Logistická regrese je řízený algoritmus strojového učení používá klasifikační úkoly kde cílem je předpovědět pravděpodobnost, že instance patří do dané třídy nebo ne. Logistická regrese je statistický algoritmus, který analyzuje vztah mezi dvěma datovými faktory. Článek zkoumá základy logistické regrese, její typy a implementace.
Obsah
- Co je logistická regrese?
- Logistická funkce – Sigmoidní funkce
- Typy logistické regrese
- Předpoklady logistické regrese
- Jak funguje logistická regrese?
- Implementace kódu pro logistickou regresi
- Precision-Recall Tradeoff v nastavení prahu logistické regrese
- Jak vyhodnotit model logistické regrese?
- Rozdíly mezi lineární a logistickou regresí
Co je logistická regrese?
Pro binární se používá logistická regrese klasifikace kde používáme sigmoidní funkce , který bere vstup jako nezávislé proměnné a vytváří hodnotu pravděpodobnosti mezi 0 a 1.
Například máme dvě třídy Class 0 a Class 1, pokud je hodnota logistické funkce pro vstup větší než 0,5 (prahová hodnota), pak patří do třídy 1, jinak patří do třídy 0. Říká se tomu regrese, protože je rozšířením lineární regrese ale používá se hlavně pro klasifikační problémy.
Klíčové body:
- Logistická regrese předpovídá výstup kategorické závislé proměnné. Proto musí být výsledkem kategorická nebo diskrétní hodnota.
- Může to být buď Ano nebo Ne, 0 nebo 1, pravda nebo nepravda atd., ale místo přesné hodnoty jako 0 a 1 udává pravděpodobnostní hodnoty, které leží mezi 0 a 1.
- V logistické regresi místo proložení regresní přímky proložíme logistickou funkci ve tvaru S, která předpovídá dvě maximální hodnoty (0 nebo 1).
Logistická funkce – Sigmoidní funkce
- Sigmoidní funkce je matematická funkce používaná k mapování předpokládaných hodnot na pravděpodobnosti.
- Mapuje jakoukoli reálnou hodnotu na jinou hodnotu v rozsahu 0 až 1. Hodnota logistické regrese musí být mezi 0 a 1, která nemůže překročit tento limit, takže tvoří křivku jako tvar S.
- Křivka tvaru S se nazývá sigmoidní funkce nebo logistická funkce.
- V logistické regresi používáme koncept prahové hodnoty, která definuje pravděpodobnost buď 0, nebo 1. Například hodnoty nad prahovou hodnotou mají tendenci k 1 a hodnota pod prahovými hodnotami má tendenci k 0.
Typy logistické regrese
Na základě kategorií lze logistickou regresi rozdělit do tří typů:
- Binomický: V binomické logistické regresi mohou existovat pouze dva možné typy závislých proměnných, jako je 0 nebo 1, Pass nebo Fail atd.
- Multinomiální: V multinomické logistické regresi mohou existovat 3 nebo více možných neuspořádaných typů závislé proměnné, jako je kočka, psi nebo ovce.
- řadové: V ordinální logistické regresi mohou existovat 3 nebo více možných uspořádaných typů závislých proměnných, jako je nízká, střední nebo vysoká.
Předpoklady logistické regrese
Prozkoumáme předpoklady logistické regrese, protože pochopení těchto předpokladů je důležité pro zajištění toho, že používáme vhodnou aplikaci modelu. Předpoklad zahrnuje:
- Nezávislá pozorování: Každé pozorování je nezávislé na druhém. což znamená, že mezi vstupními proměnnými neexistuje žádná korelace.
- Binární závislé proměnné: Předpokládá se, že závislá proměnná musí být binární nebo dichotomická, což znamená, že může nabývat pouze dvou hodnot. Pro více než dvě kategorie se používají funkce SoftMax.
- Vztah linearity mezi nezávislými proměnnými a logaritmickými pravděpodobnostmi: Vztah mezi nezávislými proměnnými a logaritmickými pravděpodobnostmi závislé proměnné by měl být lineární.
- Žádné odlehlé hodnoty: V datové sadě by neměly být žádné odlehlé hodnoty.
- Velká velikost vzorku: Velikost vzorku je dostatečně velká
Terminologie používané v logistické regresi
Zde jsou některé běžné termíny zahrnuté v logistické regresi:
- Nezávislé proměnné: Vstupní charakteristiky nebo predikční faktory použité na predikce závislé proměnné.
