A Konvoluční neuronová síť (CNN) je typem architektury neuronové sítě Deep Learning běžně používané v počítačovém vidění. Počítačové vidění je obor umělé inteligence, který umožňuje počítači porozumět a interpretovat obraz nebo vizuální data.
Pokud jde o strojové učení, Umělé neuronové sítě vystupovat opravdu dobře. Neuronové sítě se používají v různých souborech dat, jako jsou obrázky, zvuk a text. Různé typy neuronových sítí se používají pro různé účely, například pro předpovídání pořadí slov, která používáme Rekurentní neuronové sítě přesněji an LSTM , podobně pro klasifikaci obrázků používáme konvoluční neuronové sítě. V tomto blogu postavíme základní stavební kámen CNN.
V běžné neuronové síti existují tři typy vrstev:
- Vstupní vrstvy: Je to vrstva, ve které dáváme vstup do našeho modelu. Počet neuronů v této vrstvě se rovná celkovému počtu prvků v našich datech (počet pixelů v případě obrázku).
- Skrytá vrstva: Vstup ze vstupní vrstvy je pak přiváděn do skryté vrstvy. V závislosti na našem modelu a velikosti dat může být mnoho skrytých vrstev. Každá skrytá vrstva může mít různý počet neuronů, které jsou obecně větší než počet prvků. Výstup z každé vrstvy je vypočítán maticovým vynásobením výstupu předchozí vrstvy s naučitelnými vahami této vrstvy a poté přidáním naučitelných odchylek následovaných aktivační funkcí, která dělá síť nelineární.
- Výstupní vrstva: Výstup ze skryté vrstvy je pak přiváděn do logistické funkce, jako je sigmoid nebo softmax, která převádí výstup každé třídy na pravděpodobnostní skóre každé třídy.
Data jsou přiváděna do modelu a výstup z každé vrstvy je získán z výše uvedeného kroku je volán vpřed , pak vypočítáme chybu pomocí chybové funkce, některé běžné chybové funkce jsou křížová entropie, chyba čtvercové ztráty atd. Chybová funkce měří, jak dobře síť funguje. Poté se zpětně propagujeme do modelu výpočtem derivací. Tento krok se nazývá Konvoluční neuronová síť (CNN) je rozšířenou verzí umělé neuronové sítě (ANN) který se převážně používá k extrahování prvku z datové sady mřížkové matice. Například vizuální datové sady, jako jsou obrázky nebo videa, kde vzory dat hrají rozsáhlou roli.
Architektura CNN
Konvoluční neuronová síť se skládá z více vrstev, jako je vstupní vrstva, konvoluční vrstva, sdružovací vrstva a plně propojené vrstvy.

Jednoduchá architektura CNN
Konvoluční vrstva aplikuje filtry na vstupní obraz pro extrakci prvků, sdružovací vrstva převzorkuje obraz dolů, aby se snížily výpočty, a plně propojená vrstva vytváří konečnou předpověď. Síť se učí optimální filtry prostřednictvím zpětného šíření a gradientového sestupu.
Jak fungují konvoluční vrstvy
Konvoluční neuronové sítě nebo covnety jsou neuronové sítě, které sdílejí své parametry. Představte si, že máte obrázek. Může být reprezentován jako kvádr mající svou délku, šířku (rozměr obrázku) a výšku (tj. kanál, protože obrázky mají obecně červené, zelené a modré kanály).
Nyní si představte, že vezmete malou záplatu tohoto obrázku a spustíte na něm malou neuronovou síť, nazývanou filtr nebo jádro, s řekněme K výstupy a reprezentující je vertikálně. Nyní posuňte tuto neuronovou síť přes celý obrázek, ve výsledku získáme další obrázek s různými šířkami, výškami a hloubkami. Místo pouze kanálů R, G a B nyní máme více kanálů, ale menší šířku a výšku. Tato operace se nazývá Konvoluce . Pokud je velikost patche stejná jako velikost obrázku, bude to běžná neuronová síť. Kvůli této malé náplasti máme méně závaží.
java tostring
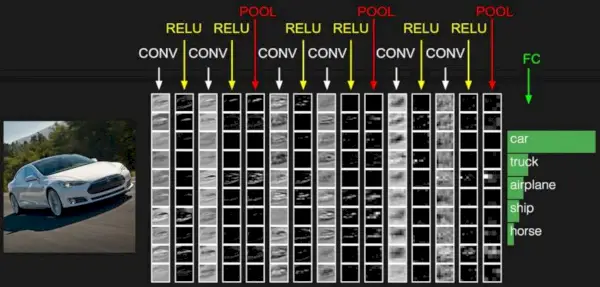
Zdroj obrázků: Deep Learning Udacity
Nyní si promluvme trochu o matematice, která je součástí celého procesu konvoluce.
