Z-skóre ve statistice je měření toho, kolik standardních odchylek má datový bod od střední hodnoty rozdělení. Pojďme najít z skóre ve statistikách. Z-skóre 0 znamená, že skóre datového bodu je stejné jako průměrné skóre. Kladné z-skóre znamená, že datový bod je nadprůměrný, zatímco záporné z-skóre znamená, že datový bod je pod průměrem.
Vzorec pro výpočet z-skóre je: z = (x – μ)/p
Kde:
- X: je testovací hodnota
- m: je průměr
- na: je standardní hodnota
V tomto článku budeme diskutovat o následujících konceptech:
Obsah
- Co je Z-skóre?
- Jak vypočítat Z-skóre?
- Charakteristika Z-skóre
- Vypočítejte odlehlé hodnoty pomocí hodnoty Z-score
- Implementace Z-score v Pythonu
- Aplikace Z-skóre
- Z-skóre vs. standardní odchylka
- Proč se Z-skóre nazývá standardní skóre?
Co je Z-skóre?
Z-skóre, známé také jako standardní skóre, nám říká odchylku datového bodu od průměru tím, že ji vyjadřuje pomocí standardních odchylek nad nebo pod průměrem. Dává nám představu, jak daleko je datový bod od střední hodnoty. Z-skóre se tedy měří jako standardní odchylka od průměru. Například Z-skóre 2 znamená, že hodnota je 2 standardní odchylky od průměru. Abychom mohli použít z-skóre, potřebujeme znát průměr populace (μ) a také směrodatnou odchylku populace (σ).
Vzorec pro Z-skóre
Z-skóre lze vypočítat pomocí následujícího vzorce.
z = (X – μ) / p
kde,
- z = Z-skóre
- X = Hodnota prvku
- μ = populační průměr
- σ = směrodatná odchylka populace
Jak vypočítat Z-skóre?
Je nám dán průměr populace (μ), směrodatná odchylka populace (σ) a pozorovaná hodnota (x) ve výroku o problému, když totéž dosadíme do rovnice Z-skóre, dostaneme hodnotu Z-skóre. V závislosti na tom, zda je dané Z-skóre kladné nebo záporné, můžeme použít pozitivní Z-tabulka nebo negativní Z-tabulka k dispozici online nebo na zadní straně vaší učebnice statistiky v příloze.
{kind=link}
{kind=link}
Příklad 1:
Absolvujete test GATE a získáte 500. Průměrné skóre pro GATE je 390 a standardní odchylka je 45. Jak dobře jste dosáhli v testu ve srovnání s průměrným účastníkem testu?
Řešení:
Následující údaje jsou snadno dostupné ve výše uvedené otázce
Nezpracované skóre/zjištěná hodnota = X = 500
Průměrné skóre = μ = 390
Směrodatná odchylka = σ = 45
Použitím vzorce z-skóre
z = (X – μ) / p
z = (500 – 390) / 45
z = 110/45 = 2,44
To znamená, že vaše Z-skóre je 2.44 .
Protože je Z-skóre kladné 2,44, využijeme kladnou Z-tabulku.
Nyní se podívejme na Tabulka Z (CC-BY), abyste věděli, jak dobře jste dosáhli ve srovnání s ostatními účastníky testu.
java string.format
Podle pokynů níže najděte pravděpodobnost z tabulky.
Tady, z-skóre = 2,44, který i znamená, že datový bod je 2,44 standardní odchylky nad průměrem.
- Nejprve zmapujte první dvě číslice 2.4 na ose Y.
- Potom podél osy X, mapa 0,04
- Spojte obě osy. Průnik těchto dvou vám poskytne kumulativní pravděpodobnost spojenou s hodnotou Z-skóre, kterou hledáte
[Tato pravděpodobnost představuje oblast pod standardní normální křivkou nalevo od Z-skóre]
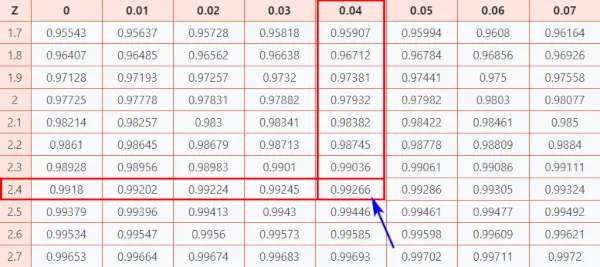
Tabulka normálního rozdělení
V důsledku toho získáte konečnou hodnotu, která je 0,99266 .
Nyní musíme porovnat, jak je naše původní skóre 500 ve zkoušce GATE v porovnání s průměrným skóre dávky. K tomu potřebujeme převést kumulativní pravděpodobnost spojenou se Z-skóre na procentuální hodnotu.
0,99266 × 100 = 99,266 %
Konečně můžete říci, že jste předvedli dobrý výkon 99 % ostatních účastníků testu.