- Závislá proměnná: Cílová proměnná v modelu logistické regrese, kterou se snažíme predikovat.
- Logistická funkce: Vzorec používaný k vyjádření vztahu nezávislých a závislých proměnných k sobě navzájem. Logistická funkce transformuje vstupní proměnné na hodnotu pravděpodobnosti mezi 0 a 1, která představuje pravděpodobnost, že závislá proměnná bude 1 nebo 0.
- šance: Je to poměr něčeho, co se děje, k něčemu, co se nevyskytuje. liší se od pravděpodobnosti, protože pravděpodobnost je poměr něčeho, co se stane, ke všemu, co by se mohlo stát.
- Log-kurzy: Log-odds, také známý jako logit funkce, je přirozený logaritmus pravděpodobnosti. V logistické regresi jsou logaritmické pravděpodobnosti závislé proměnné modelovány jako lineární kombinace nezávislých proměnných a průsečíku.
- Součinitel: Odhadované parametry modelu logistické regrese ukazují, jak spolu nezávislé a závislé proměnné souvisí.
- Zachytit: Konstantní člen v modelu logistické regrese, který představuje logaritmickou pravděpodobnost, když jsou všechny nezávislé proměnné rovny nule.
- Odhad maximální pravděpodobnosti : Metoda použitá k odhadu koeficientů modelu logistické regrese, která maximalizuje pravděpodobnost pozorování dat daného modelu.
Jak funguje logistická regrese?
Logistický regresní model transformuje lineární regrese funkce výstup spojité hodnoty na výstup kategorické hodnoty pomocí sigmoidní funkce, která mapuje jakoukoli množinu vstupů nezávislých proměnných s reálnou hodnotou na hodnotu mezi 0 a 1. Tato funkce je známá jako logistická funkce.
Nechť nezávislé vstupní vlastnosti jsou:
Java řetězec ve srovnání
a závislá proměnná je Y mající pouze binární hodnotu, tj. 0 nebo 1.
poté aplikujte multilineární funkci na vstupní proměnné X.
Tady
cokoli jsme diskutovali výše, je lineární regrese .
Sigmoidní funkce
Nyní používáme sigmoidní funkce kde vstup bude z a najdeme pravděpodobnost mezi 0 a 1. tj. předpovězené y.
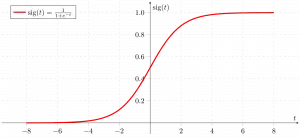
Sigmoidní funkce
Jak je uvedeno výše, funkce sigmoid obrázku převádí data spojité proměnné na pravděpodobnost tedy mezi 0 a 1.
sigma(z) inklinuje k 1 asz ightarrowinfty sigma(z) inklinuje k 0 asz ightarrow-infty sigma(z) je vždy ohraničena mezi 0 a 1
kde pravděpodobnost, že jde o třídu, lze měřit jako:
Logistická regresní rovnice
Lichý je poměr mezi tím, že se něco stane, k něčemu, co se nestane. liší se od pravděpodobnosti, protože pravděpodobnost je poměr něčeho, co se stane, ke všemu, co by se mohlo stát. tak to bude divné:
příkaz java switch
Použití přirozeného log na liché. pak log lichý bude:
pak konečná logistická regresní rovnice bude:
Pravděpodobnostní funkce pro logistickou regresi
Předpokládané pravděpodobnosti budou:
- pro y=1 Předpovězené pravděpodobnosti budou: p(X;b,w) = p(x)
- pro y = 0 Předpokládané pravděpodobnosti budou: 1-p(X;b,w) = 1-p(x)
urfi javed
Odebírání přírodních polen na obě strany
Gradient logaritmické pravděpodobnostní funkce
Abychom našli odhady maximální pravděpodobnosti, rozlišujeme w.r.t w,
Implementace kódu pro logistickou regresi
Binomická logistická regrese:
Cílová proměnná může mít pouze 2 možné typy: 0 nebo 1, což může představovat výhru vs prohra, projít vs selhání, mrtvý vs živý atd., v tomto případě se používají sigmoidní funkce, o kterých již byla řeč výše.
Import potřebných knihoven na základě požadavku modelu. Tento kód Pythonu ukazuje, jak používat datovou sadu o rakovině prsu k implementaci modelu logistické regrese pro klasifikaci.
