádný rozdíl a připojí se ke shluku.
co je obj v javě
Primární nevýhodou těchto algoritmů je požadavek, abychom stanovili počet shluků, k, buď intuitivně nebo vědecky (pomocí metody kolena), předtím, než jakýkoli shlukovací systém strojového učení začne přidělovat datové body. Navzdory tomu je stále nejoblíbenějším typem shlukování. K-znamená a K-medoidy shlukování jsou některé příklady tohoto typu shlukování.
2. Shlukování na základě hustoty (metody založené na modelu)
Shlukování založené na hustotě, metoda založená na modelu, najde skupiny na základě hustoty datových bodů. Na rozdíl od klastrování založeného na centroidech, které vyžaduje, aby byl počet klastrů předem definován a je citlivý na inicializaci, klastrování založené na hustotě určuje počet klastrů automaticky a je méně náchylné na počáteční pozice. Jsou skvělé při manipulaci s clustery různých velikostí a forem, takže jsou ideální pro datové sady s nepravidelně tvarovanými nebo překrývajícími se clustery. Tyto metody spravují oblasti s hustými i řídkými daty tím, že se zaměřují na místní hustotu a dokážou rozlišovat shluky s různými morfologiemi.
Naproti tomu seskupení založené na centroidech, stejně jako k-means, má problém najít shluky libovolného tvaru. Vzhledem k přednastavenému počtu požadavků na cluster a extrémní citlivosti na počáteční umístění těžišť se výsledky mohou lišit. Navíc tendence přístupů založených na centroidech vytvářet sférické nebo konvexní shluky omezuje jejich schopnost zvládnout komplikované nebo nepravidelně tvarované shluky. Závěrem lze říci, že shlukování založené na hustotě překonává nevýhody technik založených na centroidech tím, že autonomně vybírá velikosti shluků, je odolné vůči inicializaci a úspěšně zachycuje shluky různých velikostí a forem. Nejoblíbenější shlukovací algoritmus založený na hustotě je DBSCAN .
3. Clustering na základě konektivity (hierarchické shlukování)
Metoda pro sestavení souvisejících datových bodů do hierarchických shluků se nazývá hierarchické shlukování. Každý datový bod se zpočátku bere v úvahu jako samostatný shluk, který je následně kombinován se shluky, které jsou si nejpodobnější, do jednoho velkého shluku, který obsahuje všechny datové body.
Přemýšlejte o tom, jak můžete uspořádat sbírku položek podle toho, jak jsou podobné. Každý objekt začíná jako svůj vlastní shluk na základně stromu při použití hierarchického shlukování, které vytváří dendrogram, strukturu podobnou stromu. Nejbližší páry shluků jsou poté sloučeny do větších shluků poté, co algoritmus prozkoumá, jak moc jsou si objekty navzájem podobné. Když je každý objekt v jednom shluku v horní části stromu, proces slučování je dokončen. Prozkoumávání různých úrovní granularity je jednou ze zábavných věcí na hierarchickém shlukování. Chcete-li získat daný počet shluků, můžete vybrat, zda chcete řezat dendrogram v konkrétní výšce. Čím jsou si dva objekty v shluku podobnější, tím jsou blíže. Je to srovnatelné s klasifikací položek podle jejich rodokmenů, kde jsou nejbližší příbuzní seskupeni a širší větve znamenají obecnější souvislosti. Existují 2 přístupy pro hierarchické shlukování:
- Divisive Clustering : Postupuje se přístupem shora dolů, zde považujeme všechny datové body za součást jednoho velkého shluku a poté je tento shluk rozdělen do menších skupin.
- Aglomerativní shlukování : Jedná se o přístup zdola nahoru, zde považujeme všechny datové body za součást jednotlivých shluků a poté se tyto shluky spojí dohromady, aby vytvořily jeden velký shluk se všemi datovými body.
4. Klastrování založené na distribuci
Pomocí shlukování založeného na distribuci jsou datové body generovány a organizovány podle jejich sklonu spadat do stejného rozdělení pravděpodobnosti (jako je gaussovské, binomické nebo jiné) v datech. Datové prvky jsou seskupeny pomocí rozdělení založeného na pravděpodobnosti, které je založeno na statistických rozděleních. Zahrnuty jsou datové objekty, u kterých je vyšší pravděpodobnost, že budou v clusteru. U datového bodu je méně pravděpodobné, že bude zahrnut do shluku, čím dále je od centrálního bodu shluku, který existuje v každém shluku.
Významnou nevýhodou přístupů založených na hustotě a hranicích je potřeba specifikovat shluky a priori pro některé algoritmy, a především definice shlukové formy pro většinu algoritmů. Musí být vybrán alespoň jeden ladění nebo hyperparametr, a přitom by to mělo být jednoduché, jeho nesprávné nastavení by mohlo mít neočekávané následky. Shlukování založené na distribuci má oproti přístupům shlukování na základě blízkosti a centroidů jednoznačnou výhodu, pokud jde o flexibilitu, přesnost a strukturu shluků. Klíčovým problémem je, aby se zabránilo přepastování Mnoho metod shlukování pracuje pouze se simulovanými nebo vyrobenými daty, nebo když většina datových bodů jistě patří do přednastavené distribuce. Nejoblíbenější shlukovací algoritmus založený na distribuci je Gaussův model směsi .
Aplikace Clusteringu v různých oblastech:
- Marketing: Může být použit k charakterizaci a objevování zákaznických segmentů pro marketingové účely.
- Biologie: Může být použit pro klasifikaci mezi různé druhy rostlin a zvířat.