Příklad 2 : Jaká je pravděpodobnost, že student dosáhne skóre mezi 350 a 400 (s průměrným skóre μ 390 a směrodatnou odchylkou σ 45)?
Řešení:
Minimální skóre = X1= 350
Maximální skóre = X2= 400
Použitím vzorce z-skóre
S1= (X1 – m) / p
S1= (350 – 390) / 45
S1= -40/45 = -0,88
S2= (X2– m) / str
z2 = (400 – 390) / 45
S2= 10/45 = 0,22
Protože z1 je záporné, budeme se muset podívat na záporné Z-tabulka a zjistit, že kumulativní pravděpodobnost p1, první pravděpodobnost, je 0,18943 .
S2je kladná, takže použijeme kladnou Z-tabulku, která dává kumulativní pravděpodobnost p2z 0,58706 .
Konečná pravděpodobnost se vypočítá odečtením p1 od p2:
p = p2– str1
p = 0,58706 – 0,18943 = 0,39763
Pravděpodobnost, že student dosáhne skóre mezi 350 a 400, je 39,763 % (0,39763 * 100).
Charakteristika Z-skóre
- Velikost Z-skóre odráží, jak daleko je datový bod od průměru ve smyslu standardních odchylek.
- Prvek, který má z-skóre menší než 0, znamená, že prvek je menší než průměr.
- Z-skóre umožňují srovnání datových bodů z různých distribucí.
- Prvek, který má z-skóre větší než 0, znamená, že prvek je větší než průměr.
- Prvek, který má z-skóre rovné 0, představuje, že prvek je roven průměru.
- Prvek, který má z-skóre rovné 1, představuje, že prvek je o 1 standardní odchylku větší než průměr; z-skóre rovné 2, 2 standardní odchylky větší než průměr atd.
- Prvek, který má z-skóre rovné -1, představuje, že prvek je o 1 standardní odchylku menší než průměr; z-skóre rovné -2, 2 standardní odchylky menší než průměr atd.
- Pokud je počet prvků v dané sadě velký, pak asi 68 % prvků má z-skóre mezi -1 a 1; asi 95 % má z-skóre mezi -2 a 2; asi 99 % má z-skóre mezi -3 a 3. Toto je známé jako Empirické pravidlo a udává procento dat v rámci určitých standardních odchylek od průměru v normálním rozdělení, jak ukazuje obrázek níže
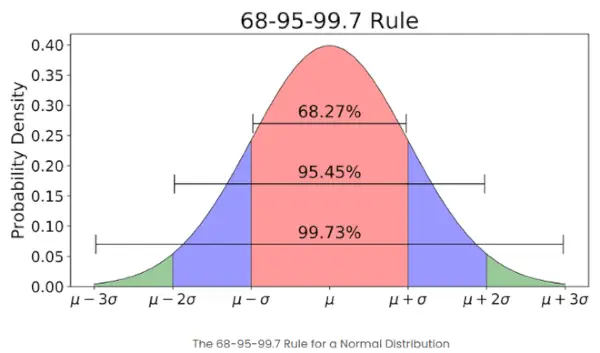
Empirické pravidlo v normálním rozdělení
Vypočítejte odlehlé hodnoty pomocí hodnoty Z-score
Můžeme vypočítat odlehlé hodnoty v datech pomocí hodnoty z-score datových bodů. Kroky ke zvážení odlehlého datového bodu jsou následující:
- Nejprve shromáždíme datovou sadu, ve které chceme vidět odlehlé hodnoty
- Vypočteme průměr a směrodatnou odchylku souboru dat. Tyto hodnoty se použijí k výpočtu hodnoty z-skóre každého datového bodu.
- Vypočítáme hodnotu z-skóre pro každý datový bod. Vzorec pro výpočet hodnoty z-score bude stejný jako
Z = frac{{X – mu}}{{sigma}}
kde X bude datový bod, μ je střední hodnota dat a σ je standardní odchylka souboru dat. - Určíme mezní hodnotu pro z-skóre, po které by mohl být datový bod považován za odlehlou hodnotu. Tato mezní hodnota je hyperparametr, o kterém rozhodujeme v závislosti na našem projektu.
- Datový bod, jehož hodnota z-score je větší než 3, znamená, že datový bod nepatří do 99,73 % bodu souboru dat.
- Jakýkoli datový bod, jehož z-skóre je větší než naše stanovená mezní hodnota, bude považován za odlehlou hodnotu.
Šek: Z skóre pro detekci odlehlých míst
Implementace Z-score v Pythonu
Můžeme použít Python k výpočtu hodnoty z-score datových bodů v datové sadě. Také použijeme numpy knihovnu k výpočtu střední hodnoty a standardní odchylky datové sady.
