V rychle se vyvíjející éře umělé inteligence představuje Deep Learning základní kámen technologie, která přináší revoluci do toho, jak stroje rozumí, učí se a interagují s komplexními daty. Deep Learning AI ve své podstatě napodobuje složité neuronové sítě lidského mozku a umožňuje počítačům autonomně objevovat vzorce a rozhodovat se z obrovského množství nestrukturovaných dat. Toto transformativní pole přineslo průlomy v různých oblastech, od počítačového vidění a zpracování přirozeného jazyka až po zdravotnickou diagnostiku a autonomní řízení.
Úvod do hlubokého učení
Když se ponoříme do tohoto úvodního zkoumání Hlubokého učení, odhalíme jeho základní principy, aplikace a základní mechanismy, které umožňují strojům dosáhnout kognitivních schopností podobných lidem. Tento článek slouží jako brána k pochopení toho, jak Deep Learning přetváří průmysl, posouvá hranice toho, co je v AI možné, a připravuje cestu pro budoucnost, kde inteligentní systémy mohou vnímat, chápat a inovovat autonomně.
Co je hluboké učení?
Definice hlubokého učení je, že jde o větev strojové učení která je založena na architektuře umělé neuronové sítě. Umělá neuronová síť resp ANN využívá vrstvy vzájemně propojených uzlů nazývaných neurony, které spolupracují na zpracování a učení se ze vstupních dat.
V plně propojené hluboké neuronové síti je vstupní vrstva a jedna nebo více skrytých vrstev spojených jedna za druhou. Každý neuron přijímá vstup od neuronů předchozí vrstvy nebo vstupní vrstvy. Výstup jednoho neuronu se stává vstupem pro další neurony v další vrstvě sítě a tento proces pokračuje, dokud poslední vrstva neprodukuje výstup sítě. Vrstvy neuronové sítě transformují vstupní data řadou nelineárních transformací, což umožňuje síti naučit se komplexní reprezentace vstupních dat.
Rozsah hlubokého učení
Umělá inteligence s hlubokým učením se dnes stala jednou z nejoblíbenějších a nejviditelnějších oblastí strojového učení, a to díky jejímu úspěchu v různých aplikacích, jako je počítačové vidění, zpracování přirozeného jazyka a zesílené učení.
linkedlist a arraylist
Hluboké učení AI lze použít pro strojové učení pod dohledem, bez dozoru i pro posílení. používá různé způsoby, jak je zpracovat.
- Strojové učení pod dohledem: Strojové učení pod dohledem je strojové učení technika, ve které se neuronová síť učí předpovídat nebo klasifikovat data na základě označených datových souborů. Zde zadáme obě vstupní funkce spolu s cílovými proměnnými. neuronová síť se učí předpovídat na základě ceny nebo chyby, která pochází z rozdílu mezi předpokládaným a skutečným cílem, tento proces je známý jako backpropagation. Algoritmy hlubokého učení, jako jsou konvoluční neuronové sítě, rekurentní neuronové sítě, se používají pro mnoho kontrolovaných úkolů, jako je klasifikace a rozpoznávání obrazu, analýza sentimentu, jazykové překlady atd.
- Strojové učení bez dozoru: Strojové učení bez dozoru je strojové učení technika, ve které se neuronová síť učí objevovat vzory nebo shlukovat datovou sadu na základě neoznačených datových sad. Zde nejsou žádné cílové proměnné. zatímco stroj musí sám určit skryté vzorce nebo vztahy v rámci datových sad. Algoritmy hlubokého učení, jako jsou autokodéry a generativní modely, se používají pro úkoly bez dozoru, jako je shlukování, redukce rozměrů a detekce anomálií.
- Posílení strojového učení : Posílení strojového učení je strojové učení technika, ve které se agent učí dělat rozhodnutí v prostředí, aby maximalizoval signál odměny. Agent interaguje s prostředím tím, že podniká kroky a pozoruje výsledné odměny. Hluboké učení lze použít k učení se zásadám nebo souboru akcí, které maximalizují kumulativní odměnu v průběhu času. Algoritmy učení hlubokého posílení, jako jsou sítě Deep Q a hluboký deterministický politický gradient (DDPG), se používají k posílení úkolů, jako je robotika a hraní her atd.
