Klíčové slovo IDENTITY je vlastnost v SQL Server. Když je sloupec tabulky definován pomocí vlastnosti identity, jeho hodnota bude automaticky generovaná přírůstková hodnota . Tato hodnota je vytvořena serverem automaticky. Proto nemůžeme ručně zadat hodnotu do sloupce identity jako uživatel. Pokud tedy označíme sloupec jako identitu, SQL Server jej naplní způsobem automatického přírůstku.
Syntax
Následující syntaxe ilustruje použití vlastnosti IDENTITY v SQL Server:
IDENTITY[(seed, increment)]
Výše uvedené parametry syntaxe jsou vysvětleny níže:
Pojďme pochopit tento koncept na jednoduchém příkladu.
Předpokládejme, že máme ' Student ' stůl, a my chceme ID studenta vygenerovat automaticky. Máme ID začínajícího studenta 10 a chcete jej zvýšit o 1 s každým novým ID. V tomto scénáři musí být definovány následující hodnoty.
Semínko: 10
Přírůstek: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
POZNÁMKA: Pro každou tabulku na serveru SQL je povolen pouze jeden identifikační sloupec.
Příklad SQL Server IDENTITY
Pojďme pochopit, jak můžeme použít vlastnost identity v tabulce. Vlastnost identity ve sloupci lze nastavit buď při vytvoření nové tabulky, nebo po jejím vytvoření. Zde uvidíme oba případy s příklady.
Vlastnost IDENTITY s novou tabulkou
Následující příkaz vytvoří novou tabulku s vlastností identity do zadané databáze:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Dále do této tabulky vložíme nový řádek s a VÝSTUP klauzule k zobrazení automaticky generovaného ID osoby:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Po provedení tohoto dotazu se zobrazí následující výstup:
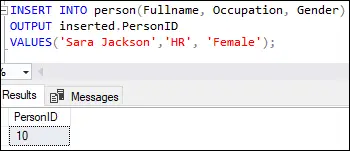
Tento výstup ukazuje, že první řádek byl vložen s hodnotou deset v ID osoby sloupec, jak je uvedeno ve sloupci identity definice tabulky.
Vložíme další řádek do stůl pro osoby jak je uvedeno níže:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Tento dotaz vrátí následující výstup:

Tento výstup ukazuje, že do sloupce PersonID byl vložen druhý řádek s hodnotou 11 a třetí řádek s hodnotou 12.
Vlastnost IDENTITY s existující tabulkou
Tento koncept si vysvětlíme tak, že nejprve smažeme výše uvedenou tabulku a vytvoříme je bez identity identity. Provedením níže uvedeného příkazu zrušte tabulku:
DROP TABLE person;
Dále vytvoříme tabulku pomocí níže uvedeného dotazu:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Pokud chceme přidat nový sloupec s vlastností identity do existující tabulky, musíme použít příkaz ALTER. Níže uvedený dotaz přidá PersonID jako sloupec identity do tabulky osob:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Explicitní přidání hodnoty do sloupce identity
Pokud přidáme nový řádek do výše uvedené tabulky explicitním zadáním hodnoty sloupce identity, SQL Server vyvolá chybu. Viz níže uvedený dotaz:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Provedením tohoto dotazu dojde k následující chybě:

Chcete-li explicitně vložit hodnotu sloupce identity, musíme nejprve nastavit hodnotu IDENTITY_INSERT na hodnotu ON. Dále proveďte operaci vložení pro přidání nového řádku do tabulky a poté nastavte hodnotu IDENTITY_INSERT na OFF. Viz níže uvedený skript kódu:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT ON umožňuje uživatelům vkládat data do sloupců identity IDENTITY_INSERT VYPNUTO zabrání jim v přidávání hodnoty do tohoto sloupce.
Spuštěním kódového skriptu se zobrazí níže uvedený výstup, kde vidíme, že PersonID s hodnotou 14 bylo úspěšně vloženo.

