Jeden důležitý aspekt Strojové učení je hodnocení modelu. Musíte mít nějaký mechanismus pro vyhodnocení vašeho modelu. Zde se objevují tyto výkonnostní metriky, které nám dávají představu o tom, jak dobrý model je. Pokud jste obeznámeni s některými základy Strojové učení pak jste se jistě setkali s některými z těchto metrik, jako je přesnost, přesnost, zapamatovatelnost, auc-roc atd., které se obecně používají pro klasifikační úlohy. V tomto článku do hloubky prozkoumáme jednu takovou metriku, kterou je křivka AUC-ROC.
Obsah
- Co je křivka AUC-ROC?
- Klíčové pojmy používané v AUC a ROC křivce
- Vztah mezi citlivostí, specificitou, FPR a prahem.
- Jak AUC-ROC funguje?
- Kdy bychom měli použít hodnotící metriku AUC-ROC?
- Spekulace o výkonu modelu
- Pochopení křivky AUC-ROC
- Implementace pomocí dvou různých modelů
- Jak použít ROC-AUC pro vícetřídní model?
- Časté dotazy pro AUC ROC Curve ve strojovém učení
Co je křivka AUC-ROC?
Křivka AUC-ROC neboli oblast pod křivkou provozní charakteristiky přijímače je grafickým znázorněním výkonu binárního klasifikačního modelu při různých prahových hodnotách klasifikace. Běžně se používá ve strojovém učení k posouzení schopnosti modelu rozlišit dvě třídy, typicky pozitivní třídu (např. přítomnost nemoci) a negativní třídu (např. nepřítomnost nemoci).
Nejprve pochopíme význam těchto dvou pojmů ROC a AUC .
- ROC : Provozní charakteristiky přijímače
- AUC : Oblast pod křivkou
Křivka provozních charakteristik přijímače (ROC).
ROC je zkratka pro Receiver Operating Characteristics a ROC křivka je grafickým znázorněním účinnosti modelu binární klasifikace. Vykresluje skutečnou míru pozitivních výsledků (TPR) vs. míru falešných pozitivních výsledků (FPR) při různých prahových hodnotách klasifikace.
Oblast pod křivkou Křivka (AUC):
AUC je zkratka pro oblast pod křivkou a křivka AUC představuje plochu pod křivkou ROC. Měří celkový výkon modelu binární klasifikace. Protože se TPR i FPR pohybují mezi 0 až 1, bude tedy plocha vždy ležet mezi 0 a 1 a Vyšší hodnota AUC znamená lepší výkon modelu. Naším hlavním cílem je maximalizovat tuto oblast, abychom měli nejvyšší TPR a nejnižší FPR na daném prahu. AUC měří pravděpodobnost, že model přiřadí náhodně vybrané pozitivní instanci vyšší předpokládanou pravděpodobnost ve srovnání s náhodně zvolenou negativní instancí.
Představuje pravděpodobnost pomocí kterého náš model dokáže rozlišit mezi dvěma třídami přítomnými v našem cíli.
Metrika hodnocení klasifikace ROC-AUC
Klíčové pojmy používané v AUC a ROC křivce
1. TPR a FPR
Toto je nejběžnější definice, se kterou byste se setkali, když jste Google AUC-ROC. Křivka ROC je v podstatě graf, který ukazuje výkon klasifikačního modelu na všech možných prahových hodnotách (práh je konkrétní hodnota, za kterou říkáte, že bod patří do určité třídy). Křivka je vykreslena mezi dvěma parametry
- TPR – Skutečná pozitivní míra
- FPR – Falešně pozitivní sazba
Než pochopíme, TPR a FPR se rychle podívejme na matoucí matice .
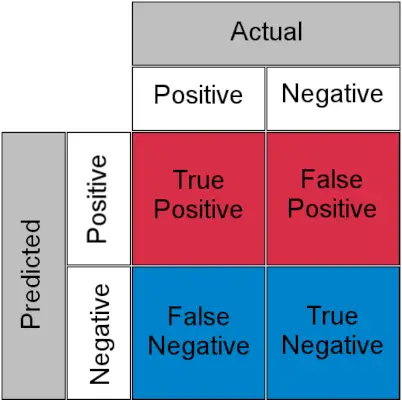
Matice zmatků pro klasifikační úkol
- Skutečně pozitivní : Skutečně pozitivní a předpovězeno jako pozitivní
- Skutečně negativní : Skutečný zápor a předpovězeno jako záporné
- Falešně pozitivní (chyba typu I) : Skutečný negativní, ale předpovězený jako pozitivní
- Falešně negativní (chyba typu II) : Skutečně pozitivní, ale předpovězeno jako negativní
Jednoduše řečeno, můžete nazvat falešně pozitivní a falešný poplach a falešně negativní a slečna, minout . Nyní se podívejme na to, co jsou TPR a FPR.
2. Citlivost / True Positive Rate / Recall
TPR/Recall/Sensitivity je v zásadě poměr pozitivních příkladů, které jsou správně identifikovány. Představuje schopnost modelu správně identifikovat pozitivní instance a počítá se následovně:

Sensitivity/Recall/TPR měří podíl skutečných pozitivních případů, které model správně identifikuje jako pozitivní.
3. Falešně pozitivní míra
FPR je poměr negativních příkladů, které jsou nesprávně klasifikovány.

4. Specifičnost
Specifičnost měří podíl skutečných negativních případů, které model správně identifikuje jako negativní. Představuje schopnost modelu správně identifikovat negativní instance

A jak již bylo řečeno dříve, ROC není nic jiného než graf mezi TPR a FPR napříč všemi možnými prahy a AUC je celá oblast pod touto křivkou ROC.
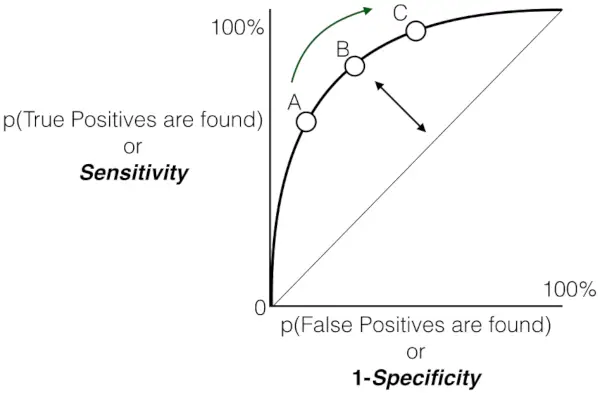
Graf citlivosti versus falešně pozitivní frekvence
Vztah mezi citlivostí, specificitou, FPR a prahem .
Citlivost a specifičnost:
- Inverzní vztah: senzitivita a specificita mají inverzní vztah. Když se jeden zvyšuje, druhý má tendenci klesat. To odráží přirozený kompromis mezi skutečnými pozitivními a skutečnými negativními sazbami.
- Ladění pomocí prahu: Úpravou prahové hodnoty můžeme řídit rovnováhu mezi citlivostí a specificitou. Nižší prahové hodnoty vedou k vyšší senzitivitě (více pravdivě pozitivních výsledků) na úkor specificity (více falešně pozitivních výsledků). Naopak zvýšení prahu zvyšuje specificitu (méně falešně pozitivních výsledků), ale obětuje citlivost (více falešně negativních výsledků).
Prahová a falešně pozitivní míra (FPR):
- Připojení FPR a specificity: Falešně pozitivní frekvence (FPR) je prostě doplněk specifičnosti (FPR = 1 – specificita). To znamená přímý vztah mezi nimi: vyšší specificita znamená nižší FPR a naopak.
- Změny FPR s TPR: Podobně, jak jste si všimli, jsou také propojeny True Positive Rate (TPR) a FPR. Zvýšení TPR (více pravdivých pozitivních výsledků) obecně vede ke zvýšení FPR (více falešně pozitivních výsledků). Naopak pokles TPR (méně skutečných pozitivních výsledků) má za následek pokles FPR (méně falešně pozitivních výsledků)
Jak AUC-ROC funguje?
Podívali jsme se na geometrickou interpretaci, ale myslím, že to stále nestačí na rozvíjení intuice, co vlastně znamená 0,75 AUC, nyní se podívejme na AUC-ROC z pravděpodobnostního hlediska. Pojďme si nejprve promluvit o tom, co AUC dělá, a později na tom postavíme naše porozumění
AUC měří, jak dobře je model schopen mezi nimi rozlišovat třídy.
AUC 0,75 by ve skutečnosti znamenalo, že řekněme, že vezmeme dva datové body patřící do samostatných tříd, pak je 75% šance, že je model bude schopen segregovat nebo je správně seřadit, tj. kladný bod má vyšší pravděpodobnost predikce než záporný třída. (za předpokladu vyšší pravděpodobnosti predikce znamená, že bod by v ideálním případě patřil do pozitivní třídy). Zde je malý příklad, aby bylo vše jasnější.
Index | Třída | Pravděpodobnost |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Zde máme 6 bodů, kde P1, P2 a P5 patří do třídy 1 a P3, P4 a P6 patří do třídy 0 a odpovídáme předpovězeným pravděpodobností ve sloupci Pravděpodobnost, jak jsme řekli, když vezmeme dva body patřící do samostatné tříd pak jaká je pravděpodobnost, že je modelová hodnost seřadí správně.
Vezmeme všechny možné dvojice tak, že jeden bod patří do třídy 1 a druhý do třídy 0, budeme mít celkem 9 takových dvojic níže je všech těchto 9 možných dvojic.
Pár | je správně |
|---|---|
(P1,P3) | Ano |
(P1, P4) | Ano |
(P1, P6) | Ano |
(P2,P3) | Ano |
(P2, P4) | Ano |
(P2, P6) | Ano |
(P3, P5) | Ne |
(P4, P5) | Ne |
(P5, P6) | Ano |
Zde sloupec Správně říká, zda je zmíněný pár správně seřazen na základě předpokládané pravděpodobnosti, tj. bod třídy 1 má vyšší pravděpodobnost než bod třídy 0, v 7 z těchto 9 možných párů je třída 1 zařazena výše než třída 0, nebo můžeme říci, že existuje 77% šance, že pokud vyberete pár bodů patřících do samostatných tříd, model je bude schopen správně rozlišit. Nyní si myslím, že za tímto číslem AUC můžete mít trochu intuice, jen abychom vyjasnili jakékoli další pochybnosti, ověřte to pomocí implementace AUC-ROC společnosti Scikit learns.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Výstup:
AUC for our sample data is 0.778>
Kdy bychom měli použít hodnotící metriku AUC-ROC?
Existují oblasti, kde použití ROC-AUC nemusí být ideální. V případech, kdy je soubor dat vysoce nevyvážený, křivka ROC může poskytnout příliš optimistické hodnocení výkonu modelu . Toto zkreslení optimismu vzniká, protože míra falešně pozitivních (FPR) křivky ROC může být velmi malá, když je počet skutečných negativů velký.
Při pohledu na vzorec FPR,

