Než se podíváme na rozdíly mezi BFS a DFS, měli bychom nejprve vědět o BFS a DFS samostatně.
Co je BFS?
BFS znamená První vyhledávání šířky . Je také známý jako úrovňové procházení objednávky . Datová struktura Queue se používá pro procházení Breadth First Search. Když použijeme algoritmus BFS pro průchod v grafu, můžeme za kořenový uzel považovat jakýkoli uzel.
Podívejme se na níže uvedený graf pro první procházení šířky vyhledávání.
porovnat řetězec java
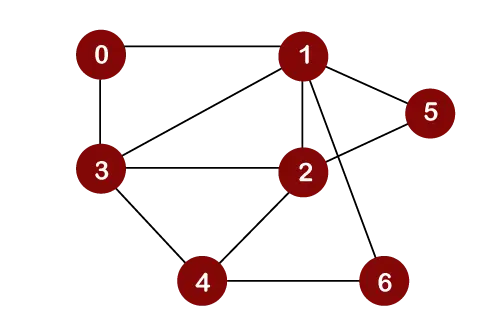
Předpokládejme, že považujeme uzel 0 za kořenový uzel. Proto by procházení začalo od uzlu 0.

Jakmile je uzel 0 odstraněn z fronty, bude vytištěn a označen jako a navštívený uzel.
Jakmile bude uzel 0 odstraněn z fronty, sousední uzly uzlu 0 budou vloženy do fronty, jak je znázorněno níže:

Nyní bude uzel 1 odstraněn z fronty; vytiskne se a označí jako navštívený uzel
Jakmile bude uzel 1 odstraněn z fronty, všechny sousední uzly uzlu 1 budou přidány do fronty. Sousední uzly uzlu 1 jsou 0, 3, 2, 6 a 5. Do fronty však musíme vložit pouze nenavštívené uzly. Protože uzly 3, 2, 6 a 5 jsou nenavštíveny; proto budou tyto uzly přidány do fronty, jak je uvedeno níže:

Další uzel je 3 ve frontě. Takže uzel 3 bude odstraněn z fronty, bude vytištěn a označen jako navštívený, jak je uvedeno níže:

Jakmile bude uzel 3 odstraněn z fronty, budou všechny sousední uzly uzlu 3 kromě navštívených uzlů přidány do fronty. Sousední uzly uzlu 3 jsou 0, 1, 2 a 4. Protože uzly 0, 1 jsou již navštíveny a uzel 2 je přítomen ve frontě; proto musíme do fronty vložit pouze uzel 4.
java datum na řetězec

Nyní je další uzel ve frontě 2. Takže 2 bude z fronty odstraněn. Vytiskne se a označí jako navštívené, jak je znázorněno níže:

Jakmile bude uzel 2 odstraněn z fronty, budou všechny sousední uzly uzlu 2 kromě navštívených uzlů přidány do fronty. Sousední uzly uzlu 2 jsou 1, 3, 5, 6 a 4. Protože uzly 1 a 3 již byly navštíveny a 4, 5, 6 jsou již přidány do fronty; proto nemusíme do fronty vkládat žádný uzel.
Dalším prvkem je 5. Takže 5 bude odstraněno z fronty. Vytiskne se a označí jako navštívené, jak je znázorněno níže:

Jakmile bude uzel 5 odstraněn z fronty, budou do fronty přidány všechny sousední uzly uzlu 5 kromě navštívených uzlů. Sousední uzly uzlu 5 jsou 1 a 2. Protože oba uzly již byly navštíveny; proto není do fronty vložen žádný vrchol.
Další uzel je 6. Takže 6 bude odstraněno z fronty. Vytiskne se a označí jako navštívené, jak je znázorněno níže:

Jakmile bude uzel 6 odstraněn z fronty, budou do fronty přidány všechny sousední uzly uzlu 6 kromě navštívených uzlů. Sousední uzly uzlu 6 jsou 1 a 4. Protože uzel 1 již byl navštíven a uzel 4 je již přidán do fronty; proto není vrchol, který by se měl vložit do fronty.
Dalším prvkem ve frontě je 4. Takže 4 bude z fronty odstraněn. Vytiskne se a označí jako navštívené.
Jakmile bude uzel 4 odstraněn z fronty, budou do fronty přidány všechny sousední uzly uzlu 4 kromě navštívených uzlů. Sousední uzly uzlu 4 jsou 3, 2 a 6. Protože všechny sousední uzly již byly navštíveny; takže do fronty není možné vložit žádný vrchol.
Co je DFS?
DFS znamená Depth First Search. V DFS traversal se využívá datová struktura zásobníku, která funguje na principu LIFO (Last In First Out). V DFS lze procházení spustit z libovolného uzlu nebo můžeme říci, že jakýkoli uzel lze považovat za kořenový uzel, dokud kořenový uzel není uveden v problému.
V případě BFS, prvku, který je odstraněn z Queue, jsou sousední uzly odstraněného uzlu přidány do Queue. Naproti tomu v DFS, prvek, který je odstraněn ze zásobníku, je do zásobníku přidán pouze jeden sousední uzel odstraněného uzlu.
Podívejme se na níže uvedený graf pro procházení hloubkou prvního vyhledávání.
plná forma i d e

Považujte uzel 0 za kořenový uzel.
řetězec v Javě
Nejprve vložíme prvek 0 do zásobníku, jak je znázorněno níže:

Uzel 0 má dva sousední uzly, tj. 1 a 3. Nyní můžeme vzít pro procházení pouze jeden sousední uzel, buď 1 nebo 3. Předpokládejme, že uvažujeme uzel 1; proto se 1 vloží do stohu a vytiskne se, jak je znázorněno níže:

Nyní se podíváme na sousední vrcholy uzlu 1. Nenavštívené sousední vrcholy uzlu 1 jsou 3, 2, 5 a 6. Můžeme uvažovat kterýkoli z těchto čtyř vrcholů. Předpokládejme, že vezmeme uzel 3 a vložíme jej do zásobníku, jak je znázorněno níže:

Uvažujme nenavštívené sousední vrcholy uzlu 3. Nenavštívené sousední vrcholy uzlu 3 jsou 2 a 4. Můžeme vzít kterýkoli z vrcholů, tj. 2 nebo 4. Předpokládejme, že vezmeme vrchol 2 a vložíme jej do zásobníku, jak je znázorněno níže:

Nenavštívené sousední vrcholy uzlu 2 jsou 5 a 4. Můžeme si vybrat jeden z vrcholů, tj. 5 nebo 4. Předpokládejme, že vezmeme vrchol 4 a vložíme do zásobníku, jak je znázorněno níže:

Nyní budeme uvažovat nenavštívené sousední vrcholy uzlu 4. Nenavštíveným sousedním vrcholem uzlu 4 je uzel 6. Proto je prvek 6 vložen do zásobníku, jak je znázorněno níže:

Po vložení prvku 6 do zásobníku se podíváme na nenavštívené sousední vrcholy uzlu 6. Protože v uzlu 6 nejsou žádné nenavštívené sousední vrcholy, nemůžeme se přesunout za uzel 6. V tomto případě provedeme zpětné sledování . Nejhornější prvek, tj. 6, by se vysunul ze zásobníku, jak je znázorněno níže:


Nejvyšší prvek v zásobníku je 4. Protože z uzlu 4 nezůstaly žádné nenavštívené sousední vrcholy; proto se uzel 4 vysune ze zásobníku, jak je znázorněno níže:


Dalším nejvyšším prvkem v zásobníku je 2. Nyní se podíváme na nenavštívené sousední vrcholy uzlu 2. Protože zbývá pouze jeden nenavštívený uzel, tj. 5, uzel 5 by byl zatlačen do zásobníku nad 2 a vytištěn Jak je ukázáno níže:

Nyní zkontrolujeme sousední vrcholy uzlu 5, které jsou stále nenavštívené. Protože nezbývá žádný vrchol, který by bylo možné navštívit, vyjmeme prvek 5 ze zásobníku, jak je znázorněno níže:

