Prohlášení GROUP BY v SQL slouží k uspořádání identických dat do skupin pomocí některých funkcí. tj. pokud má určitý sloupec stejné hodnoty v různých řádcích, uspořádá tyto řádky do skupiny.
Funkce
- Klauzule GROUP BY se používá s příkazem SELECT.
- V dotazu je klauzule GROUP BY umístěna za KDE doložka.
- V dotazu je klauzule GROUP BY umístěna před OBJEDNAT BY klauzule, pokud je použita.
- V dotazu je klauzule Group BY umístěna před klauzuli Having.
- Umístěte podmínku do klauzule have .
Syntax :
SELECT sloupec1, název_funkce(sloupec2)
FROM název_tabulky
KDE podmínka
GROUP BY sloupec1, sloupec2
myflixrORDER BY column1, column2;
Vysvětlení:
- název_funkce : Název použité funkce, například SUM() , AVG().
- název_tabulky : Název tabulky.
- stav : Stav použitý.
Předpokládejme, že máme dvě tabulky Zaměstnanec a Student Vzorová tabulka je následující po přidání dvou tabulek provedeme některé specifické operace, abychom se dozvěděli o GROUP BY.
Tabulka zaměstnanců:
CREATE TABLE emp ( emp_no INT PRIMARY KEY, name VARCHAR(50), sal DECIMAL(10,2), age INT );>
Vložte nějaká náhodná data do tabulky a poté provedeme některé operace v GROUP BY.
Dotaz:
INSERT INTO emp (emp_no, name, sal, age) VALUES (1, 'Aarav', 50000.00, 25), (2, 'Aditi', 60000.50, 30), (3, 'Amit', 75000.75, 35), (4, 'Anjali', 45000.25, 28), (5, 'Chetan', 80000.00, 32), (6, 'Divya', 65000.00, 27), (7, 'Gaurav', 55000.50, 29), (8, 'Isha', 72000.75, 31), (9, 'Kavita', 48000.25, 26), (10, 'Mohan', 83000.00, 33);>
Výstup:
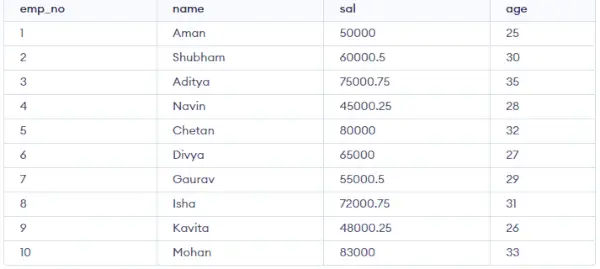
Studentský stůl:
Dotaz:
CREATE TABLE student ( name VARCHAR(50), year INT, subject VARCHAR(50) ); INSERT INTO student (name, year, subject) VALUES ('Alice', 1, 'Mathematics'), ('Bob', 2, 'English'), ('Charlie', 3, 'Science'), ('David', 1, 'History'), ('Emily', 2, 'Art'), ('Frank', 3, 'Computer Science');> Výstup:
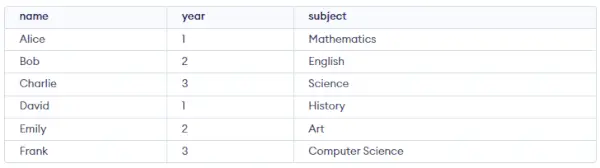
Seskupit podle jednoho sloupce
Seskupit podle jednoho sloupce znamená umístit všechny řádky se stejnou hodnotou pouze daného sloupce do jedné skupiny. Zvažte dotaz, jak je uvedeno níže:
Dotaz:
SELECT NAME, SUM(SALARY) FROM emp GROUP BY NAME;>
Výše uvedený dotaz vytvoří následující výstup:
přepnout java
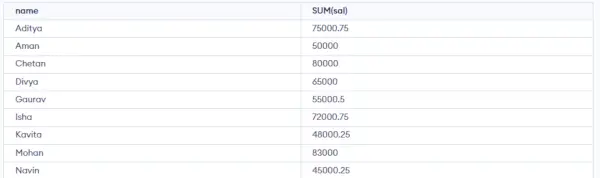
Jak můžete vidět na výše uvedeném výstupu, řádky s duplicitními JMÉNY jsou seskupeny pod stejným JMÉNEM a jejich odpovídající SALARY je součtem PLATŮ duplicitních řádků. K výpočtu součtu se zde používá funkce SUM() jazyka SQL.
Seskupit podle více sloupců
Seskupit podle více sloupců je řekněme např. GROUP BY sloupec1, sloupec2 . To znamená umístit všechny řádky se stejnými hodnotami sloupců sloupec 1 a sloupec 2 v jedné skupině. Zvažte níže uvedený dotaz:
Dotaz:
SELECT SUBJECT, YEAR, Count(*) FROM Student GROUP BY SUBJECT, YEAR;>
Výstup:
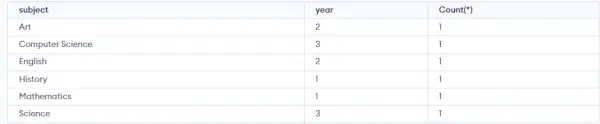
Výstup : Jak můžete vidět na výše uvedeném výstupu, studenti se stejným PŘEDMĚTEM a ROKEM jsou umístěni do stejné skupiny. A ti, jejichž jediný PŘEDMĚT je stejný, ale ne ROK, patří do různých skupin. Zde jsme tedy seskupili tabulku podle dvou sloupců nebo více než jednoho sloupce.
Klauzule HAVING v klauzuli GROUP BY
Víme, že klauzule WHERE se používá k umístění podmínek na sloupce, ale co když chceme umístit podmínky na skupiny? Zde se používá klauzule HAVING. Klauzuli HAVING můžeme použít k umístění podmínek, abychom rozhodli, která skupina bude součástí konečné sady výsledků. Také nemůžeme použít agregační funkce jako SUM(), COUNT() atd. s klauzulí WHERE. Musíme tedy použít klauzuli HAVING, pokud chceme v podmínkách použít některou z těchto funkcí.
Syntax :
SELECT sloupec1, název_funkce(sloupec2)
FROM název_tabulky
KDE podmínka
GROUP BY sloupec1, sloupec2
dfs vs bfsMÍT podmínku
ORDER BY column1, column2;
Vysvětlení:
- název_funkce : Název použité funkce, například SUM() , AVG().
- název_tabulky : Název tabulky.
- stav : Stav použitý.
Příklad :
SELECT NAME, SUM(sal) FROM Emp GROUP BY name HAVING SUM(sal)>3000;>
Výstup :
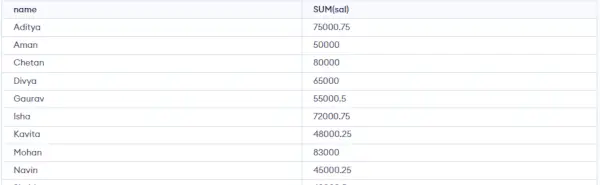
Jak můžete vidět na výše uvedeném výstupu, pouze jedna skupina ze tří skupin se objeví ve výsledkové sadě, protože je to jediná skupina, kde je součet SALARY větší než 3000. Použili jsme tedy klauzuli HAVING, abychom tuto podmínku umístili jako podmínka musí být umístěna na skupiny, nikoli na sloupce.