Umělé neuronové sítě
Umělé neuronové sítě jsou postaveny na principech struktury a činnosti lidských neuronů. Je také známý jako neuronové sítě nebo neuronové sítě. Vstupní vrstva umělé neuronové sítě, která je první vrstvou, přijímá vstup z vnějších zdrojů a předává jej skryté vrstvě, která je druhou vrstvou. Každý neuron ve skryté vrstvě získá informace od neuronů v předchozí vrstvě, vypočítá vážený součet a poté je přenese do neuronů v další vrstvě. Tato spojení jsou vážená, což znamená, že dopady vstupů z předchozí vrstvy jsou víceméně optimalizovány tím, že každému vstupu je přiřazena odlišná váha. Tyto váhy se pak upravují během tréninkového procesu, aby se zlepšil výkon modelu.
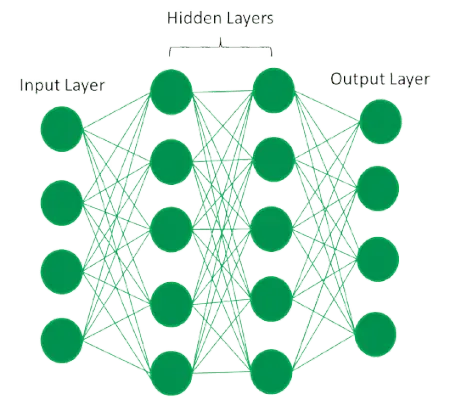
Plně propojená umělá neuronová síť
Umělé neurony, také známé jako jednotky, se nacházejí v umělých neuronových sítích. Celá umělá neuronová síť se skládá z těchto umělých neuronů, které jsou uspořádány v sérii vrstev. Složitost neuronových sítí bude záviset na složitosti základních vzorů v datové sadě, zda vrstva má tucet jednotek nebo miliony jednotek. Umělá neuronová síť má běžně vstupní vrstvu, výstupní vrstvu a také skryté vrstvy. Vstupní vrstva přijímá data z vnějšího světa, která neuronová síť potřebuje analyzovat nebo se o nich dozvědět.
V plně propojené umělé neuronové síti je vstupní vrstva a jedna nebo více skrytých vrstev zapojených za sebou. Každý neuron přijímá vstup od neuronů předchozí vrstvy nebo vstupní vrstvy. Výstup jednoho neuronu se stává vstupem pro další neurony v další vrstvě sítě a tento proces pokračuje, dokud poslední vrstva neprodukuje výstup sítě. Poté, co projdou jednou nebo více skrytými vrstvami, jsou tato data transformována na cenná data pro výstupní vrstvu. Nakonec výstupní vrstva poskytuje výstup ve formě reakce umělé neuronové sítě na data, která přicházejí.
Ve většině neuronových sítí jsou jednotky vzájemně propojeny z jedné vrstvy do druhé. Každý z těchto odkazů má váhy, které řídí, jak moc jedna jednotka ovlivňuje druhou. Neuronová síť se učí stále více o datech, jak se přesouvají z jedné jednotky do druhé, a nakonec vytváří výstup z výstupní vrstvy.
Rozdíl mezi strojovým učením a hlubokým učením:
strojové učení a deep learning AI jsou podmnožiny umělé inteligence, ale existuje mezi nimi mnoho podobností a rozdílů.
| Strojové učení | Hluboké učení |
|---|---|
| Aplikujte statistické algoritmy, abyste se naučili skryté vzory a vztahy v datové sadě. | Používá architekturu umělé neuronové sítě k učení skrytých vzorců a vztahů v datové sadě. |
| Může pracovat na menším množství datové sady | Vyžaduje větší objem datové sady ve srovnání se strojovým učením |
| Lepší pro úlohy s nízkým štítkem. | Lepší pro složité úlohy, jako je zpracování obrazu, zpracování přirozeného jazyka atd. |
| Trénink modelu zabere méně času. | Trénink modelu zabere více času. |
| Model je vytvořen pomocí příslušných prvků, které jsou ručně extrahovány z obrázků za účelem detekce objektu v obrázku. | Relevantní funkce jsou automaticky extrahovány z obrázků. Je to proces učení od začátku do konce. |
| Méně složité a snadno interpretovatelné výsledky. | Složitější to funguje tak, že interpretace výsledku v černé skříňce není snadná. |
| Může pracovat na CPU nebo vyžaduje menší výpočetní výkon ve srovnání s hlubokým učením. | Vyžaduje to vysoce výkonný počítač s GPU. |
Typy neuronových sítí
Modely hlubokého učení se dokážou automaticky naučit funkce z dat, díky čemuž jsou vhodné pro úkoly, jako je rozpoznávání obrazu, rozpoznávání řeči a zpracování přirozeného jazyka. Nejpoužívanější architektury v hlubokém učení jsou dopředné neuronové sítě, konvoluční neuronové sítě (CNN) a rekurentní neuronové sítě (RNN).