Python3 # import the necessary libraries from sklearn.datasets import load_breast_cancer from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score # load the breast cancer dataset X, y = load_breast_cancer(return_X_y=True) # split the train and test dataset X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=23) # LogisticRegression clf = LogisticRegression(random_state=0) clf.fit(X_train, y_train) # Prediction y_pred = clf.predict(X_test) acc = accuracy_score(y_test, y_pred) print('Logistic Regression model accuracy (in %):', acc*100)> Výstup :
Přesnost modelu logistické regrese (v %): 95,6140350877193
Multinomická logistická regrese:
Cílová proměnná může mít 3 nebo více možných typů, které nejsou uspořádané (tj. typy nemají kvantitativní význam), jako je onemocnění A versus onemocnění B versus onemocnění C.
V tomto případě se místo sigmoidní funkce použije funkce softmax. Funkce Softmax pro třídy K bude:
Tady, K představuje počet prvků ve vektoru z a i, j iteruje přes všechny prvky ve vektoru.
Pak pravděpodobnost pro třídu c bude:
V multinomické logistické regresi může mít výstupní proměnná více než dva možné diskrétní výstupy . Zvažte digitální datovou sadu.
Python3 from sklearn.model_selection import train_test_split from sklearn import datasets, linear_model, metrics # load the digit dataset digits = datasets.load_digits() # defining feature matrix(X) and response vector(y) X = digits.data y = digits.target # splitting X and y into training and testing sets X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=1) # create logistic regression object reg = linear_model.LogisticRegression() # train the model using the training sets reg.fit(X_train, y_train) # making predictions on the testing set y_pred = reg.predict(X_test) # comparing actual response values (y_test) # with predicted response values (y_pred) print('Logistic Regression model accuracy(in %):', metrics.accuracy_score(y_test, y_pred)*100)> Výstup:
Přesnost modelu logistické regrese (v %): 96,52294853963839
Jak vyhodnotit model logistické regrese?
Logistický regresní model můžeme vyhodnotit pomocí následujících metrik:
- Přesnost: Přesnost poskytuje podíl správně klasifikovaných případů.
Accuracy = frac{True , Positives + True , Negatives}{Total}
- Přesnost: Přesnost se zaměřuje na přesnost pozitivních předpovědí.
Precision = frac{True , Positives }{True, Positives + False , Positives}
- Vyvolání (citlivost nebo skutečně pozitivní míra): Odvolání měří podíl správně předpovězených pozitivních případů mezi všemi skutečnými pozitivními případy.
Recall = frac{ True , Positives}{True, Positives + False , Negatives}
- Skóre F1: skóre F1 je harmonický průměr přesnosti a zapamatování.
F1 , Score = 2 * frac{Precision * Recall}{Precision + Recall}
- Oblast pod křivkou provozní charakteristiky přijímače (AUC-ROC): Křivka ROC vykresluje skutečnou míru pozitivních výsledků proti míře falešných pozitivních výsledků při různých prahových hodnotách. AUC-ROC měří plochu pod touto křivkou a poskytuje souhrnnou míru výkonu modelu napříč různými klasifikačními prahy.
- Oblast pod křivkou přesného vyvolání (AUC-PR): Podobně jako AUC-ROC, AUC-PR měří plochu pod křivkou přesnosti-vyvolání a poskytuje souhrn výkonu modelu napříč různými kompromisy přesnosti-vybavení.
Precision-Recall Tradeoff v nastavení prahu logistické regrese
Logistická regrese se stává klasifikační technikou pouze tehdy, když se do obrazu dostane rozhodovací práh. Nastavení prahové hodnoty je velmi důležitým aspektem logistické regrese a závisí na samotném klasifikačním problému.
Rozhodnutí o hodnotě prahové hodnoty je výrazně ovlivněno hodnotami přesnost a zapamatovatelnost. V ideálním případě chceme, aby přesnost i zapamatování byly 1, ale to je zřídka.
