Strojové učení je odvětví Umělá inteligence která se zaměřuje na vývoj modelů a algoritmů, které umožňují počítačům učit se z dat a zlepšovat se z předchozích zkušeností, aniž by byly explicitně naprogramovány pro každý úkol. Jednoduše řečeno, ML učí systémy myslet a chápat jako lidé tím, že se učí z dat.
V tomto článku prozkoumáme různé typy algoritmy strojového učení které jsou důležité pro budoucí požadavky. Strojové učení je obecně tréninkový systém, který se učí z minulých zkušeností a zlepšuje výkon v průběhu času. Strojové učení pomáhá předpovídat obrovské množství dat. Pomáhá poskytovat rychlé a přesné výsledky, abyste získali ziskové příležitosti.
Typy strojového učení
Existuje několik typů strojového učení, z nichž každý má speciální vlastnosti a aplikace. Některé z hlavních typů algoritmů strojového učení jsou následující:
- Strojové učení pod dohledem
- Strojové učení bez dozoru
- Částečně řízené strojové učení
- Posílení učení
Typy strojového učení
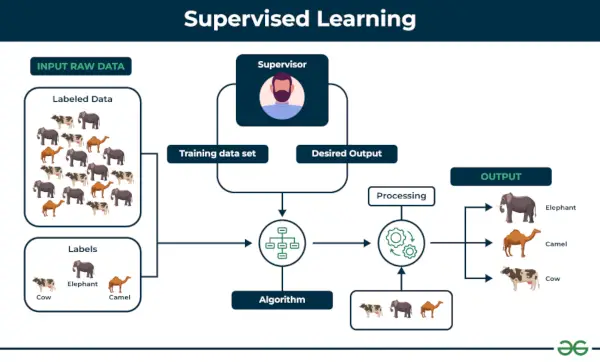
1. Strojové učení pod dohledem
Učení pod dohledem je definován jako když se model trénuje na a Označená datová sada . Označené datové sady mají vstupní i výstupní parametry. v Učení pod dohledem algoritmy se učí mapovat body mezi vstupy a správnými výstupy. Má označeny jak tréninkové, tak ověřovací datové sady.
Učení pod dohledem
Pojďme to pochopit pomocí příkladu.
Příklad: Zvažte scénář, kde musíte vytvořit klasifikátor obrázků, abyste rozlišili mezi kočkami a psy. Pokud zadáte datové sady psů a koček označených obrázků do algoritmu, stroj se naučí klasifikovat mezi psem a kočkou z těchto označených obrázků. Když vložíme nové obrázky psa nebo kočky, které ještě nikdy neviděli, použije naučené algoritmy a předpoví, zda se jedná o psa nebo kočku. Takto učení pod dohledem funguje, a to je zejména klasifikace obrazu.
jak třídit seznam polí v jazyce Java
Existují dvě hlavní kategorie výuky pod dohledem, které jsou uvedeny níže:
- Klasifikace
- Regrese
Klasifikace
Klasifikace zabývá se předpovídáním kategorický cílové proměnné, které představují diskrétní třídy nebo štítky. Například klasifikovat e-maily jako spam či nikoli nebo předpovídat, zda má pacient vysoké riziko srdečních onemocnění. Klasifikační algoritmy se učí mapovat vstupní vlastnosti do jedné z předdefinovaných tříd.
Zde jsou některé klasifikační algoritmy:
- Logistická regrese
- Podpora Vector Machine
- Náhodný les
- Rozhodovací strom
- K-Nearest Neighbors (KNN)
- Naivní Bayes
Regrese
Regrese , na druhé straně se zabývá předpovídáním kontinuální cílové proměnné, které představují číselné hodnoty. Například předpovídání ceny domu na základě jeho velikosti, polohy a vybavení nebo předpovídání prodeje produktu. Regresní algoritmy se učí mapovat vstupní prvky na spojitou číselnou hodnotu.
Zde jsou některé regresní algoritmy:
- Lineární regrese
- Polynomiální regrese
- Ridge Regrese
- Regrese lasem
- Rozhodovací strom
- Náhodný les
Výhody řízeného strojového učení
- Učení pod dohledem modely mohou mít vysokou přesnost, jak jsou trénovány označené údaje .
- Proces rozhodování v modelech učení pod dohledem je často interpretovatelný.
- Často jej lze použít v předem vyškolených modelech, což šetří čas a prostředky při vývoji nových modelů od nuly.
Nevýhody řízeného strojového učení
- Má omezení ve znalosti vzorců a může se potýkat s neviditelnými nebo neočekávanými vzory, které nejsou přítomny v trénovacích datech.
- Může to být časově náročné a nákladné, protože se na to spoléhá označené pouze údaje.
- To může vést ke špatným zobecněním na základě nových údajů.
Aplikace řízeného učení
Učení pod dohledem se používá v široké škále aplikací, včetně:
- Klasifikace obrázků : Identifikujte objekty, tváře a další prvky na snímcích.
- Zpracování přirozeného jazyka: Extrahujte z textu informace, jako je sentiment, entity a vztahy.
- Rozpoznávání řeči : Převod mluveného jazyka na text.
- Systémy doporučení : Vytvářejte personalizovaná doporučení uživatelům.
