BERT, zkratka pro obousměrné reprezentace kodéru od Transformers , stojí jako open-source rámec strojového učení určeno pro říši zpracování přirozeného jazyka (NLP) . Tento framework vznikl v roce 2018 a byl vytvořen výzkumníky z Google AI Language. Článek si klade za cíl prozkoumat architektura, fungování a aplikace BERT .
Co je BERT?
BERT (Obousměrné reprezentace kodéru od Transformers) využívá neuronovou síť založenou na transformátoru k pochopení a generování lidského jazyka. BERT využívá architekturu pouze s kodérem. V originále Architektura transformátoru , existují moduly kodéru i dekodéru. Rozhodnutí použít v BERT architekturu pouze s kodérem naznačuje primární důraz na pochopení vstupních sekvencí spíše než na generování výstupních sekvencí.
Obousměrný přístup BERT
Tradiční jazykové modely zpracovávají text postupně, buď zleva doprava nebo zprava doleva. Tato metoda omezuje povědomí modelu na bezprostřední kontext předcházející cílovému slovu. BERT používá obousměrný přístup s ohledem na levý i pravý kontext slov ve větě, místo toho, aby analyzoval text postupně, BERT se dívá na všechna slova ve větě současně.
Příklad: Břeh se nachází na _______ řeky.
V jednosměrném modelu by pochopení blanku silně záviselo na předchozích slovech a model by mohl mít potíže s rozlišením, zda banka odkazuje na finanční instituci nebo na břeh řeky.
BERT, protože je obousměrný, bere současně v úvahu jak levý (břeh se nachází na) tak pravý kontext (řeky), což umožňuje jemnější porozumění. Chápe, že chybějící slovo pravděpodobně souvisí s geografickou polohou banky, což ukazuje na kontextové bohatství, které obousměrný přístup přináší.
Předtrénink a jemné doladění
Model BERT prochází dvoufázovým procesem:
- Předškolní příprava na velké množství neoznačeného textu, abyste se naučili kontextové vkládání.
- Jemné doladění označených dat pro konkrétní NLP úkoly.
Předškolní příprava na velká data
- BERT je předem trénován na velké množství neoznačených textových dat. Model se učí kontextová vložení, což jsou reprezentace slov, které berou v úvahu okolní kontext ve větě.
- BERT se zapojuje do různých předtréninkových úkolů bez dozoru. Může se například naučit předvídat chybějící slova ve větě (Masked Language Model nebo MLM úkol), porozumět vztahu mezi dvěma větami nebo předvídat další větu ve dvojici.
Jemné doladění označených dat
- Po předtréninkové fázi je model BERT, vyzbrojený svými kontextovými vložkami, doladěn pro konkrétní úlohy zpracování přirozeného jazyka (NLP). Tento krok přizpůsobí model více cíleným aplikacím přizpůsobením jeho obecného jazykového porozumění nuancím konkrétního úkolu.
- BERT je doladěn pomocí označených dat specifických pro navazující úkoly, které nás zajímají. Tyto úkoly mohou zahrnovat analýzu sentimentu, odpovědi na otázky, rozpoznávání pojmenovaných entit nebo jakákoli jiná aplikace NLP. Parametry modelu jsou upraveny tak, aby optimalizovaly jeho výkon pro konkrétní požadavky daného úkolu.
Jednotná architektura BERT umožňuje přizpůsobit se různým následným úkolům s minimálními úpravami, což z něj činí všestranný a vysoce účinný nástroj v porozumění přirozenému jazyku a zpracování.
Jak BERT funguje?
BERT je navržen tak, aby generoval jazykový model, takže se používá pouze mechanismus kodéru. Sekvence tokenů se přivádí do kodéru Transformer. Tyto tokeny jsou nejprve vloženy do vektorů a poté zpracovány v neuronové síti. Výstupem je sekvence vektorů, z nichž každý odpovídá vstupnímu tokenu, poskytující kontextové reprezentace.
Při trénování jazykových modelů je definování cíle predikce výzvou. Mnoho modelů předpovídá další slovo v sekvenci, což je směrový přístup a může omezit kontextové učení. BERT řeší tuto výzvu dvěma inovativními tréninkovými strategiemi:
- Maskovaný jazykový model (MLM)
- Predikce další věty (NSP)
1. Maskovaný jazykový model (MLM)
V procesu předběžného školení BERT je část slov v každé vstupní sekvenci maskována a model je trénován tak, aby předpovídal původní hodnoty těchto maskovaných slov na základě kontextu poskytovaného okolními slovy.
zjednodušeně řečeno,
- Maskovací slova: Než se BERT naučí z vět, skryje některá slova (asi 15 %) a nahradí je speciálním symbolem, například [MASK].
