Funkce REGEXP_LIKE() v MySQL se používá pro vyhledávání vzorů. To porovnává, zda dané řetězce odpovídají regulárnímu výrazu či nikoli . Vrátí 1, pokud se řetězce shodují s regulárním výrazem, a vrátí 0, pokud nebude nalezena žádná shoda.
Syntax
Níže je uvedena základní syntaxe pro použití této funkce MySQL :
REGEXP_LIKE (expression, pattern [, match_type])
Vysvětlení parametru
Vysvětlení parametrů funkce REGEXP_LIKE() je:
výraz: Je to vstupní řetězec, na kterém provádíme hledání shody s regulárním výrazem.
vzor: Představuje regulární výraz, pro který řetězec testujeme.
match_type: Je to řetězec, který nám umožňuje upřesnit regulární výraz. K provádění porovnávání používá následující možné znaky.
Pojďme pochopit, jak můžeme tuto funkci použít v MySQL na různých příkladech.
Příklad
Následující příkaz vysvětluje základní příklad funkce REGEXP_LIKE v MySQL.
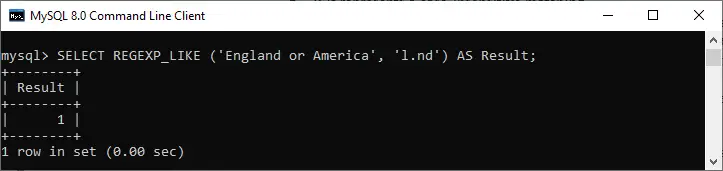
mysql> SELECT REGEXP_LIKE ('England or America', 'l.nd') AS Result;
V tomto příkladu může regulární výraz zadat libovolný znak namísto tečky. Proto zde získáme shodu. Tato funkce tedy vrací 1, aby označila shodu.
Níže uvedený příkaz je dalším příkladem, kdy vstupní řetězec neodpovídá danému regulárnímu výrazu.
mysql> SELECT REGEXP_LIKE ('MCA', 'BCA') AS Result;
Zde je výstup:
rozdíl mezi binárním stromem a binárním vyhledávacím stromem

Níže uvedený příkaz je dalším příkladem, kdy zadaný regulární výraz vyhledává zda řetězec končí danými znaky nebo ne:
mysql> SELECT REGEXP_LIKE ('England Netherland Scotland', 'and$') AS Result;
Zde je výsledek:

Můžeme poskytnout další parametr pro upřesnění regulárního výrazu pomocí argumentů typu shody. Viz níže uvedený příklad, kde specifikujeme a citlivý na velká písmena a shoda bez rozlišení velkých a malých písmen:
mysql> SELECT REGEXP_LIKE ('India Indonesia', '^in', 'i') AS 'Case-Insensitive', REGEXP_LIKE ('India Indonesia', '^in', 'c') AS 'Case-Sensitive';
Zde je výsledek:
