Učení pod dohledem a učení bez dohledu jsou dvě techniky strojového učení. Ale obě techniky se používají v různých scénářích as různými datovými sadami. Níže je uvedeno vysvětlení obou metod učení spolu s jejich tabulkou rozdílů.
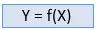
Strojové učení pod dohledem:
Supervised learning je metoda strojového učení, ve které jsou modely trénovány pomocí označených dat. Při učení pod dohledem modely potřebují najít mapovací funkci pro mapování vstupní proměnné (X) s výstupní proměnnou (Y).
Učení pod dohledem potřebuje dohled, aby se model trénoval, což je podobné, jako když se student učí věci v přítomnosti učitele. Učení pod dohledem lze použít pro dva typy problémů: Klasifikace a Regrese .
Zjistěte více Strojové učení pod dohledem
Příklad: Předpokládejme, že máme obrázek různých druhů ovoce. Úkolem našeho modelu učení pod dohledem je identifikovat ovoce a podle toho je klasifikovat. Abychom tedy identifikovali obrázek v řízeném učení, poskytneme vstupní data i výstup, což znamená, že model vycvičíme podle tvaru, velikosti, barvy a chuti každého ovoce. Jakmile je školení dokončeno, otestujeme model tím, že dáme nové sadě ovoce. Model identifikuje ovoce a předpovídá výstup pomocí vhodného algoritmu.
Strojové učení bez dozoru:
Učení bez dozoru je další metoda strojového učení, ve které jsou vzorce odvozené z neoznačených vstupních dat. Cílem neřízeného učení je najít strukturu a vzory ze vstupních dat. Učení bez dozoru nepotřebuje žádný dozor. Místo toho najde vzory z dat sám.
Zjistěte více Strojové učení bez dozoru
Učení bez dozoru lze použít pro dva typy problémů: Shlukování a Sdružení .
Příklad: Pro pochopení učení bez dozoru použijeme výše uvedený příklad. Na rozdíl od řízeného učení zde tedy nebudeme modelu poskytovat žádný dohled. Pouze poskytneme vstupní datovou sadu modelu a umožníme modelu najít vzory z dat. Pomocí vhodného algoritmu se model vycvičí a rozdělí plody do různých skupin podle nejpodobnějších vlastností mezi nimi.
Hlavní rozdíly mezi učením pod dohledem a učením bez dozoru jsou uvedeny níže:
| Učení pod dohledem | Učení bez dozoru |
|---|---|
| Algoritmy učení pod dohledem jsou trénovány pomocí označených dat. | Algoritmy učení bez dozoru jsou trénovány pomocí neoznačených dat. |
| Model učení pod dohledem využívá přímou zpětnou vazbu, aby zkontroloval, zda předpovídá správný výstup nebo ne. | Model učení bez dozoru nepřijímá žádnou zpětnou vazbu. |
| Model učení pod dohledem předpovídá výstup. | Model učení bez dozoru najde skryté vzorce v datech. |
| Při učení pod dohledem jsou vstupní data poskytnuta modelu spolu s výstupem. | Při učení bez dozoru jsou modelu poskytnuta pouze vstupní data. |
| Cílem řízeného učení je trénovat model tak, aby mohl předvídat výstup, když dostane nová data. | Cílem učení bez dozoru je najít skryté vzorce a užitečné poznatky z neznámého souboru dat. |
| Učení pod dohledem potřebuje dohled, aby mohl model trénovat. | Učení bez dozoru nepotřebuje k trénování modelu žádný dozor. |
| Řízené učení lze kategorizovat Klasifikace a Regrese problémy. | Učení bez dozoru lze zařadit do Shlukování a Asociace problémy. |
| Řízené učení lze využít v případech, kdy známe vstupy i odpovídající výstupy. | Učení bez dohledu lze použít pro ty případy, kdy máme pouze vstupní data a žádná odpovídající výstupní data. |
| Model učení pod dohledem poskytuje přesný výsledek. | Model učení bez dozoru může poskytovat méně přesné výsledky ve srovnání s učením pod dohledem. |
| Řízené učení se neblíží skutečné umělé inteligenci, protože v tomto model nejprve natrénujeme pro každé údaje a teprve potom může předpovědět správný výstup. | Učení bez dozoru se více blíží skutečné umělé inteligenci, protože se učí podobně, jako se dítě učí každodenní rutinní věci svými zkušenostmi. |
| Zahrnuje různé algoritmy, jako je lineární regrese, logistická regrese, podpůrný vektorový stroj, vícetřídní klasifikace, rozhodovací strom, bayesovská logika atd. | Zahrnuje různé algoritmy, jako je Clustering, KNN a Apriori algoritmus. |