Excelové listy jsou velmi instinktivní a uživatelsky přívětivé, díky čemuž jsou ideální pro manipulaci s velkými datovými sadami i pro méně technické lidi. Pokud hledáte místa, kde se můžete naučit manipulovat a automatizovat věci v souborech aplikace Excel Krajta , už nehledejte. Jste na správném místě.
V tomto článku se dozvíte, jak používat pandy pracovat s excelovými tabulkami. V tomto článku se dozvíme o:
- Číst Soubor Excel pomocí Pandy v Pythonu
- Instalace a import pand
- Čtení více listů aplikace Excel pomocí Pandas
- Aplikace různých funkcí Pandas
Čtení souboru Excel pomocí Pandas v Pythonu
Instalace Pandy
Chcete-li nainstalovat Pandy v Pythonu, můžeme použít následující příkaz v příkazovém řádku:
pip install pandas>
Chcete-li nainstalovat Pandy v Anaconda, můžeme použít následující příkaz v Anaconda Terminal:
conda install pandas>
Import pand
Nejprve musíme importovat modul Pandas, což lze provést spuštěním příkazu:
Python3
vlk versus liška
import> pandas as pd> |
>
>
Vložte soubor: Předpokládejme, že soubor Excel vypadá takto
List 1:

List 1
List 2:
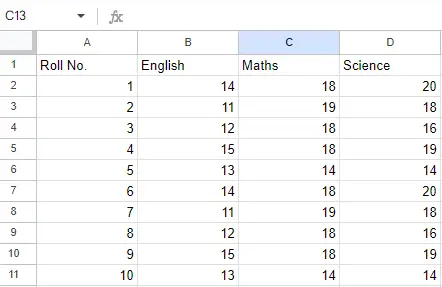
List 2
Nyní můžeme importovat soubor Excel pomocí funkce read_excel v Pandas a číst soubor Excel pomocí Pandas v Pythonu. Druhý příkaz načte data z Excelu a uloží je do datového rámce pandas, který je reprezentován proměnnou newData.
Python3
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Výstup:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Načítání více listů pomocí metody Concat().
Pokud je v sešitu aplikace Excel více listů, příkaz importuje data z prvního listu. Chcete-li vytvořit datový rámec se všemi listy v sešitu, nejjednodušší metodou je vytvořit různé datové rámce samostatně a pak je zřetězit. Metoda read_excel přebírá argument list_name a index_col, kde můžeme specifikovat list, ze kterého by měl být rámeček, a index_col určuje sloupec nadpisu, jak je ukázáno níže:
Příklad:
Třetí příkaz zřetězí oba listy. Nyní, abychom zkontrolovali celý datový rámec, můžeme jednoduše spustit následující příkaz:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Výstup:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metody Head() a Tail() v Pandas
Chcete-li zobrazit 5 sloupců z horní a dolní části datového rámce, můžeme spustit příkaz. Tento hlava() a ocas() metoda také bere argumenty jako čísla pro počet sloupců, které se mají zobrazit.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Výstup:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Metoda Shape().
The metoda shape(). lze použít k zobrazení počtu řádků a sloupců v datovém rámci takto:
Python3
newData.shape> |
>
>
Výstup:
(20, 3)>
Metoda Sort_values() v Pandas
Pokud některý sloupec obsahuje číselná data, můžeme tento sloupec seřadit pomocí sort_values() metoda v pandách takto:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Nyní předpokládejme, že chceme prvních 5 hodnot seřazeného sloupce, můžeme zde použít metodu head():
Python3
sorted_column.head(>5>)> |
>
>
Výstup:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Můžeme to udělat s jakýmkoli číselným sloupcem datového rámce, jak je uvedeno níže:
Python3
newData[>'Maths'>].head()> |
>
>
Výstup:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Metoda Pandas Describe().
Nyní předpokládejme, že naše data jsou převážně číselná. Můžeme získat statistické informace jako průměr, max, min atd. o datovém rámci pomocí popsat() způsob, jak je ukázáno níže:
Python3
newData.describe()> |
>
>
Výstup:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
To lze také provést samostatně pro všechny číselné sloupce pomocí následujícího příkazu:
Python3
newData[>'English'>].mean()> |
>
>
Výstup:
14.3>
Pomocí příslušných metod lze vypočítat i další statistické informace. Podobně jako v Excelu lze také použít vzorce a počítané sloupce lze vytvářet následovně:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
Výstup:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
Po operaci s daty v datovém rámci můžeme data exportovat zpět do excelovského souboru metodou to_excel. K tomu potřebujeme zadat výstupní soubor Excel, kam se mají zapsat transformovaná data, jak je znázorněno níže:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Výstup:
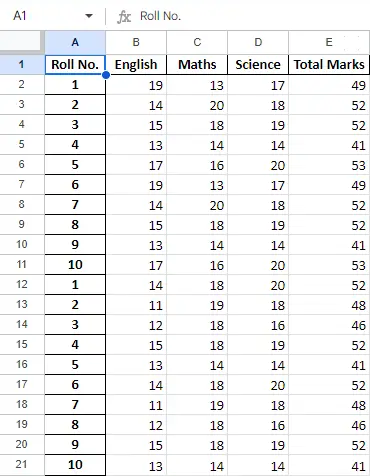
Závěrečný list