- Hádání skrytých slov: Úkolem BERT je zjistit, co tato skrytá slova jsou, tím, že se podívá na slova kolem nich. Je to jako hra hádání, kde některá slova chybí, a BERT se snaží vyplnit prázdná místa.
- Jak se BERT učí:
- BERT přidává speciální vrstvu nad svůj výukový systém, aby mohl tyto odhady provádět. Poté zkontroluje, jak blízko jsou jeho odhady skutečným skrytým slovům.
- Dělá to tak, že převádí své odhady na pravděpodobnosti a říká: Myslím, že toto slovo je X a jsem si tím tak jistý.
- Zvláštní pozornost skrytým slovům
- BERT se během tréninku zaměřuje hlavně na to, aby tato skrytá slova byla správná. Méně se stará o předvídání slov, která nejsou skryta.
- Je to proto, že skutečnou výzvou je zjistit chybějící části a tato strategie pomáhá společnosti BERT stát se opravdu dobrým v chápání významu a kontextu slov.
Z technického hlediska
- BERT přidává klasifikační vrstvu nad výstup z kodéru. Tato vrstva je klíčová pro predikci maskovaných slov.
- Výstupní vektory z klasifikační vrstvy jsou vynásobeny vkládací maticí a převádějí se do dimenze slovní zásoby. Tento krok pomáhá sladit předpokládané reprezentace s prostorem slovní zásoby.
- Pravděpodobnost každého slova ve slovní zásobě se vypočítá pomocí Aktivační funkce SoftMax . Tento krok generuje rozložení pravděpodobnosti v celém slovníku pro každou maskovanou pozici.
- Ztrátová funkce použitá během tréninku zohledňuje pouze předpověď maskovaných hodnot. Model je penalizován za odchylku mezi jeho předpovědí a skutečnými hodnotami maskovaných slov.
- Model konverguje pomaleji než směrové modely. Je to proto, že během tréninku se BERT zabývá pouze předpovídáním maskovaných hodnot a ignoruje předpověď nemaskovaných slov. Zvýšené povědomí o kontextu dosažené touto strategií kompenzuje pomalejší konvergenci.
2. Predikce další věty (NSP)
BERT předpovídá, zda je druhá věta spojena s první. To se provádí transformací výstupu tokenu [CLS] do vektoru ve tvaru 2×1 pomocí klasifikační vrstvy a následným výpočtem pravděpodobnosti, zda druhá věta následuje za první pomocí SoftMax.
- V tréninkovém procesu se BERT učí rozumět vztahu mezi dvojicemi vět a předpovídá, zda druhá věta následuje za první v původním dokumentu.
- 50 % vstupních dvojic má druhou větu jako následující větu v původním dokumentu a dalších 50 % má náhodně vybranou větu.
- Aby model pomohl rozlišit mezi spojenými a nesouvislými větnými dvojicemi. Vstup je zpracován před zadáním modelu:
- Token [CLS] se vloží na začátek první věty a token [SEP] se přidá na konec každé věty.
- Ke každému tokenu je přidáno vložení věty označující větu A nebo větu B.
- Polohové vložení označuje pozici každého tokenu v sekvenci.
- BERT předpovídá, zda je druhá věta spojena s první. To se provádí transformací výstupu tokenu [CLS] do vektoru ve tvaru 2×1 pomocí klasifikační vrstvy a následným výpočtem pravděpodobnosti, zda druhá věta následuje za první pomocí SoftMax.
Během trénování modelu BERT se společně trénují Masked LM a Next Sentence Prediction. Cílem modelu je minimalizovat kombinovanou ztrátovou funkci Masked LM a Next Sentence Prediction, což vede k robustnímu jazykovému modelu s vylepšenými schopnostmi v porozumění kontextu ve větách a vztahům mezi větami.
Proč trénovat Masked LM a Next Sentence Prediction společně?
Maskovaný LM pomáhá BERT pochopit kontext ve větě a Předpověď další věty pomáhá BERT pochopit spojení nebo vztah mezi dvojicemi vět. Společný trénink obou strategií tedy zajišťuje, že BERT se naučí širokému a komplexnímu porozumění jazyku a zachytí jak detaily ve větách, tak tok mezi větami.
Architektury BERT
Architektura BERT je vícevrstvý obousměrný transformátorový kodér, který je velmi podobný modelu transformátoru. Architektura transformátoru je síť kodér-dekodér, která používá sebepozornost na straně kodéru a pozornost na straně dekodéru.
- BERTZÁKLADNAmá 1 2 vrstvy v zásobníku kodéru zatímco BERTVELKÝmá 24 vrstev v zásobníku kodéru . Jedná se o více než architekturu Transformer popsanou v původním článku ( 6 vrstev kodéru ).
- Architektury BERT (BASE a LARGE) mají také větší dopředné sítě (768 resp. 1024 skrytých jednotek) a více hlav pozornosti (12 a 16 v tomto pořadí) než architektura Transformer navrhovala v původním článku. Obsahuje 512 skrytých jednotek a 8 hlav pozornosti .