pozorujeme ,
- Třída Negative je ve většině, ve jmenovateli FPR dominují True Negatives, kvůli nimž se FPR stává méně citlivou na změny v predikcích souvisejících s menšinovou třídou (třída pozitivní).
- Křivky ROC mohou být vhodné, když jsou náklady na falešně pozitivní a falešné negativy vyvážené a soubor dat není výrazně nevyvážený.
v tom případě Precision-Recall Curves mohou být použity, které poskytují alternativní vyhodnocovací metriku, která je vhodnější pro nevyvážené datové sady, se zaměřením na výkon klasifikátoru s ohledem na pozitivní (menšinovou) třídu.
Spekulace o výkonu modelu
- Vysoká AUC (blízká 1) indikuje vynikající rozlišovací schopnost. To znamená, že model je účinný při rozlišování mezi těmito dvěma třídami a jeho předpovědi jsou spolehlivé.
- Nízká AUC (blízká 0) naznačuje špatný výkon. V tomto případě má model potíže s rozlišením mezi pozitivními a negativními třídami a jeho předpovědi nemusí být důvěryhodné.
- AUC kolem 0,5 znamená, že model v podstatě dělá náhodné odhady. Nevykazuje žádnou schopnost oddělit třídy, což naznačuje, že model se z dat neučí žádné smysluplné vzorce.
Pochopení křivky AUC-ROC
V ROC křivce osa x obvykle představuje falešně pozitivní míru (FPR) a osa y představuje skutečnou pozitivní míru (TPR), také známou jako citlivost nebo vyvolání. Vyšší hodnota na ose x (směrem doprava) na křivce ROC tedy znamená vyšší míru falešně pozitivních výsledků a vyšší hodnota na ose y (směrem nahoru) znamená vyšší míru skutečně pozitivních výsledků. Křivka ROC je grafická znázornění kompromisu mezi mírou skutečně pozitivních a mírou falešných pozitivních výsledků při různých prahových hodnotách. Ukazuje výkon klasifikačního modelu při různých klasifikačních prahových hodnotách. AUC (Area Under the Curve) je souhrnným měřítkem výkonnosti ROC křivky. Volba prahové hodnoty závisí na konkrétních požadavcích problému, který se snažíte vyřešit, a na kompromisu mezi falešně pozitivními a falešně negativními výsledky. přijatelné ve vašem kontextu.
- Pokud chcete upřednostnit snížení falešně pozitivních výsledků (minimalizace šancí označit něco jako pozitivní, když tomu tak není), můžete zvolit práh, který povede k nižší míře falešných pozitivních výsledků.
- Pokud chcete upřednostnit zvýšení skutečných pozitivních výsledků (zachycení co největšího počtu skutečných pozitivních výsledků), můžete zvolit práh, který povede k vyšší míře skutečně pozitivních výsledků.
Podívejme se na příklad, který ilustruje, jak se ROC křivky generují pro různé prahy a jak konkrétní práh odpovídá matici matice. Předpokládejme, že máme a binární klasifikační problém s modelem předpovídajícím, zda je e-mail spam (pozitivní) nebo není spam (negativní).
Vezměme si hypotetická data,
Skutečné štítky: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Předpokládané pravděpodobnosti: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
Případ 1: Práh = 0,5
Skutečné štítky | Předpokládané pravděpodobnosti | Předpokládané štítky |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matice zmatků na základě výše uvedených předpovědí
| Předpověď = 0 | Předpověď = 1 |
|---|---|---|
Skutečné = 0 | TP=4 java převést celé číslo na řetězec | FN=1 |
Skutečnost = 1 | FP=0 | TN=5 |
v souladu s tím
- Skutečná pozitivní míra (TPR) :
Podíl skutečných pozitiv správně identifikovaných klasifikátorem je

