Jak víme, algoritmus řízeného strojového učení lze široce rozdělit na regresní a klasifikační algoritmy. V regresních algoritmech jsme předpověděli výstup pro spojité hodnoty, ale k predikci kategoriálních hodnot potřebujeme klasifikační algoritmy.
Co je klasifikační algoritmus?
Klasifikační algoritmus je technika supervizovaného učení, která se používá k identifikaci kategorie nových pozorování na základě trénovacích dat. V klasifikaci se program učí z daného souboru dat nebo pozorování a poté klasifikuje nové pozorování do několika tříd nebo skupin. Jako, Ano nebo Ne, 0 nebo 1, Spam nebo ne Spam, kočka nebo pes, atd. Třídy mohou být nazývány jako cíle/štítky nebo kategorie.
myši a typy myší
Na rozdíl od regrese je výstupní proměnnou klasifikace kategorie, nikoli hodnota, jako například „zelená nebo modrá“, „ovoce nebo zvíře“ atd. Protože algoritmus klasifikace je technika učení pod dohledem, přijímá označená vstupní data, která znamená, že obsahuje vstup s odpovídajícím výstupem.
V klasifikačním algoritmu je diskrétní výstupní funkce (y) mapována na vstupní proměnnou (x).
y=f(x), where y = categorical output
Nejlepším příkladem klasifikačního algoritmu ML je Email Spam Detector .
Hlavním cílem klasifikačního algoritmu je identifikovat kategorii daného datového souboru a tyto algoritmy se používají hlavně k predikci výstupu pro kategoriální data.
Klasifikační algoritmy lze lépe pochopit pomocí níže uvedeného diagramu. V níže uvedeném diagramu jsou dvě třídy, třída A a třída B. Tyto třídy mají vlastnosti, které jsou si navzájem podobné a nepodobné jiným třídám.
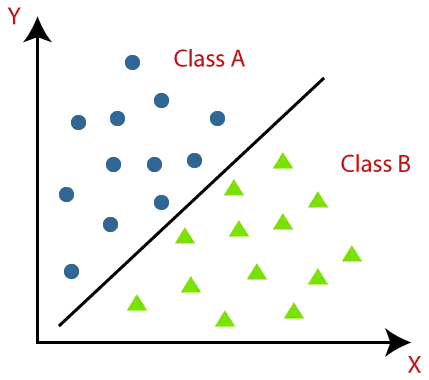
Algoritmus, který implementuje klasifikaci na datové množině, je známý jako klasifikátor. Existují dva typy klasifikací:
Příklady: ANO nebo NE, MUŽ nebo ŽENA, SPAM nebo NE SPAM, KOČKA nebo PES atd.
Příklad: Klasifikace druhů plodin, Klasifikace druhů hudby.
Studenti v klasifikačních problémech:
V klasifikačních problémech existují dva typy studentů:
jak převést řetězec na celé číslo java
Příklad: Algoritmus K-NN, případová úvaha
Typy ML klasifikačních algoritmů:
Klasifikační algoritmy lze dále rozdělit do převážně dvou kategorií:
- Logistická regrese
- Podpora vektorových strojů
- K-Nejbližší sousedé
- Jádro SVM
- Naivní Bayes
- Klasifikace rozhodovacího stromu
- Náhodná klasifikace lesa
Poznámka: Výše uvedené algoritmy se naučíme v dalších kapitolách.
Vyhodnocení klasifikačního modelu:
Jakmile je náš model dokončen, je nutné vyhodnotit jeho výkon; buď se jedná o klasifikační nebo regresní model. Takže pro vyhodnocení klasifikačního modelu máme následující způsoby:
1. Log Loss nebo Cross-Entropy Loss:
- Používá se pro hodnocení výkonu klasifikátoru, jehož výstupem je hodnota pravděpodobnosti mezi 0 a 1.
- Pro dobrý binární klasifikační model by se hodnota ztráty logu měla blížit 0.
- Hodnota logaritmické ztráty se zvyšuje, pokud se předpokládaná hodnota odchyluje od skutečné hodnoty.
- Nižší log ztráta představuje vyšší přesnost modelu.
- Pro binární klasifikaci lze křížovou entropii vypočítat jako:
?(ylog(p)+(1?y)log(1?p))
Kde y= skutečný výstup, p= předpokládaný výstup.
2. Matice zmatení:
- Matice zmatků nám poskytuje matici/tabulku jako výstup a popisuje výkon modelu.
- Je také známá jako chybová matice.
- Matice se skládá z výsledku předpovědí v souhrnné podobě, která má celkový počet správných předpovědí a nesprávných předpovědí. Matice vypadá jako v tabulce níže:
| Skutečně pozitivní | Skutečný negativní | |
|---|---|---|
| Předpokládaný pozitivní | Skutečně pozitivní | Falešně pozitivní |
| Předpokládaný záporný | Falešně negativní | Skutečně negativní |

3. Křivka AUC-ROC:
- ROC křivka znamená Křivka provozních charakteristik přijímače a AUC znamená Oblast pod křivkou .
- Je to graf, který ukazuje výkonnost klasifikačního modelu při různých prahových hodnotách.
- K vizualizaci výkonu modelu klasifikace více tříd používáme křivku AUC-ROC.
- Křivka ROC je vykreslena pomocí TPR a FPR, kde TPR (True Positive Rate) na ose Y a FPR (False Positive Rate) na ose X.
Příklady použití klasifikačních algoritmů
Klasifikační algoritmy lze použít na různých místech. Níže jsou uvedeny některé oblíbené případy použití klasifikačních algoritmů:
- Detekce e-mailového spamu
- Rozpoznávání řeči
- Identifikace rakovinných nádorových buněk.
- Klasifikace léčiv
- Biometrická identifikace atd.