V tomto článku budeme diskutovat o algoritmu DFS v datové struktuře. Jedná se o rekurzivní algoritmus pro prohledávání všech vrcholů stromové datové struktury nebo grafu. Algoritmus prohledávání do hloubky (DFS) začíná počátečním uzlem grafu G a jde hlouběji, dokud nenajdeme cílový uzel nebo uzel bez potomků.
Vzhledem k rekurzivní povaze lze k implementaci algoritmu DFS použít datovou strukturu zásobníku. Proces implementace DFS je podobný algoritmu BFS.
Postup krok za krokem k implementaci procházení DFS je uveden následovně -
- Nejprve vytvořte zásobník s celkovým počtem vrcholů v grafu.
- Nyní vyberte libovolný vrchol jako počáteční bod procházení a zatlačte tento vrchol do zásobníku.
- Poté přesuňte nenavštívený vrchol (sousedící s vrcholem na vrcholu zásobníku) na vrchol zásobníku.
- Nyní opakujte kroky 3 a 4, dokud nezůstanou žádné vrcholy, které by bylo možné navštívit z vrcholu na vrcholu zásobníku.
- Pokud nezůstane žádný vrchol, vraťte se a vyjměte vrchol ze zásobníku.
- Opakujte kroky 2, 3 a 4, dokud nebude zásobník prázdný.
Aplikace algoritmu DFS
Aplikace použití algoritmu DFS jsou uvedeny následovně -
- Algoritmus DFS lze použít k implementaci topologického třídění.
- Lze jej použít k nalezení cest mezi dvěma vrcholy.
- Lze jej také použít k detekci cyklů v grafu.
- Algoritmus DFS se také používá pro hádanky s jedním řešením.
- DFS se používá k určení, zda je graf bipartitní nebo ne.
Algoritmus
Krok 1: SET STATUS = 1 (stav připravenosti) pro každý uzel v G
Krok 2: Zatlačte počáteční uzel A na zásobník a nastavte jeho STAV = 2 (stav čekání)
Krok 3: Opakujte kroky 4 a 5, dokud není STACK prázdný
Krok 4: Otevřete horní uzel N. Zpracujte jej a nastavte jeho STAV = 3 (stav zpracování)
Krok 5: Zatlačte na zásobník všechny sousedy N, kteří jsou ve stavu připravenosti (jejichž STATUS = 1) a nastavte jejich STATUS = 2 (stav čekání)
[KONEC SMYČKY]
Krok 6: VÝSTUP
Pseudo kód
DFS(G,v) ( v is the vertex where the search starts ) Stack S := {}; ( start with an empty stack ) for each vertex u, set visited[u] := false; push S, v; while (S is not empty) do u := pop S; if (not visited[u]) then visited[u] := true; for each unvisited neighbour w of uu push S, w; end if end while END DFS() Příklad algoritmu DFS
Nyní na příkladu pochopíme fungování algoritmu DFS. V níže uvedeném příkladu je orientovaný graf se 7 vrcholy.
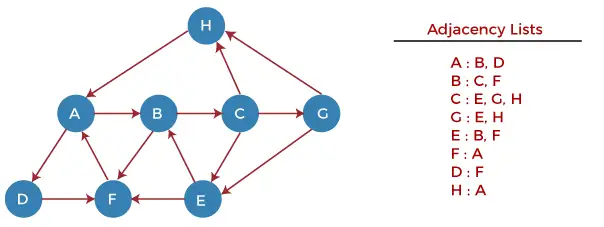
Nyní začneme zkoumat graf od uzlu H.
Krok 1 - Nejprve zatlačte H na hromádku.
STACK: H
Krok 2 - Vyjměte horní prvek ze zásobníku, tj. H, a vytiskněte jej. Nyní PUSH všechny sousedy H do zásobníku, které jsou ve stavu připravenosti.
Print: H]STACK: A
Krok 3 - Vyjměte horní prvek ze zásobníku, tj. A, a vytiskněte jej. Nyní PUSH všechny sousedy A na hromádku, které jsou ve stavu připravenosti.
Print: A STACK: B, D
Krok 4 - Vysuňte horní prvek ze zásobníku, tj. D, a vytiskněte jej. Nyní PUSH všechny sousedy D do zásobníku, které jsou ve stavu připravenosti.
Print: D STACK: B, F
Krok 5 - Vyjměte horní prvek ze zásobníku, tj. F, a vytiskněte jej. Nyní PUSH všechny sousedy F do zásobníku, které jsou ve stavu připravenosti.
Print: F STACK: B
Krok 6 - Vyjměte horní prvek ze zásobníku, tj. B, a vytiskněte jej. Nyní PUSH všechny sousedy B na hromádku, které jsou ve stavu připravenosti.
Print: B STACK: C
Krok 7 - Vyjměte horní prvek ze zásobníku, tj. C, a vytiskněte jej. Nyní PUSH všechny sousedy C do zásobníku, které jsou ve stavu připravenosti.
Print: C STACK: E, G
Krok 8 - Vysuňte horní prvek ze zásobníku, tj. G a PUSH všechny sousedy G do zásobníku, které jsou ve stavu připravenosti.
Print: G STACK: E
Krok 9 - Vysuňte horní prvek ze zásobníku, tj. E a PUSH všechny sousedy E do zásobníku, které jsou ve stavu připravenosti.
Print: E STACK:
Nyní byly projety všechny uzly grafu a zásobník je prázdný.
Složitost algoritmu prohledávání hloubky
Časová složitost algoritmu DFS je O(V+E) , kde V je počet vrcholů a E je počet hran v grafu.
sort array list java
Prostorová složitost algoritmu DFS je O(V).
Implementace DFS algoritmu
Nyní se podívejme na implementaci algoritmu DFS v Javě.
V tomto příkladu je graf, který používáme k demonstraci kódu, uveden následovně -

/*A sample java program to implement the DFS algorithm*/ import java.util.*; class DFSTraversal { private LinkedList adj[]; /*adjacency list representation*/ private boolean visited[]; /* Creation of the graph */ DFSTraversal(int V) /*'V' is the number of vertices in the graph*/ { adj = new LinkedList[V]; visited = new boolean[V]; for (int i = 0; i <v; i++) adj[i]="new" linkedlist(); } * adding an edge to the graph void insertedge(int src, int dest) { adj[src].add(dest); dfs(int vertex) visited[vertex]="true;" *mark current node as visited* system.out.print(vertex + ' '); iterator it="adj[vertex].listIterator();" while (it.hasnext()) n="it.next();" if (!visited[n]) dfs(n); public static main(string args[]) dfstraversal dfstraversal(8); graph.insertedge(0, 1); 2); 3); graph.insertedge(1, graph.insertedge(2, 4); graph.insertedge(3, 5); 6); graph.insertedge(4, 7); graph.insertedge(5, system.out.println('depth first traversal for is:'); graph.dfs(0); < pre> <p> <strong>Output</strong> </p> <img src="//techcodeview.com/img/ds-tutorial/28/dfs-algorithm-3.webp" alt="DFS algorithm"> <h3>Conclusion</h3> <p>In this article, we have discussed the depth-first search technique, its example, complexity, and implementation in the java programming language. Along with that, we have also seen the applications of the depth-first search algorithm.</p> <p>So, that's all about the article. Hope it will be helpful and informative to you.</p> <hr></v;>