- Falešně pozitivní míra (FPR) :
Podíl skutečných negativů nesprávně klasifikovaných jako pozitivní



Takže na prahu 0,5:
- Skutečná pozitivní míra (citlivost): 0,8
- Míra falešně pozitivních výsledků: 0
Interpretace je taková, že model na tomto prahu správně identifikuje 80 % skutečných pozitiv (TPR), ale nesprávně klasifikuje 0 % skutečných negativ jako pozitivní (FPR).
Podle toho pro různé prahové hodnoty dostaneme,
Případ 2: Práh = 0,7
Skutečné štítky | Předpokládané pravděpodobnosti | Předpokládané štítky |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Matice zmatků na základě výše uvedených předpovědí
| Předpověď = 0 | Předpověď = 1 |
|---|---|---|
Skutečné = 0 | TP=5 | FN=0 |
Skutečnost = 1 | FP=2 | TN=3 |
v souladu s tím
- Skutečná pozitivní míra (TPR) :
Podíl skutečných pozitiv správně identifikovaných klasifikátorem je

- Falešně pozitivní míra (FPR) :
Podíl skutečných negativů nesprávně klasifikovaných jako pozitivní



Případ 3: Práh = 0,4
Skutečné štítky | Předpokládané pravděpodobnosti | Předpokládané štítky |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matice zmatků na základě výše uvedených předpovědí
| Předpověď = 0 | Předpověď = 1 |
|---|---|---|
Skutečné = 0 | TP = 4 | FN=1 |
Skutečnost = 1 | FP=0 | TN=5 |
v souladu s tím
- Skutečná pozitivní míra (TPR) :
Podíl skutečných pozitiv správně identifikovaných klasifikátorem je
- Falešně pozitivní míra (FPR) :
Podíl skutečných negativů nesprávně klasifikovaných jako pozitivní
Případ 4: Práh = 0,2
Skutečné štítky | Předpokládané pravděpodobnosti | Předpokládané štítky |
|---|---|---|
| 1 | 0,8 | 1 |
| 0 | 0,3 | 1 |
| 1 | 0,6 | 1 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 1 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 1 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Matice zmatků na základě výše uvedených předpovědí
| Předpověď = 0 | Předpověď = 1 |
|---|---|---|
Skutečné = 0 | TP=2 | FN=3 |
Skutečnost = 1 | FP=0 | TN=5 |
v souladu s tím
- Skutečná pozitivní míra (TPR) :
Podíl skutečných pozitiv správně identifikovaných klasifikátorem je

- Falešně pozitivní míra (FPR) :
Podíl skutečných negativů nesprávně klasifikovaných jako pozitivní