Nemůžeme se posunout o dalších 5, takže musíme provést backtracking. Při zpětném sledování by se ze zásobníku vysunul nejvyšší prvek. Nejvyšší prvek je 5, který by vyskočil ze zásobníku, a přesuneme se zpět do uzlu 2, jak je znázorněno níže:
pandy iterrows

Nyní zkontrolujeme nenavštívené sousední vrcholy uzlu 2. Protože nezbývá žádný sousední vrchol k návštěvě, provedeme backtracking. Při zpětném sledování by se ze zásobníku vysunul nejvyšší prvek, tj. 2, a přesuneme se zpět do uzlu 3, jak je znázorněno níže:


Nyní zkontrolujeme nenavštívené sousední vrcholy uzlu 3. Protože nezbývá žádný sousední vrchol k návštěvě, provedeme backtracking. Při zpětném sledování by se ze zásobníku vysunul nejvyšší prvek, tj. 3, a přesuneme se zpět do uzlu 1, jak je znázorněno níže:


Po vysunutí prvku 3 zkontrolujeme nenavštívené sousední vrcholy uzlu 1. Protože nezbývá žádný vrchol, který by bylo možné navštívit; proto bude provedeno zpětné sledování. Při zpětném sledování by se ze zásobníku vysunul nejvyšší prvek, tj. 1, a přesuneme se zpět do uzlu 0, jak je znázorněno níže:


Zkontrolujeme sousední vrcholy uzlu 0, které jsou stále nenavštívené. Protože nezbývá žádný sousední vrchol, který by bylo možné navštívit, provádíme backtracking. V tomto případě by se ze zásobníku vysunul pouze jeden prvek, tj. 0 zbylá v zásobníku, jak je znázorněno níže:

Jak můžeme vidět na obrázku výše, zásobník je prázdný. Zde tedy musíme zastavit procházení DFS a prvky, které se tisknou, jsou výsledkem procházení DFS.
Rozdíly mezi BFS a DFS
Níže jsou uvedeny rozdíly mezi BFS a DFS:
| BFS | DFS | |
|---|---|---|
| Plná forma | BFS znamená Breadth First Search. | DFS znamená Depth First Search. |
| Technika | Je to technika založená na vrcholech k nalezení nejkratší cesty v grafu. | Je to technika založená na hranách, protože vrcholy podél hrany jsou zkoumány nejprve od počátečního do koncového uzlu. |
| Definice | BFS je technika procházení, ve které jsou nejprve prozkoumány všechny uzly stejné úrovně a poté se přesuneme na další úroveň. | DFS je také traverzální technika, při které se traverz začíná od kořenového uzlu a prozkoumává uzly tak daleko, jak je to možné, dokud nedosáhneme uzlu, který nemá žádné nenavštívené sousední uzly. |
| Datová struktura | Pro procházení BFS se používá datová struktura fronty. | Pro procházení BFS se používá datová struktura zásobníku. |
| Zpětné sledování | BFS nepoužívá koncept backtrackingu. | DFS používá backtracking k procházení všemi nenavštívenými uzly. |
| Počet hran | BFS najde nejkratší cestu s minimálním počtem hran, které se mají projet ze zdrojového do cílového vrcholu. | V DFS je potřeba větší počet hran k přechodu ze zdrojového vrcholu do cílového vrcholu. |
| Optimalita | BFS traversal je optimální pro ty vrcholy, které se mají hledat blíže ke zdrojovému vrcholu. | DFS traversal je optimální pro ty grafy, ve kterých jsou řešení vzdálena od zdrojového vrcholu. |
| Rychlost | BFS je pomalejší než DFS. | DFS je rychlejší než BFS. |
| Vhodnost pro rozhodovací strom | Není vhodný pro rozhodovací strom, protože vyžaduje nejprve prozkoumání všech sousedních uzlů. | Je vhodný pro rozhodovací strom. Na základě rozhodnutí prozkoumává všechny cesty. Když je cíl nalezen, zastaví jeho průchod. |
| Paměťově efektivní | Není paměťově efektivní, protože vyžaduje více paměti než DFS. | Je paměťově efektivní, protože vyžaduje méně paměti než BFS. |