Linuxový příkaz uniq se používá k odstranění všech opakujících se řádků ze souboru. Lze jej také použít k zobrazení počtu libovolných slov, pouze opakovaných řádků, ignorování znaků a porovnání konkrétních polí. Je to jeden z nejčastěji používaných příkazů v Linux Systém. Často se používá s příkaz řazení protože porovnává sousední znaky. Zahodí všechny identické řádky a zapíše výstup.
Syntax:
uniq [OPTION]... [INPUT [OUTPUT]]
Možnosti:
Některé užitečné možnosti příkazového řádku příkazu uniq jsou následující:
-c, --count: předponuje řádkům počtem výskytů.
-d, --opakované: používá se k tisku duplicitních řádků, jednoho pro každou skupinu.
-D: Používá se k tisku všech duplicitních řádků.
--all-repeated[=METODA]: Je velmi podobná volbě '-D', rozdíl mezi oběma možnostmi je v tom, že umožňuje oddělení skupin prázdným řádkem.
-f, --skip-fields=N: Používá se, aby se zabránilo srovnání prvních N polí.
--skupina[=METODA]: Slouží k zobrazení všech položek a odděluje skupiny prázdným řádkem.
-i, --ignore-case: Používá se k ignorování rozdílů při porovnávání.
-s, --skip-chars=N: Používá se k tomu, aby se zabránilo srovnání prvních N znaků.
-u, --unikátní: používá se k tisku jedinečných čar.
-z, --zakončeno nulou: Používá se pro oddělovač řádku je NUL a ne v režimu nového řádku.
.další java
-w, --check-chars=N: Používá se k porovnání nejvýše N znaků v řádcích.
--Pomoc: Používá se k zobrazení dokumentace nápovědy.
--verze: Slouží k zobrazení informací o verzi.
Příklady příkazu uniq
Podívejme se na následující příklady příkazu uniq:
int řetězec
- Odstraňte opakované řádky
- spočítat počet výskytů slova
- Zobrazte opakované řádky
- Zobrazte jedinečné čáry
- Ignorujte znaky ve srovnání
- Ignorujte pole ve srovnání
Odstraňte opakované řádky
Chcete-li ze souboru odstranit opakované řádky, proveďte základní příkaz uniq takto:
sort dupli.txt | uniq
Výše uvedený příkaz odstraní duplicitní řádky ze souboru 'dupli.txt.' Zvažte následující výstup:
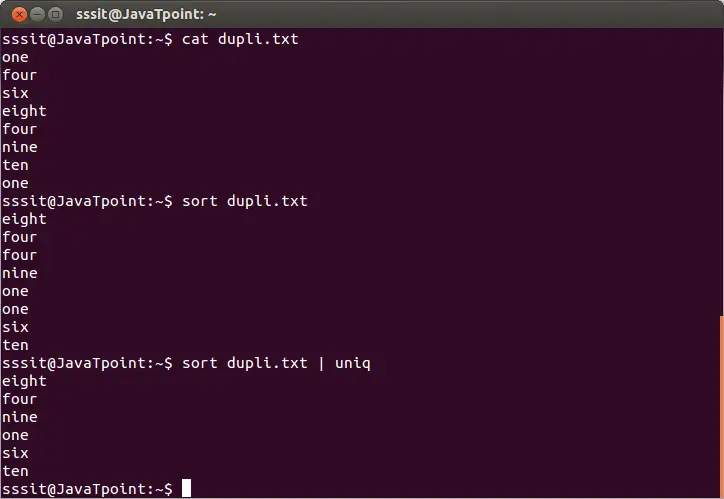
Z výše uvedeného výstupu jsou opakující se slova ignorována.
Spočítejte počet výskytů slova
Počet výskytů slova můžeme spočítat pomocí příkazu uniq. K počítání slova se používá volba '-c'. Proveďte jej následovně:
sort dupli.txt | uniq -c
Výše uvedený příkaz spočítá slova, která přicházejí v 'dupli.txt'. Zvažte následující výstup:

Z výše uvedeného výstupu příkaz 'sort dupli.txt | uniq -c' počítá, kolikrát se slovo opakuje.
Zobrazte opakované řádky
Volba '-d' se používá k zobrazení pouze opakujících se řádků. Zobrazí pouze řádky, které budou v souboru více než jednou, a zapíše výstup na standardní výstup. Zvažte níže uvedený příkaz:
sort dupli.txt | uniq -d
Výše uvedený příkaz zobrazí pouze opakované řádky. Zvažte následující výstup:

Zobrazte jedinečné čáry
Volba '-u' se používá k zobrazení pouze jedinečných řádků (které se neopakují). Zobrazí pouze řádky, které se vyskytují pouze jednou, a zapíše výsledek na standardní výstup. Zvažte níže uvedený příkaz:
sort dupli.txt | uniq -u
Výše uvedený příkaz zobrazí pouze jedinečné řádky ze souboru 'dupli.txt'. Zvažte následující výstup:

Ignorujte znaky ve srovnání
Volba '-s' se používá k ignorování znaků ve srovnání. Bude ignorovat zadaný počet znaků a zobrazí výsledek na standardní výstup. Zvažte níže uvedený příkaz:
sort dupli.txt | uniq -s 2
Výše uvedený příkaz bude ignorovat první dva znaky v porovnání ze souboru 'dupli.txt'. Zvažte následující výstup:

Ignorujte pole ve srovnání
Volba '-f' se používá k ignorování polí. Zvažte níže uvedený příkaz:
uniq -f 2 dupli2.txt
Výše uvedený příkaz nebude porovnávat první dvě pole ze souboru 'dupli2.txt'. Zvažte následující výstup:

Z výše uvedeného výstupu jsou první dvě pole přeskočena a zbývající všechna pole jsou porovnána ze souboru 'dupli2.txt'.