- Dopředné neuronové sítě (FNN) jsou nejjednodušším typem ANN s lineárním tokem informací sítí. FNN byly široce používány pro úkoly, jako je klasifikace obrazu, rozpoznávání řeči a zpracování přirozeného jazyka.
- Konvoluční neuronové sítě (CNN) jsou speciálně pro úlohy rozpoznávání obrázků a videa. CNN jsou schopny se automaticky naučit funkce z obrázků, díky čemuž jsou vhodné pro úkoly, jako je klasifikace obrázků, detekce objektů a segmentace obrázků.
- Rekurentní neuronové sítě (RNN) jsou typem neuronové sítě, která je schopna zpracovávat sekvenční data, jako jsou časové řady a přirozený jazyk. RNN jsou schopny udržovat vnitřní stav, který zachycuje informace o předchozích vstupech, což je činí vhodnými pro úkoly, jako je rozpoznávání řeči, zpracování přirozeného jazyka a překlad jazyka.
Aplikace pro hluboké učení:
Hlavní aplikace hlubokého učení AI lze rozdělit na počítačové vidění, zpracování přirozeného jazyka (NLP) a posilovací učení.
1. Počítačové vidění
První aplikací Deep Learning je počítačové vidění. v počítačové vidění , Hluboké učení modely umělé inteligence umožňují strojům identifikovat a porozumět vizuálním datům. Některé z hlavních aplikací hlubokého učení v počítačovém vidění zahrnují:
- Detekce a rozpoznávání objektů: Model hlubokého učení lze použít k identifikaci a lokalizaci objektů na snímcích a videích, což umožňuje strojům provádět úkoly, jako jsou samořídící auta, dohled a robotika.
- Klasifikace obrázků: Modely hlubokého učení lze použít ke klasifikaci obrázků do kategorií, jako jsou zvířata, rostliny a budovy. To se používá v aplikacích, jako je lékařské zobrazování, kontrola kvality a vyhledávání snímků.
- Segmentace obrázku: Modely hlubokého učení lze použít pro segmentaci obrazu do různých oblastí, což umožňuje identifikovat specifické rysy v obrazech.
2. Zpracování přirozeného jazyka (NLP) :
V aplikacích pro hluboké učení je druhou aplikací NLP. NLP , Model hlubokého učení může strojům umožnit porozumět a generovat lidský jazyk. Některé z hlavních aplikací hlubokého učení v NLP zahrnout:
- Automatické generování textu – Model hlubokého učení se může naučit korpus textu a nový text, jako jsou shrnutí, eseje lze automaticky generovat pomocí těchto trénovaných modelů.
- Jazykový překlad: Modely hlubokého učení mohou překládat text z jednoho jazyka do druhého, což umožňuje komunikovat s lidmi z různých jazykových prostředí.
- Analýza sentimentu: Modely hlubokého učení dokážou analyzovat sentiment části textu, což umožňuje určit, zda je text pozitivní, negativní nebo neutrální. To se používá v aplikacích, jako je zákaznický servis, monitorování sociálních médií a politická analýza.
- Rozpoznávání řeči: Modely hlubokého učení dokážou rozpoznat a přepsat mluvená slova, což umožňuje provádět úkoly, jako je převod řeči na text, hlasové vyhledávání a hlasem ovládaná zařízení.