V případě a Precision-Recall kompromis , používáme k rozhodnutí o prahové hodnotě následující argumenty:
- Nízká přesnost/vysoké vyvolání: V aplikacích, kde chceme snížit počet falešně negativních výsledků, aniž bychom museli nutně snížit počet falešně pozitivních výsledků, volíme rozhodovací hodnotu, která má nízkou hodnotu Precision nebo vysokou hodnotu Recall. Například v aplikaci pro diagnostiku rakoviny nechceme, aby byl žádný postižený pacient klasifikován jako nepostižený, aniž bychom věnovali velkou pozornost tomu, zda je pacientovi rakovina diagnostikována nesprávně. Je tomu tak proto, že nepřítomnost rakoviny může být zjištěna dalšími lékařskými chorobami, ale přítomnost choroby nemůže být zjištěna u již odmítnutého kandidáta.
- Vysoká přesnost/Nízké vyvolání: V aplikacích, kde chceme snížit počet falešně pozitivních výsledků, aniž bychom museli nutně snížit počet falešně negativních výsledků, volíme rozhodovací hodnotu, která má vysokou hodnotu Precision nebo nízkou hodnotu Recall. Pokud například klasifikujeme zákazníky, zda budou reagovat pozitivně nebo negativně na personalizovanou reklamu, chceme si být naprosto jisti, že zákazník na reklamu zareaguje pozitivně, protože v opačném případě může negativní reakce způsobit ztrátu potenciálního prodeje zákazník.
Rozdíly mezi lineární a logistickou regresí
Rozdíl mezi lineární regresí a logistickou regresí je v tom, že výstup lineární regrese je spojitá hodnota, která může být jakákoli, zatímco logistická regrese předpovídá pravděpodobnost, že instance patří do dané třídy nebo ne.
jak třídit seznam polí v jazyce Java
Lineární regrese | Logistická regrese |
|---|---|
Lineární regrese se používá k predikci spojité závislé proměnné pomocí daného souboru nezávislých proměnných. | Logistická regrese se používá k predikci kategorické závislé proměnné pomocí daného souboru nezávislých proměnných. |
Lineární regrese se používá k řešení regresního problému. | Používá se pro řešení klasifikačních problémů. |
V tomto předpovídáme hodnotu spojitých proměnných | V tomto předpovídáme hodnoty kategoriálních proměnných |
V tomto najdeme nejvhodnější linii. | V tom najdeme S-Curve. |
Pro odhad přesnosti se používá metoda odhadu nejmenších čtverců. | Pro odhad přesnosti se používá metoda odhadu maximální věrohodnosti. |
Výstupem musí být spojitá hodnota, jako je cena, stáří atd. | Výstup musí mít kategorickou hodnotu, například 0 nebo 1, Ano nebo ne atd. převod int na řetězec v jazyce Java |
To vyžadovalo lineární vztah mezi závislými a nezávislými proměnnými. | Nevyžaduje lineární vztah. |
Mezi nezávislými proměnnými může být kolinearita. | Mezi nezávislými proměnnými by neměla být kolinearita. |
Logistická regrese – často kladené otázky (FAQ)
Co je logistická regrese ve strojovém učení?
Logistická regrese je statistická metoda pro vývoj modelů strojového učení s binárně závislými proměnnými, tedy binárními. Logistická regrese je statistická technika používaná k popisu dat a vztahu mezi jednou závislou proměnnou a jednou nebo více nezávislými proměnnými.
Jaké jsou tři typy logistické regrese?
Logistická regrese se dělí na tři typy: binární, multinomiální a ordinální. Liší se provedením i teorií. Binární regrese se zabývá dvěma možnými výsledky: ano nebo ne. Multinomická logistická regrese se používá, když existují tři nebo více hodnot.
Proč se pro klasifikační problém používá logistická regrese?
Logistická regrese se snadněji implementuje, interpretuje a trénuje. Velmi rychle klasifikuje neznámé záznamy. Když je datová sada lineárně oddělitelná, funguje dobře. Koeficienty modelu lze interpretovat jako indikátory důležitosti rysů.
Co odlišuje logistickou regresi od lineární regrese?
Zatímco lineární regrese se používá k predikci kontinuálních výsledků, logistická regrese se používá k predikci pravděpodobnosti, že pozorování spadá do určité kategorie. Logistická regrese využívá logistickou funkci ve tvaru S k mapování předpokládaných hodnot mezi 0 a 1.
Jakou roli hraje logistická funkce v logistické regresi?
Logistická regrese spoléhá na logistickou funkci, která převádí výstup na skóre pravděpodobnosti. Toto skóre představuje pravděpodobnost, že pozorování patří do určité třídy. Křivka ve tvaru S pomáhá při stanovení prahových hodnot a kategorizaci dat do binárních výstupů.