- Knihovny: Používá se při seskupování různých knih na základě témat a informací.
- Pojištění: Používá se k uznání zákazníků, jejich politik a identifikaci podvodů.
- Plánování města: Používá se k vytváření skupin domů a ke studiu jejich hodnot na základě jejich geografické polohy a dalších přítomných faktorů.
- Studie zemětřesení: Poznáním oblastí zasažených zemětřesením můžeme určit nebezpečné zóny.
- Zpracování obrazu : Clustering lze použít k seskupování podobných obrázků, klasifikaci obrázků na základě obsahu a identifikaci vzorů v obrazových datech.
- Genetika: Shlukování se používá k seskupování genů, které mají podobné vzorce exprese, ak identifikaci genových sítí, které spolupracují v biologických procesech.
- Finance: Clustering se používá k identifikaci tržních segmentů na základě chování zákazníků, identifikaci vzorců v datech akciového trhu a analýze rizik v investičních portfoliích.
- Služby zákazníkům: Clustering se používá k seskupování dotazů a stížností zákazníků do kategorií, identifikaci běžných problémů a vývoji cílených řešení.
- Výrobní : Clustering se používá k seskupování podobných produktů, optimalizaci výrobních procesů a identifikaci vad ve výrobních procesech.
- Lékařská diagnóza: Clustering se používá k seskupování pacientů s podobnými příznaky nebo nemocemi, což pomáhá při stanovení přesné diagnózy a identifikaci účinné léčby.
- Detekce podvodů: Clustering se používá k identifikaci podezřelých vzorců nebo anomálií ve finančních transakcích, což může pomoci při odhalování podvodů nebo jiných finančních trestných činů.
- Analýza návštěvnosti: Clustering se používá k seskupování podobných vzorců dopravních dat, jako jsou hodiny ve špičce, trasy a rychlosti, což může pomoci při zlepšování plánování dopravy a infrastruktury.
- Analýza sociálních sítí: Clustering se používá k identifikaci komunit nebo skupin v rámci sociálních sítí, což může pomoci pochopit sociální chování, vliv a trendy.
- Kybernetická bezpečnost: Clustering se používá k seskupování podobných vzorců síťového provozu nebo chování systému, což může pomoci při odhalování a prevenci kybernetických útoků.
- Klimatická analýza: Shlukování se používá k seskupování podobných vzorců klimatických dat, jako je teplota, srážky a vítr, což může pomoci porozumět změně klimatu a jejímu dopadu na životní prostředí.
- Sportovní analýza: Clustering se používá k seskupování podobných vzorců dat o výkonu hráče nebo týmu, což může pomoci při analýze silných a slabých stránek hráče nebo týmu a při strategických rozhodnutích.
- Analýza kriminality: Shlukování se používá k seskupování podobných vzorců dat o trestné činnosti, jako je poloha, čas a typ, což může pomoci při identifikaci ohnisek kriminality, předpovídání budoucích trendů kriminality a zlepšování strategií prevence kriminality.
Závěr
V tomto článku jsme probrali Clustering, jeho typy a aplikace v reálném světě. Učení bez dozoru je toho mnohem více, co je třeba pokrýt, a Clusterová analýza je jen prvním krokem. Tento článek vám může pomoci začít s algoritmy Clustering a pomoci vám získat nový projekt, který lze přidat do vašeho portfolia.
Často kladené otázky (FAQ) o shlukování
Otázka: Jaká je nejlepší metoda shlukování?
Mezi 10 nejlepších shlukovacích algoritmů patří:
- K-means Clustering
- Hierarchické shlukování
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
- Gaussovské modely směsí (GMM)
- Aglomerativní shlukování
- Spektrální shlukování
- Shlukování středního posunu
- Propagace afinity
- OPTIKA (objednací body k identifikaci shlukovací struktury)
- Birch (vyvážené iterativní snižování a shlukování pomocí hierarchií)
Otázka: Jaký je rozdíl mezi shlukováním a klasifikací?
Hlavní rozdíl mezi shlukováním a klasifikací je v tom, že klasifikace je algoritmus učení pod dohledem a shlukování je algoritmus učení bez dozoru. To znamená, že aplikujeme shlukování na ty datové sady, které nemají cílovou proměnnou.
Q. Jaké jsou výhody shlukové analýzy?
Data lze organizovat do smysluplných skupin pomocí silného analytického nástroje shlukové analýzy. Můžete jej použít k přesnému určení segmentů, nalezení skrytých vzorců a zlepšení rozhodování.
Otázka: Která metoda shlukování je nejrychlejší?
Shlukování K-means je často považováno za nejrychlejší metodu shlukování díky své jednoduchosti a výpočetní efektivitě. Iterativně přiřazuje datové body nejbližšímu centroidu shluků, takže je vhodný pro velké datové sady s nízkou dimenzionalitou a středním počtem shluků.
algebra množin
Otázka: Jaká jsou omezení shlukování?
Omezení shlukování zahrnují citlivost na počáteční podmínky, závislost na volbě parametrů, potíže s určením optimálního počtu shluků a problémy se zpracováním vysokorozměrných nebo zašuměných dat.
Q. Na čem závisí kvalita výsledku shlukování?
Kvalita výsledků shlukování závisí na faktorech, jako je výběr algoritmu, metrika vzdálenosti, počet shluků, metoda inicializace, techniky předběžného zpracování dat, metriky vyhodnocování shluků a znalost domény. Tyto prvky společně ovlivňují efektivitu a přesnost výsledku shlukování.