- Konvoluční vrstvy se skládají ze sady naučitelných filtrů (nebo jader), které mají malé šířky a výšky a stejnou hloubku jako vstupní objem (3, pokud je vstupní vrstvou obrazový vstup).
- Například pokud musíme spustit konvoluci na obrázku o rozměrech 34x34x3. Možná velikost filtrů může být axax3, kde „a“ může být něco jako 3, 5 nebo 7, ale menší ve srovnání s rozměrem obrázku.
- Během dopředného průchodu posouváme každý filtr přes celý vstupní objem krok za krokem, kde je každý krok volán krok (která může mít hodnotu 2, 3 nebo dokonce 4 pro vysokorozměrné obrázky) a ze vstupního objemu vypočítejte bodový součin mezi váhami jádra a záplatou.
- Když posouváme naše filtry, získáme 2-D výstup pro každý filtr a ve výsledku je složíme dohromady, získáme výstupní objem s hloubkou rovnou počtu filtrů. Síť se naučí všechny filtry.
Vrstvy používané k vytváření ConvNets
Kompletní architektura konvolučních neuronových sítí je také známá jako covnets. Covnets je posloupnost vrstev a každá vrstva transformuje jeden svazek na druhý prostřednictvím diferencovatelné funkce.
Typy vrstev: datové sady
Vezměme si příklad spuštěním covnetů na obrázku o rozměrech 32 x 32 x 3.
- Vstupní vrstvy: Je to vrstva, ve které dáváme vstup do našeho modelu. V CNN bude vstupem obecně obrázek nebo sekvence obrázků. Tato vrstva obsahuje nezpracovaný vstup obrázku o šířce 32, výšce 32 a hloubce 3.
- Konvoluční vrstvy: Toto je vrstva, která se používá k extrahování prvku ze vstupní datové sady. Na vstupní obrázky aplikuje sadu naučitelných filtrů známých jako jádra. Filtry/jádra jsou menší matice obvykle tvaru 2×2, 3×3 nebo 5×5. klouže po vstupních obrazových datech a vypočítává bodový součin mezi váhou jádra a odpovídajícím vstupním obrazovým polem. Výstup této vrstvy se označuje jako mapy prvků. Předpokládejme, že pro tuto vrstvu použijeme celkem 12 filtrů, získáme výstupní objem o rozměrech 32 x 32 x 12.
- Aktivační vrstva: Přidáním aktivační funkce k výstupu předchozí vrstvy přidávají aktivační vrstvy síti nelinearitu. na výstup konvoluční vrstvy použije aktivační funkci po prvcích. Některé běžné aktivační funkce jsou životopis : max(0, x), Rybí , Leaky RELU , atd. Objem zůstává nezměněn, takže výstupní objem bude mít rozměry 32 x 32 x 12.
- Sdružovací vrstva: Tato vrstva je periodicky vkládána do covnetů a její hlavní funkcí je zmenšit velikost objemu, díky čemuž je výpočet rychlý, snižuje paměť a také zabraňuje přeplnění. Existují dva běžné typy sdružovacích vrstev max sdružování a průměrné sdružování . Pokud použijeme max pool s 2 x 2 filtry a krok 2, výsledný objem bude mít rozměr 16x16x12.