Funkce IDENTITY
SQL Server poskytuje některé funkce identity pro práci se sloupci IDENTITY v tabulce. Tyto funkce identity jsou uvedeny níže:
- Funkce @@IDENTITY
- Funkce SCOPE_IDENTITY().
- Funkce IDENT_CURRENT
- Funkce IDENTITY
Podívejme se na funkce IDENTITY s několika příklady.
Funkce @@IDENTITY
@@IDENTITY je systémem definovaná funkce, která zobrazí poslední hodnotu identity (maximální použitá hodnota identity) vytvořené v tabulce pro sloupec IDENTITY ve stejné relaci. Tento sloupec funkce vrací hodnotu identity vygenerovanou příkazem po vložení nové položky do tabulky. Vrací a NULA hodnotu, když provádíme dotaz, který nevytváří hodnoty IDENTITY. Funguje vždy v rámci aktuální relace. Nelze jej používat na dálku.
Příklad
Předpokládejme, že aktuální maximální hodnota identity v tabulce osob je 13. Nyní přidáme jeden záznam ve stejné relaci, který zvýší hodnotu identity o jednu. Potom použijeme funkci @@IDENTITY k získání poslední hodnoty identity vytvořené ve stejné relaci.
Zde je úplný skript kódu:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Spuštění skriptu vrátí následující výstup, kde vidíme, že maximální použitá hodnota identity je 14.

Funkce SCOPE_IDENTITY().
SCOPE_IDENTITY() je systémem definovaná funkce zobrazit nejnovější hodnotu identity v tabulce v aktuálním rozsahu. Tento obor může být modul, aktivační událost, funkce nebo uložená procedura. Je podobná funkci @@IDENTITY() s tím rozdílem, že tato funkce má pouze omezený rozsah. Funkce SCOPE_IDENTITY vrátí NULL, pokud ji provedeme před operací vložení, která generuje hodnotu ve stejném oboru.
Příklad
Níže uvedený kód používá funkci @@IDENTITY i SCOPE_IDENTITY() ve stejné relaci. Tento příklad nejprve zobrazí poslední hodnotu identity a poté vloží jeden řádek do tabulky. Dále provede obě funkce identity.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Spuštění kódu zobrazí stejnou hodnotu v aktuální relaci a podobném rozsahu. Viz následující výstupní obrázek:

Nyní na příkladu uvidíme, jak se obě funkce liší. Nejprve vytvoříme dvě tabulky pojmenované údaje o zaměstnanci a oddělení pomocí níže uvedeného prohlášení:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Dále vytvoříme spouštěč INSERT v tabulce zaměstnanec_data. Tento spouštěč je vyvolán k vložení řádku do tabulky oddělení, kdykoli vložíme řádek do tabulky zaměstnanecká_data.
Níže uvedený dotaz vytvoří spouštěč pro vložení výchozí hodnoty 'TO' v tabulce oddělení v každém vkládacím dotazu v tabulce zaměstnanec_data:
np.concatenate
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Po vytvoření spouštěče vložíme jeden záznam do tabulky zaměstnanec_data a uvidíme výstup funkcí @@IDENTITY a SCOPE_IDENTITY().
INSERT INTO employee_data VALUES ('John Mathew');
Provedení dotazu přidá jeden řádek do tabulky zaměstnanec_data a vygeneruje hodnotu identity ve stejné relaci. Jakmile je v tabulce zaměstnanec_data proveden dotaz vložení, automaticky zavolá spouštěč pro přidání jednoho řádku do tabulky oddělení. Počáteční hodnota identity je 1 pro zaměstnanecká_data a 100 pro tabulku oddělení.
Nakonec provedeme níže uvedené příkazy, které zobrazí výstup 100 pro funkci SELECT @@ IDENTITY a 1 pro funkci SCOPE_IDENTITY, protože vracejí hodnotu identity pouze ve stejném rozsahu.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Zde je výsledek:

Funkce IDENT_CURRENT().
IDENT_CURRENT je systémem definovaná funkce zobrazit nejnovější hodnotu IDENTITY generované pro danou tabulku pod jakýmkoli připojením. Tato funkce nebere v úvahu rozsah dotazu SQL, který vytváří hodnotu identity. Tato funkce vyžaduje název tabulky, pro kterou chceme získat hodnotu identity.
Příklad
Pochopíme to tak, že nejprve otevřeme dvě okna připojení. Do prvního okna vložíme jeden záznam, který generuje hodnotu identity 15 v tabulce osob. Dále můžeme tuto hodnotu identity ověřit v jiném okně připojení, kde můžeme vidět stejný výstup. Zde je úplný kód:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Provedení výše uvedených kódů ve dvou různých oknech zobrazí stejnou hodnotu identity.