Python3 import numpy as np def calculate_z_score(data): # Mean of the dataset mean = np.mean(data) # Standard Deviation of tha dataset std_dev = np.std(data) # Z-score of tha data points z_scores = (data - mean) / std_dev return z_scores # Example dataset dataset = [3,9, 23, 43,53, 4, 5,30, 35, 50, 70, 150, 6, 7, 8, 9, 10] z_scores = calculate_z_score(dataset) print('Z-Score :',z_scores) # Data points which lies outside 3 standard deviatioms are outliers # i.e outside range of99.73% values outliers = [data_point for data_point, z_score in zip(dataset, z_scores) if z_score>3] print(f'
Odlehlé hodnoty v datové sadě jsou {odlehlé hodnoty}')> Výstup:
Z-Skóre: [-0,7574907 -0,59097335 -0,20243286 0,35262498 0,6301539 -0,72973781
-0,70198492 -0,00816262 0,13060185 0,54689523 1,10195307 3,32218443
-0,67423202 -0,64647913 -0,61872624 -0,59097335 -0,56322046]
Odlehlé hodnoty v datové sadě jsou [150]
Aplikace Z-skóre
- Z-skóre se často používají pro škálování funkcí, aby se různé funkce dostaly do společného měřítka. Normalizační funkce zajišťuje, že mají nulovou střední hodnotu a rozptyl jednotek, což může být výhodné pro určité algoritmy strojového učení, zejména ty, které se spoléhají na měření vzdálenosti.
- Z-skóre lze použít k identifikaci odlehlých hodnot v datové sadě. Datové body se Z-skóre nad určitou prahovou hodnotou (obvykle 3 standardní odchylky od průměru) mohou být považovány za odlehlé hodnoty.
- Z-skóre lze použít v algoritmech detekce anomálií k identifikaci případů, které se významně odchylují od očekávaného chování.
- Z-skóre lze použít k transformaci zkreslených rozdělení na normálnější rozdělení.
- Při práci s regresními modely lze analyzovat Z-skóre reziduí pro kontrolu homoskedasticity (konstantní rozptyl reziduí).
- Z-skóre lze použít při škálování rysů pohledem na jejich standardní odchylky od průměru.
Z-skóre vs. standardní odchylka
Z- skóre | Standardní odchylka |
|---|---|
Transformujte nezpracovaná data do standardizovaného měřítka. | Měří velikost variace nebo rozptylu v sadě hodnot. |
Usnadňuje porovnávání hodnot z různých datových sad, protože odebírají původní měrné jednotky. | Standardní odchylka zachovává původní jednotky měření, takže je méně vhodná pro přímá srovnání mezi soubory dat s různými jednotkami. |
Uveďte, jak daleko je datový bod od průměru z hlediska směrodatných odchylek, a uveďte míru relativní pozice datového bodu v rámci distribuce. | Vyjádřeno ve stejných jednotkách jako původní data, což poskytuje absolutní míru rozložení hodnot kolem průměru java indexof |
Šek: Tabulka Z-skóre
Proč se Z-skóre nazývá standardní skóre?
Z-skóre jsou také známé jako standardní skóre, protože standardizují hodnotu náhodné proměnné. To znamená, že seznam standardizovaných skóre má průměr 0 a směrodatnou odchylku 1,0. Z-skóre také umožňují srovnání skóre různých druhů proměnných. Je to proto, že používají relativní postavení ke srovnávání skóre z různých proměnných nebo distribucí.
Z-skóre se často používají k porovnání proměnné se standardní normální distribucí (s μ = 0 a σ = 1).
Z-skóre ve statistice – FAQ
Jaký je význam kladných a záporných Z-skóre?
Pozitivní Z-skóre označují hodnoty nad průměrem, zatímco negativní Z-skóre označují hodnoty pod průměrem. Znaménko odráží směr odchylky od průměru.
Co znamená Z-skóre 0?
Z-skóre 0 znamená, že hodnota datového bodu je přesně na střední hodnotě datové sady. To naznačuje, že datový bod není ani nad, ani pod průměrem.
Jaké je pravidlo 68-95-99.7 ve vztahu k Z-skóre?
Pravidlo 68-95-99.7, také známé jako Empirické pravidlo, říká, že:
- Asi 68 % dat spadá do 1 standardní odchylky od průměru.
- Asi 95 % spadá do 2 standardních odchylek.
- Asi 99,7 % spadá do 3 standardních odchylek.
Lze Z-skóre použít pro nenormální distribuce?
Z-skóre jsou založeny na předpokladu, že data sledují normální rozdělení. V praxi jsou však Z-skóre přínosné pro data, která sledují normální rozdělení. Zatímco Z-skóre lze vypočítat pro jakoukoli distribuci, jejich interpretace se stává méně spolehlivou a přímočarou při práci s nenormálně distribuovanými daty.
Jak lze Z-skóre použít v reálných situacích?
Z-skóre mají různé aplikace, například ve financích pro analýzu portfolia, vzdělávání pro standardizované testování, zdraví pro klinické hodnocení a další. Poskytují standardizované měřítko pro porovnávání a interpretaci dat.