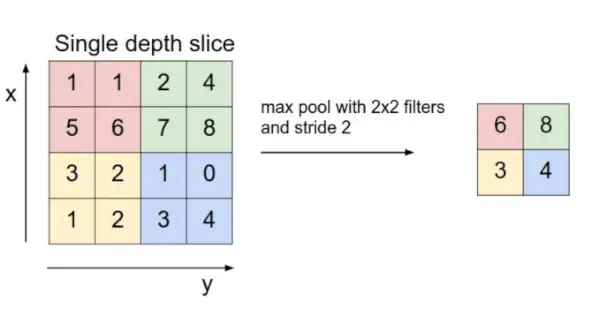
Zdroj obrázků: cs231n.stanford.edu
- Zploštění: Výsledné mapy prvků jsou po konvoluci a sdružování vrstev sloučeny do jednorozměrného vektoru, takže je lze předat do zcela propojené vrstvy pro kategorizaci nebo regresi.
- Plně propojené vrstvy: Přebírá vstup z předchozí vrstvy a vypočítává konečný klasifikační nebo regresní úkol.
Zdroj obrázků: cs231n.stanford.edu
- Výstupní vrstva: Výstup z plně propojených vrstev je pak přiváděn do logistické funkce pro klasifikační úlohy, jako je sigmoid nebo softmax, která převádí výstup každé třídy na pravděpodobnostní skóre každé třídy.
Příklad:
Podívejme se na obrázek a aplikujme konvoluční vrstvu, aktivační vrstvu a operaci sdružovací vrstvy k extrahování vnitřního prvku.
Vstupní obrázek:
Vstupní obrázek
Krok:
- importovat potřebné knihovny
- nastavte parametr
- definovat jádro
- Načtěte obrázek a vykreslete jej.
- Přeformátujte obrázek
- Použijte operaci konvoluční vrstvy a vykreslete výstupní obraz.
- Použijte operaci aktivační vrstvy a vykreslete výstupní obraz.
- Použijte operaci sdružovací vrstvy a vykreslete výstupní obraz.
Python3
najít můj iphone android
# import the necessary libraries> import> numpy as np> import> tensorflow as tf> import> matplotlib.pyplot as plt> from> itertools>import> product> > # set the param> plt.rc(>'figure'>, autolayout>=>True>)> plt.rc(>'image'>, cmap>=>'magma'>)> > # define the kernel> kernel>=> tf.constant([[>->1>,>->1>,>->1>],> >[>->1>,>8>,>->1>],> >[>->1>,>->1>,>->1>],> >])> > # load the image> image>=> tf.io.read_file(>'Ganesh.webp'plain'>)> image>=> tf.io.decode_jpeg(image, channels>=>1>)> image>=> tf.image.resize(image, size>=>[>300>,>300>])> > # plot the image> img>=> tf.squeeze(image).numpy()> plt.figure(figsize>=>(>5>,>5>))> plt.imshow(img, cmap>=>'gray'>)> plt.axis(>'off'>)> plt.title(>'Original Gray Scale image'>)> plt.show();> > > # Reformat> image>=> tf.image.convert_image_dtype(image, dtype>=>tf.float32)> image>=> tf.expand_dims(image, axis>=>0>)> kernel>=> tf.reshape(kernel, [>*>kernel.shape,>1>,>1>])> kernel>=> tf.cast(kernel, dtype>=>tf.float32)> > # convolution layer> conv_fn>=> tf.nn.conv2d> > image_filter>=> conv_fn(> >input>=>image,> >filters>=>kernel,> >strides>=>1>,># or (1, 1)> >padding>=>'SAME'>,> )> > plt.figure(figsize>=>(>15>,>5>))> > # Plot the convolved image> plt.subplot(>1>,>3>,>1>)> > plt.imshow(> >tf.squeeze(image_filter)> )> plt.axis(>'off'>)> plt.title(>'Convolution'>)> > # activation layer> relu_fn>=> tf.nn.relu> # Image detection> image_detect>=> relu_fn(image_filter)> > plt.subplot(>1>,>3>,>2>)> plt.imshow(> ># Reformat for plotting> >tf.squeeze(image_detect)> )> > plt.axis(>'off'>)> plt.title(>'Activation'>)> > # Pooling layer> pool>=> tf.nn.pool> image_condense>=> pool(>input>=>image_detect,> >window_shape>=>(>2>,>2>),> >pooling_type>=>'MAX'>,> >strides>=>(>2>,>2>),> >padding>=>'SAME'>,> >)> > plt.subplot(>1>,>3>,>3>)> plt.imshow(tf.squeeze(image_condense))> plt.axis(>'off'>)> plt.title(>'Pooling'>)> plt.show()> |
>
>
Výstup :

Původní obrázek ve stupních šedi
Výstup
Výhody konvolučních neuronových sítí (CNN):
- Dobré při detekci vzorů a funkcí v obrázcích, videích a zvukových signálech.