Funkce IDENTITY().
Funkce IDENTITY() je systémem definovaná funkce používá se pro vložení sloupce identity do nové tabulky . Tato funkce se liší od vlastnosti IDENTITY, kterou používáme s příkazy CREATE TABLE a ALTER TABLE. Tuto funkci můžeme použít pouze v příkazu SELECT INTO, který se používá při přenosu dat z jedné tabulky do druhé.
Následující syntaxe ilustruje použití této funkce v SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Pokud zdrojová tabulka obsahuje sloupec IDENTITY, tabulka vytvořená pomocí příkazu SELECT INTO jej standardně zdědí. Například , dříve jsme vytvořili tabulku osoba se sloupcem identity. Předpokládejme, že vytvoříme novou tabulku, která zdědí tabulku osob pomocí příkazů SELECT INTO s funkcí IDENTITY(). V takovém případě dostaneme chybu, protože zdrojová tabulka již má sloupec identity. Viz níže uvedený dotaz:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Provedení výše uvedeného příkazu vrátí následující chybovou zprávu:

Vytvořme novou tabulku bez vlastnosti identity pomocí níže uvedeného příkazu:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Poté zkopírujte tuto tabulku pomocí příkazu SELECT INTO včetně funkce IDENTITY takto:
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Jakmile se příkaz provede, můžeme jej ověřit pomocí sp_help příkaz, který zobrazí vlastnosti tabulky.

Sloupec IDENTITA můžete vidět v POKUŠENÍ vlastnosti dle zadaných podmínek.
Pokud použijeme tuto funkci s příkazem SELECT, SQL Server projde následující chybovou zprávou:
Zpráva 177, úroveň 15, stav 1, řádek 2 Funkci IDENTITY lze použít pouze v případě, že příkaz SELECT obsahuje klauzuli INTO.
Opětovné použití hodnot IDENTITY
Nemůžeme znovu použít hodnoty identity v tabulce SQL Server. Když odstraníme libovolný řádek z tabulky sloupců identity, ve sloupci identity se vytvoří mezera. SQL Server také vytvoří mezeru, když vložíme nový řádek do sloupce identity a příkaz selže nebo se vrátí zpět. Mezera označuje, že hodnoty identity jsou ztraceny a nelze je znovu vygenerovat do sloupce IDENTITY.
Zvažte níže uvedený příklad, abyste to pochopili prakticky. Již máme tabulku osob obsahující následující údaje:

Dále vytvoříme další dvě tabulky s názvem 'pozice' , a ' pozice osoby “ pomocí následujícího prohlášení:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Dále se pokusíme vložit nový záznam do tabulky person a přiřadit jim pozici přidáním nového řádku do tabulky person_position. Provedeme to pomocí výpisu transakce, jak je uvedeno níže:
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Výše uvedený skript kódu transakce úspěšně provede první příkaz vložení. Ale druhé prohlášení selhalo, protože v tabulce pozic nebyla žádná pozice s ID deset. Celá transakce byla proto odvolána.
Protože máme maximální hodnotu identity ve sloupci PersonID 16, první příkaz insert spotřeboval hodnotu identity 17 a poté byla transakce odvolána. Pokud tedy vložíme další řádek do tabulky Osoba, další hodnota identity bude 18. Proveďte níže uvedený příkaz:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Po opětovné kontrole tabulky osob vidíme, že nově přidaný záznam obsahuje hodnotu identity 18.

Dva sloupce IDENTITY v jedné tabulce
Technicky není možné vytvořit dva sloupce identity v jedné tabulce. Pokud to uděláme, SQL Server vyvolá chybu. Viz následující dotaz:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Když spustíme tento kód, uvidíme následující chybu:

Můžeme však vytvořit dva sloupce identity v jedné tabulce pomocí vypočítaného sloupce. Následující dotaz vytvoří tabulku s vypočítaným sloupcem, který používá původní sloupec identity, a sníží jej o 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Dále do této tabulky přidáme některá data pomocí níže uvedeného příkazu:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Nakonec zkontrolujeme data tabulky pomocí příkazu SELECT. Vrací následující výstup:

Na obrázku můžeme vidět, jak sloupec SecondID funguje jako druhý sloupec identity, který se z počáteční hodnoty 9990 snižuje o deset.
Mylné představy o sloupci IDENTITY SQL Serveru
Uživatel DBA má mnoho mylných představ ohledně sloupců identity SQL Server. Níže je uveden seznam nejčastějších mylných představ týkajících se sloupců identity, které by se mohly zobrazit:
Sloupec IDENTITY je UNIKÁTNÍ: Podle oficiální dokumentace SQL Server vlastnost identity nemůže zaručit, že hodnota sloupce je jedinečná. K vynucení jedinečnosti sloupce musíme použít PRIMARY KEY, UNIQUE omezení nebo UNIQUE index.
Sloupec IDENTITY generuje po sobě jdoucí čísla: Oficiální dokumentace jasně uvádí, že přiřazené hodnoty ve sloupci identity mohou být ztraceny při selhání databáze nebo restartu serveru. Může způsobit mezery v hodnotě identity během vkládání. Mezeru lze také vytvořit, když odstraníme hodnotu z tabulky nebo se vrátí příkaz insert. Hodnoty, které generují mezery, nelze dále použít.
Sloupec IDENTITY nemůže automaticky generovat existující hodnoty: Není možné, aby sloupec identity automaticky generoval existující hodnoty, dokud není vlastnost identity znovu nasazena pomocí příkazu DBCC CHECKIDENT. Umožňuje nám upravit počáteční hodnotu (počáteční hodnotu řádku) vlastnosti identity. Po provedení tohoto příkazu SQL Server nebude kontrolovat nově vytvořené hodnoty, které již v tabulce jsou nebo nejsou.
Sloupec IDENTITY jako PRIMÁRNÍ KLÍČ stačí k identifikaci řádku: Pokud primární klíč obsahuje sloupec identity v tabulce bez jakýchkoli dalších jedinečných omezení, může sloupec ukládat duplicitní hodnoty a bránit jedinečnosti sloupce. Jak víme, primární klíč nemůže ukládat duplicitní hodnoty, ale sloupec identity může ukládat duplikáty; doporučuje se nepoužívat primární klíč a vlastnost identity ve stejném sloupci.
Použití nesprávného nástroje k získání hodnot identity zpět po vložení: Je také běžnou mylnou představou o neznalosti rozdílů mezi funkcemi @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT a IDENTITY(), aby se hodnota identity vložila přímo z příkazu, který jsme právě provedli.
Rozdíl mezi SEQUENCE a IDENTITY
Pro generování automatických čísel používáme SEQUENCE i IDENTITY. Má však určité rozdíly a hlavním rozdílem je, že identita je závislá na tabulce, zatímco sekvence nikoli. Shrňme jejich rozdíly do tabulkové formy:
| IDENTITA | SEKVENCE |
|---|---|
| Vlastnost identity se používá pro konkrétní tabulku a nelze ji sdílet s jinými tabulkami. | DBA definuje sekvenční objekt, který lze sdílet mezi více tabulkami, protože je nezávislý na tabulce. |
| Tato vlastnost automaticky generuje hodnoty pokaždé, když je v tabulce proveden příkaz insert. | Ke generování další hodnoty pro sekvenční objekt používá klauzuli NEXT VALUE FOR. |
| SQL Server neresetuje hodnotu sloupce vlastnosti identity na původní hodnotu. | SQL Server může obnovit hodnotu pro objekt sekvence. |
| Nemůžeme nastavit maximální hodnotu vlastnosti identity. | Pro objekt sekvence můžeme nastavit maximální hodnotu. |
| Je zaveden v SQL Server 2000. | Je představen v SQL Server 2012. |
| Tato vlastnost nemůže generovat hodnotu identity v sestupném pořadí. | Může generovat hodnoty v sestupném pořadí. |
Závěr
Tento článek poskytne úplný přehled vlastnosti IDENTITY na serveru SQL Server. Zde jsme se naučili, jak a kdy se používá vlastnost identity, její různé funkce, mylné představy a jak se liší od sekvence.