- BERTZÁKLADNAobsahuje 110M parametrů, zatímco BERTVELKÝmá 340M parametrů.

Architektura BERT BASE a BERT LARGE.
Tento model bere CLS token jako vstup, poté následuje sekvence slov jako vstup. Zde je CLS klasifikační token. Poté předá vstup do výše uvedených vrstev. Platí každá vrstva sebepozornost a předá výsledek dopřednou sítí a poté jej předá dalšímu kodéru. Výstupem modelu je vektor skryté velikosti ( 768 pro BERT BASE). Pokud chceme výstup klasifikátoru z tohoto modelu, můžeme vzít výstup odpovídající tokenu CLS.
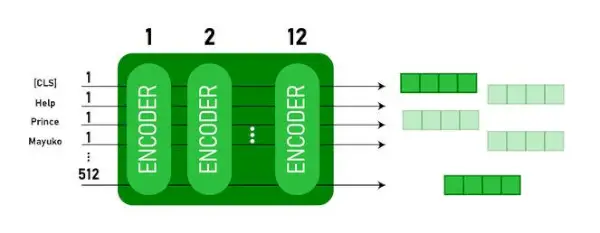
Výstup BERT jako vložení
Nyní lze tento trénovaný vektor použít k provádění řady úkolů, jako je klasifikace, překlad atd. Například papír dosahuje skvělých výsledků pouze s použitím jediné vrstvy Nervová síť na modelu BERT v klasifikační úloze.
Jak používat model BERT v NLP?
BERT lze použít pro různé úlohy zpracování přirozeného jazyka (NLP), jako jsou:
1. Klasifikační úkol
- BERT lze použít pro klasifikační úlohy jako analýza sentimentu , cílem je klasifikovat text do různých kategorií (pozitivní/negativní/neutrální), BERT lze použít přidáním klasifikační vrstvy do horní části výstupu Transformeru pro token [CLS].
- Token [CLS] představuje agregované informace z celé vstupní sekvence. Tato sdružená reprezentace pak může být použita jako vstup pro klasifikační vrstvu pro vytváření předpovědí pro konkrétní úlohu.
2. Odpověď na otázku
- V otázkách zodpovězení úloh, kde je požadováno, aby model našel a označil odpověď v dané textové sekvenci, lze BERT pro tento účel trénovat.
- BERT je trénován pro zodpovídání otázek učením dvou dalších vektorů, které označují začátek a konec odpovědi. Během tréninku je model vybaven otázkami a odpovídajícími pasážemi a učí se předvídat počáteční a koncovou pozici odpovědi v pasáži.
3. Rozpoznání pojmenované entity (NER)
- BERT lze použít pro NER, kde je cílem identifikovat a klasifikovat entity (např. Osoba, Organizace, Datum) v textové sekvenci.
- Model NER založený na BERT je trénován tak, že se výstupní vektor každého tokenu převezme z Transformeru a vloží se do klasifikační vrstvy. Vrstva předpovídá jmenovku pojmenované entity pro každý token a označuje typ entity, kterou představuje.
Jak tokenizovat a kódovat text pomocí BERT?
K tokenizaci a kódování textu pomocí BERT budeme používat knihovnu ‚transformer‘ v Pythonu.
Příkaz k instalaci transformátorů:
!pip install transformers>
- Předtrénovaný tokenize BERT načteme pomocí balené slovní zásoby BertTokenizer.from_pretrained(bert-base-case) .
- tokenizer.encode(text) tokenizuje vstupní text a převádí jej na sekvenci ID tokenů.
- tisknout (ID tokenů:, kódování) vytiskne ID tokenů získaná po zakódování.
- tokenizer.convert_ids_to_tokens(kódování) převede ID tokenů zpět na jejich odpovídající tokeny.
- tisknout (Tokeny:, tokeny) vytiskne tokeny získané po převodu ID tokenů
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Výstup:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.encode metoda přidává speciální [CLS] – klasifikace a [SEP] – oddělovač tokeny na začátku a na konci kódované sekvence.
Aplikace BERT
BERT se používá pro:
- Textová reprezentace: BERT se používá ke generování vložení slov nebo reprezentace slov ve větě.
- Rozpoznávání pojmenované entity (NER) : BERT lze doladit pro úlohy rozpoznávání pojmenovaných entit, kde je cílem identifikovat entity, jako jsou jména lidí, organizací, míst atd., v daném textu.
- Klasifikace textu: BERT je široce používán pro úlohy klasifikace textu, včetně analýzy sentimentu, detekce spamu a kategorizace témat. Prokázal vynikající výkon v porozumění a klasifikaci kontextu textových dat.