- Robustní vůči invariantnosti posunu, rotace a měřítka.
- End-to-end školení, není potřeba manuální extrakce funkcí.
- Dokáže zpracovat velké množství dat a dosáhnout vysoké přesnosti.
Nevýhody konvolučních neuronových sítí (CNN):
- Výpočetně nákladné trénování a vyžaduje hodně paměti.
- Může být náchylný k nadměrnému vybavení, pokud není použit dostatek dat nebo správné regularizace.
- Vyžaduje velké množství označených dat.
- Interpretovatelnost je omezená, je těžké pochopit, co se síť naučila.
Často kladené otázky (FAQ)
1: Co je to konvoluční neuronová síť (CNN)?
Konvoluční neuronová síť (CNN) je typ neuronové sítě hlubokého učení, která se dobře hodí pro analýzu obrazu a videa. CNN používají řadu konvolučních a sdružovacích vrstev k extrahování funkcí z obrázků a videí a poté tyto funkce používají ke klasifikaci nebo detekci objektů nebo scén.
2: Jak CNN fungují?
CNN fungují tak, že na vstupní obrázek nebo video aplikují řadu vrstev konvoluce a sdružování. Konvoluční vrstvy extrahují prvky ze vstupu posunutím malého filtru nebo jádra přes obrázek nebo video a vypočítávají bodový součin mezi filtrem a vstupem. Sdružovací vrstvy pak převzorkují výstup vrstev konvoluce, aby se snížila rozměrnost dat a aby byla výpočetně efektivnější.
3: Jaké jsou některé běžné aktivační funkce používané v CNN?
Některé běžné aktivační funkce používané v CNN zahrnují:
- Rectified Linear Unit (ReLU): ReLU je nesaturující aktivační funkce, která je výpočetně efektivní a snadno se trénuje.
- Leaky Rectified Linear Unit (Leaky ReLU): Leaky ReLU je varianta ReLU, která umožňuje proudění malého množství negativního gradientu sítí. To může pomoci zabránit tomu, aby síť během tréninku zemřela.
- Parametric Rectified Linear Unit (PReLU): PReLU je zobecněním Leaky ReLU, které umožňuje naučit se sklon negativního gradientu.
4: Jaký je účel použití více vrstev konvoluce v CNN?
Použití více vrstev konvoluce v CNN umožňuje síti naučit se stále složitější funkce ze vstupního obrazu nebo videa. První konvoluční vrstvy se učí jednoduché prvky, jako jsou hrany a rohy. Hlubší konvoluční vrstvy se učí složitějším prvkům, jako jsou tvary a objekty.
5: Jaké jsou některé běžné regularizační techniky používané v CNN?
Regularizační techniky se používají k zabránění CNN v přeplnění tréninkových dat. Některé běžné regularizační techniky používané v CNN zahrnují:
- Dropout: Dropout náhodně vyřadí neurony ze sítě během tréninku. To nutí síť naučit se robustnější funkce, které nejsou závislé na žádném jednotlivém neuronu.
- Regulace L1: Regulace L1 reguluje absolutní hodnota vah v síti. To může pomoci snížit počet závaží a zefektivnit síť.
- Regulace L2: Regulace L2 reguluje druhou mocninou vah v síti. To může také pomoci snížit počet závaží a zefektivnit síť.
6: Jaký je rozdíl mezi konvoluční vrstvou a sdružovací vrstvou?
Konvoluční vrstva extrahuje prvky ze vstupního obrázku nebo videa, zatímco sdružovací vrstva převzorkuje výstup vrstev konvoluce. Konvoluční vrstvy používají k extrakci funkcí řadu filtrů, zatímco sdružovací vrstvy používají různé techniky k převzorkování dat, jako je maximální sdružování a průměrné sdružování.