Případ 5: Práh = 0,85
Skutečné štítky | Předpokládané pravděpodobnosti | Předpokládané štítky |
|---|---|---|
| 1 | 0,8 | 0 |
| 0 | 0,3 | 0 |
| 1 | 0,6 | 0 |
| 0 | 0,2 | 0 |
| 1 | 0,7 | 0 |
| 1 | 0,9 | 1 |
| 0 | 0,4 | 0 |
| 0 | 0,1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Matice zmatků na základě výše uvedených předpovědí
| Předpověď = 0 | Předpověď = 1 |
|---|---|---|
Skutečné = 0 | TP=5 | FN=0 |
Skutečnost = 1 | FP=4 | TN=1 |
v souladu s tím
- Skutečná pozitivní míra (TPR) :
Podíl skutečných pozitiv správně identifikovaných klasifikátorem je
- Falešně pozitivní míra (FPR) :
Podíl skutečných negativů nesprávně klasifikovaných jako pozitivní


Na základě výše uvedeného výsledku vyneseme ROC křivku
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Výstup:
Z grafu vyplývá, že:
- Šedá přerušovaná čára představuje scénář nejhoršího případu, kde jsou předpovědi modelu, tj. TPR jsou FPR, stejné. Tato diagonální čára je považována za nejhorší scénář, který ukazuje stejnou pravděpodobnost falešně pozitivních a falešně negativních výsledků.
- Jakmile se body odchýlí od linie náhodného odhadu směrem k levému hornímu rohu, výkon modelu se zlepší.
- Oblast pod křivkou (AUC) je kvantitativním měřítkem rozlišovací schopnosti modelu. Vyšší hodnota AUC, blížící se 1,0, ukazuje na vynikající výkon. Nejlepší možná hodnota AUC je 1,0, což odpovídá modelu, který dosahuje 100% senzitivity a 100% specificity.
Celkově slouží křivka provozní charakteristiky přijímače (ROC) jako grafické znázornění kompromisu mezi skutečnou pozitivní mírou (citlivostí) a falešně pozitivní mírou binárního klasifikačního modelu při různých prahových hodnotách rozhodování. Jak křivka ladně stoupá směrem k levému hornímu rohu, znamená to chvályhodnou schopnost modelu rozlišovat mezi pozitivními a negativními případy napříč řadou prahů spolehlivosti. Tato vzestupná trajektorie naznačuje zlepšený výkon, přičemž je dosaženo vyšší citlivosti při minimalizaci falešných poplachů. Anotované prahové hodnoty, označené jako A, B, C, D a E, nabízejí cenné poznatky o dynamickém chování modelu na různých úrovních spolehlivosti.
Implementace pomocí dvou různých modelů
Instalace knihoven
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Aby bylo možné trénovat Náhodný les a Logistická regrese Algoritmus vytváří umělá binární klasifikační data pro prezentaci jejich ROC křivek se skóre AUC.
Generování dat a dělení dat
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Pomocí rozdělovacího poměru 80-20 algoritmus vytváří umělá binární klasifikační data s 20 prvky, rozděluje je do tréninkových a testovacích sad a přiřazuje náhodné semeno, aby byla zajištěna reprodukovatelnost.
Školení různých modelů
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Pomocí pevného náhodného semene k zajištění opakovatelnosti metoda inicializuje a trénuje model logistické regrese na trénovací sadě. Podobným způsobem používá trénovací data a stejné náhodné semeno k inicializaci a trénování modelu Random Forest se 100 stromy.
Předpovědi
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Pomocí testovacích dat a vyškolených Logistická regrese kód předpovídá pravděpodobnost pozitivní třídy. Podobným způsobem s použitím testovacích dat používá trénovaný model Random Forest k vytvoření předpokládaných pravděpodobností pro pozitivní třídu.
Vytvoření datového rámce
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Pomocí testovacích dat kód vytvoří DataFrame nazvaný test_df se sloupci označenými True, Logistic a RandomForest a přidá pravdivé popisky a předpokládané pravděpodobnosti z modelů Random Forest a Logistic Regression.
Vykreslete ROC křivku pro modely
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Výstup:

Kód generuje graf s číslicemi 8 x 6 palců. Vypočítá křivku AUC a ROC pro každý model (náhodná lesní a logistická regrese) a poté vynese křivku ROC. The ROC křivka pro náhodné hádání je také znázorněno červenou přerušovanou čarou a pro vizualizaci jsou nastaveny popisky, nadpis a legenda.
Jak použít ROC-AUC pro vícetřídní model?
Pro nastavení více tříd můžeme jednoduše použít metodologii jedna vs všichni a pro každou třídu budete mít jednu křivku ROC. Řekněme, že máte čtyři třídy A, B, C a D, pak by existovaly křivky ROC a odpovídající hodnoty AUC pro všechny čtyři třídy, tj. jakmile by A byla jedna třída a kombinace B, C a D by byly ostatní třídy. , podobně B je jedna třída a A, C a D kombinované jako ostatní třídy atd.
Obecné kroky pro použití AUC-ROC v kontextu vícetřídního klasifikačního modelu jsou:
Metodika jedna proti všem:
- Pro každou třídu ve vašem problému s více třídami s ní zacházejte jako s pozitivní třídou, zatímco všechny ostatní třídy zkombinujte do negativní třídy.
- Trénujte binární klasifikátor pro každou třídu proti zbytku tříd.
Vypočítejte AUC-ROC pro každou třídu:
- Zde vyneseme ROC křivku pro danou třídu proti zbytku.
- Vyneste křivky ROC pro každou třídu do stejného grafu. Každá křivka představuje diskriminační výkon modelu pro konkrétní třídu.
- Prozkoumejte skóre AUC pro každou třídu. Vyšší skóre AUC ukazuje na lepší rozlišení pro danou konkrétní třídu.
Implementace AUC-ROC ve vícetřídní klasifikaci
Import knihoven
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Program vytváří umělá vícetřídní data, rozděluje je na trénovací a testovací sady a poté je používá One-vs-Restclassifier technika pro trénování klasifikátorů jak pro náhodný les, tak pro logistickou regresi. Nakonec vykresluje vícetřídní ROC křivky dvou modelů, aby ukázal, jak dobře rozlišují mezi různými třídami.
Generování dat a rozdělení
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Tři třídy a dvacet funkcí tvoří syntetická vícetřídní data vytvořená kódem. Po binarizaci štítků jsou data rozdělena do tréninkových a testovacích sad v poměru 80-20.
Tréninkové modely
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Program trénuje dva vícetřídní modely: model Random Forest se 100 odhady a model logistické regrese s One-vs-Rest přístup . S trénovací sadou dat jsou oba modely vybaveny.
Vynesení křivky AUC-ROC
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Výstup:

Křivky ROC a skóre AUC modelů náhodného lesa a logistické regrese jsou vypočteny kódem pro každou třídu. Vícetřídní ROC křivky jsou pak vyneseny do grafu, ukazující diskriminační výkon každé třídy a obsahují čáru, která představuje náhodné hádání. Výsledný graf nabízí grafické vyhodnocení klasifikační výkonnosti modelů.
Závěr
Ve strojovém učení se výkonnost binárních klasifikačních modelů posuzuje pomocí klíčové metriky zvané Area Under the Receiver Operating Characteristic (AUC-ROC). Napříč různými rozhodovacími prahy ukazuje, jak se vyměňuje citlivost a specificita. Větší diskriminaci mezi pozitivními a negativními případy obvykle vykazuje model s vyšším skóre AUC. Zatímco 0,5 znamená šanci, 1 znamená bezchybný výkon. Optimalizaci a výběr modelu napomáhají užitečné informace, které křivka AUC-ROC nabízí o schopnosti modelu rozlišovat mezi třídami. Při práci s nevyváženými datovými sadami nebo aplikacemi, kde falešně pozitivní a falešně negativní výsledky mají různé náklady, je to zvláště užitečné jako komplexní opatření.
Časté dotazy pro AUC ROC Curve ve strojovém učení
1. Co je křivka AUC-ROC?
Pro různé prahové hodnoty klasifikace je kompromis mezi skutečně pozitivní mírou (citlivostí) a mírou falešně pozitivních výsledků (specifita) graficky znázorněn křivkou AUC-ROC.
2. Jak vypadá dokonalá křivka AUC-ROC?
Oblast 1 na ideální křivce AUC-ROC by znamenala, že model dosahuje optimální citlivosti a specifity na všech prahových hodnotách.
3. Co znamená hodnota AUC 0,5?
AUC 0,5 znamená, že výkon modelu je srovnatelný s výkonem náhodné náhody. To naznačuje nedostatek rozlišovací schopnosti.
4. Lze AUC-ROC použít pro vícetřídní klasifikaci?
AUC-ROC se často používá na otázky týkající se binární klasifikace. Pro vícetřídní klasifikaci lze vzít v úvahu variace, jako je makroprůměr nebo mikroprůměr AUC.
5. Jak je křivka AUC-ROC užitečná při hodnocení modelu?
Schopnost modelu rozlišovat mezi třídami je komplexně shrnuta křivkou AUC-ROC. Při práci s nevyváženými datovými sadami je to zvláště užitečné.