3. Posílené učení:
v posilovací učení , hluboké učení funguje jako trénink agentů, aby podnikli kroky v prostředí s cílem maximalizovat odměnu. Některé z hlavních aplikací hlubokého učení v posilovacím učení zahrnují:
- Hraní hry: Učební modely hlubokého posílení dokázaly porazit lidské experty ve hrách jako Go, Chess a Atari.
- Robotika: Modely hlubokého učení lze použít k výcviku robotů k provádění složitých úkolů, jako je uchopování předmětů, navigace a manipulace.
- Řídící systémy: Modely hlubokého učení lze použít k řízení složitých systémů, jako jsou energetické sítě, řízení provozu a optimalizace dodavatelského řetězce.
Výzvy v hlubokém učení
Hluboké učení dosáhlo významného pokroku v různých oblastech, ale stále existují určité problémy, které je třeba řešit. Zde jsou některé z hlavních problémů hlubokého učení:
- Dostupnost dat : Učení vyžaduje velké množství dat. Pro použití hlubokého učení je velkým problémem shromáždit co nejvíce dat pro školení.
- Výpočetní zdroje : Pro trénování modelu hlubokého učení je výpočetně nákladný, protože vyžaduje specializovaný hardware, jako jsou GPU a TPU.
- Časově náročné: Při práci na sekvenčních datech v závislosti na výpočetním zdroji to může trvat velmi dlouho, dokonce i ve dnech nebo měsících.
- já interpretovatelnost: Modely hlubokého učení jsou složité, funguje to jako černá skříňka. je velmi obtížné interpretovat výsledek.
- Převybavení: když je model trénován znovu a znovu, stává se příliš specializovaným pro trénovací data, což vede k přeplnění a špatnému výkonu na nových datech.
Výhody hlubokého učení:
- Vysoká přesnost: Algoritmy hlubokého učení mohou dosáhnout špičkového výkonu v různých úkolech, jako je rozpoznávání obrazu a zpracování přirozeného jazyka.
- Automatizované inženýrství funkcí: Algoritmy hlubokého učení mohou automaticky zjišťovat a učit se relevantní funkce z dat bez nutnosti ručního inženýrství funkcí.
- Škálovatelnost: Modely hlubokého učení se mohou škálovat, aby zvládly velké a složité datové sady, a mohou se učit z obrovského množství dat.
- Flexibilita: Modely hlubokého učení lze aplikovat na širokou škálu úkolů a mohou zpracovávat různé typy dat, jako jsou obrázky, text a řeč.
- Neustálé zlepšování: Modely hlubokého učení mohou neustále zlepšovat svůj výkon, jakmile bude k dispozici více dat.
Nevýhody hlubokého učení:
- Vysoké výpočetní nároky: Modely Deep Learning AI vyžadují velké množství dat a výpočetních zdrojů pro trénování a optimalizaci.
- Vyžaduje velké množství označených dat : Modely hlubokého učení často vyžadují velké množství označených dat pro školení, jejichž získání může být drahé a časově náročné.
- interpretovatelnost: Modely hlubokého učení mohou být náročné na interpretaci, takže je obtížné pochopit, jak se rozhodují.
Převybavení: Modely hlubokého učení se někdy mohou překrývat s trénovacími daty, což má za následek špatný výkon na nových a neviditelných datech. - Black-box příroda : S modely Deep Learning se často zachází jako s černými skříňkami, takže je obtížné pochopit, jak fungují a jak ke svým předpovědím dospěly.
Závěr
Závěrem lze říci, že oblast Deep Learning představuje transformační skok v umělé inteligenci. Napodobením neuronových sítí lidského mozku způsobily algoritmy Deep Learning AI revoluci v odvětvích od zdravotnictví po finance, od autonomních vozidel po zpracování přirozeného jazyka. Jak stále posouváme hranice výpočetního výkonu a velikostí datových sad, potenciální aplikace Deep Learning jsou neomezené. Výzvy, jako je interpretovatelnost a etické úvahy, však zůstávají významné. S pokračujícím výzkumem a inovacemi však Deep Learning slibuje přetvořit naši budoucnost a zahájí novou éru, kde se stroje mohou učit, přizpůsobovat se a řešit složité problémy v rozsahu a rychlosti, které byly dříve nepředstavitelné.