- Systémy odpovědí na otázky: BERT byl aplikován na systémy odpovědí na otázky, kde je model trénován tak, aby porozuměl kontextu otázky a poskytl relevantní odpovědi. To je užitečné zejména pro úkoly, jako je čtení s porozuměním.
- Strojový překlad: Kontextová vložení BERT lze využít ke zlepšení systémů strojového překladu. Model zachycuje nuance jazyka, které jsou klíčové pro přesný překlad.
- Shrnutí textu: BERT lze použít pro abstraktní sumarizaci textu, kdy model generuje stručná a smysluplná shrnutí delších textů pochopením kontextu a sémantiky.
- Konverzační umělá inteligence: BERT se používá při vytváření konverzačních systémů umělé inteligence, jako jsou chatboti, virtuální asistenti a dialogové systémy. Jeho schopnost uchopit kontext je efektivní pro porozumění a generování reakcí přirozeného jazyka.
- Sémantická podobnost: Vložení BERT lze použít k měření sémantické podobnosti mezi větami nebo dokumenty. To je cenné v úkolech, jako je detekce duplicit, identifikace parafrází a vyhledávání informací.
BERT vs GPT
Rozdíl mezi BERT a GPT je následující:
| BERT | GPT | |
|---|---|---|
| Architektura | BERT je navržen pro učení obousměrné reprezentace. Využívá cíle maskovaného jazykového modelu, kde předpovídá chybějící slova ve větě na základě levého i pravého kontextu. | GPT je na druhé straně určen pro generativní jazykové modelování. Předpovídá další slovo ve větě vzhledem k předchozímu kontextu s využitím jednosměrného autoregresního přístupu. |
| Předtréninkové cíle | BERT je předem trénován pomocí cíle maskovaného jazykového modelu a predikce další věty. Zaměřuje se na zachycení obousměrného kontextu a pochopení vztahů mezi slovy ve větě. | GPT je předem natrénováno na předvídání dalšího slova ve větě, což podporuje model, aby se naučil koherentní reprezentaci jazyka a generoval kontextově relevantní sekvence. |
| Porozumění kontextu | BERT je účinný pro úkoly, které vyžadují hluboké porozumění kontextu a vztahů ve větě, jako je klasifikace textu, rozpoznávání pojmenovaných entit a zodpovídání otázek. | Značka GPT je silná v generování koherentního a kontextově relevantního textu. Často se používá v kreativních úlohách, dialogových systémech a úlohách vyžadujících generování sekvencí přirozeného jazyka. |
| Typy úloh a případy použití
| Běžně se používá v úkolech, jako je klasifikace textu, rozpoznávání pojmenovaných entit, analýza sentimentu a odpovídání na otázky. | Aplikuje se na úkoly, jako je generování textu, dialogové systémy, sumarizace a kreativní psaní. |
| Jemné doladění vs učení s několika výstřely | BERT je často dolaďován na konkrétních následných úkolech pomocí označených dat, aby přizpůsobil své předem trénované reprezentace danému úkolu. | GPT je navržena tak, aby prováděla několikanásobné učení, kde se může zobecňovat na nové úkoly s minimálními daty pro konkrétní úkol. |
Zkontrolujte také:
- Klasifikace sentimentu pomocí BERT
- Jak generovat vkládání slov pomocí BERT?
- Model BART pro automatické dokončování textu v NLP
- Klasifikace toxických komentářů pomocí BERT
- Předpovídání další věty pomocí BERT
Často kladené otázky (FAQ)
Otázka: K čemu se BERT používá?
BERT se používá k provádění úloh NLP, jako je reprezentace textu, rozpoznávání pojmenovaných entit, klasifikace textu, systémy Q&A, strojový překlad, sumarizace textu a další.
Q. Jaké jsou výhody modelu BERT?
Jazykový model BERT vyniká rozsáhlým předškolením v několika jazycích a nabízí široké jazykové pokrytí ve srovnání s jinými modely. Díky tomu je BERT zvláště výhodný pro projekty, které nejsou založeny na angličtině, protože poskytuje robustní kontextové reprezentace a sémantické porozumění v různých jazycích, což zvyšuje jeho všestrannost ve vícejazyčných aplikacích.
Otázka: Jak funguje BERT pro analýzu sentimentu?
BERT vyniká v analýze sentimentu tím, že využívá své učení obousměrné reprezentace k zachycení kontextových nuancí, sémantických významů a syntaktických struktur v daném textu. To umožňuje BERT porozumět sentimentu vyjádřenému ve větě zvážením vztahů mezi slovy, což vede k vysoce účinným výsledkům analýzy sentimentu.
zapouzdření java
Otázka: Je Google založen na BERT?
BERT a RankBrain jsou součásti vyhledávacího algoritmu Google, které zpracovávají dotazy a obsah webových stránek za účelem lepšího porozumění za účelem zlepšení výsledků vyhledávání.