- Prediktivní analytika : Předvídejte výsledky, jako jsou prodeje, odchod zákazníků a ceny akcií.
- Lékařská diagnóza : Zjistit nemoci a další zdravotní stavy.
- Odhalování podvodů : Identifikujte podvodné transakce.
- Autonomní vozidla : Rozpoznejte objekty v prostředí a reagujte na ně.
- Detekce e-mailového spamu : Klasifikujte e-maily jako spam nebo nikoli.
- Kontrola kvality ve výrobě : Zkontrolujte produkty, zda nemají vady.
- Kreditní bodování : Posuďte riziko, že dlužník nesplácí úvěr.
- Hraní : Rozpoznejte postavy, analyzujte chování hráčů a vytvářejte NPC.
- Zákaznická podpora : Automatizujte úkoly zákaznické podpory.
- Předpověď počasí : Provádějte předpovědi teploty, srážek a dalších meteorologických parametrů.
- Sportovní analytika : Analyzujte výkon hráče, provádějte předpovědi hry a optimalizujte strategie.
2. Strojové učení bez dozoru
Učení bez dozoru Učení bez dozoru je typ techniky strojového učení, ve kterém algoritmus objevuje vzorce a vztahy pomocí neoznačených dat. Na rozdíl od kontrolovaného učení nezahrnuje učení bez dozoru poskytnutí algoritmu s označenými cílovými výstupy. Primárním cílem učení bez dozoru je často objevování skrytých vzorců, podobností nebo shluků v datech, které pak lze použít pro různé účely, jako je průzkum dat, vizualizace, redukce rozměrů a další.
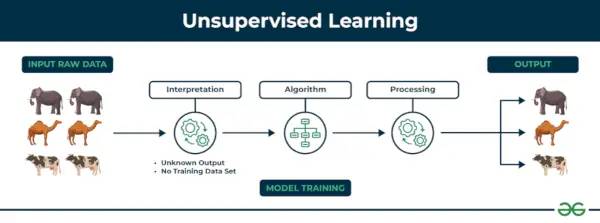
Učení bez dozoru
Pojďme to pochopit pomocí příkladu.
Příklad: Zvažte, že máte datovou sadu, která obsahuje informace o nákupech, které jste v obchodě provedli. Prostřednictvím shlukování může algoritmus seskupit stejné nákupní chování mezi vámi a ostatními zákazníky, což odhalí potenciální zákazníky bez předem definovaných štítků. Tento typ informací může firmám pomoci získat cílové zákazníky a také identifikovat odlehlé hodnoty.
Níže jsou uvedeny dvě hlavní kategorie učení bez dozoru:
- Shlukování
- Sdružení
Shlukování
Shlukování je proces seskupování datových bodů do shluků na základě jejich podobnosti. Tato technika je užitečná pro identifikaci vzorců a vztahů v datech, aniž by bylo nutné používat označené příklady.
Zde jsou některé shlukovací algoritmy:
- Algoritmus shlukování K-Means
- Algoritmus středního posunu
- Algoritmus DBSCAN
- Analýza hlavních komponent
- Nezávislá analýza komponent
Sdružení
Naučte se asociační pravidlo ing je technika pro zjišťování vztahů mezi položkami v datové sadě. Identifikuje pravidla, která naznačují, že přítomnost jedné položky implikuje přítomnost jiné položky se specifickou pravděpodobností.
Zde jsou některé algoritmy učení asociačních pravidel:
- Apriori algoritmus
- Záře
- FP-růstový algoritmus
Výhody strojového učení bez dozoru
- Pomáhá odhalovat skryté vzorce a různé vztahy mezi daty.
- Používá se pro úkoly jako např segmentace zákazníků, detekce anomálií, a průzkum dat .
- Nevyžaduje označená data a snižuje náročnost označování dat.
Nevýhody strojového učení bez dozoru
- Bez použití štítků může být obtížné předpovědět kvalitu výstupu modelu.
- Interpretovatelnost klastrů nemusí být jasná a nemusí mít smysluplné interpretace.
- Disponuje technikami jako např automatické kodéry a zmenšení rozměrů které lze použít k extrahování smysluplných funkcí z nezpracovaných dat.
Aplikace nekontrolovaného učení
Zde jsou některé běžné aplikace učení bez dozoru:
srovnání s javou
- Shlukování : Seskupte podobné datové body do shluků.
- Detekce anomálií : Identifikujte odlehlé hodnoty nebo anomálie v datech.
- Redukce rozměrů : Snižte rozměrnost dat při zachování jejich základních informací.
- Systémy doporučení : Navrhujte uživatelům produkty, filmy nebo obsah na základě jejich historického chování nebo preferencí.
- Tématické modelování : Objevte latentní témata ve sbírce dokumentů.
- Odhad hustoty : Odhad funkce hustoty pravděpodobnosti dat.
- Komprese obrazu a videa : Snižte velikost úložného prostoru potřebného pro multimediální obsah.
- Předzpracování dat : Pomoc s úlohami předběžného zpracování dat, jako je čištění dat, imputace chybějících hodnot a škálování dat.
- Analýza tržního koše : Objevte souvislosti mezi produkty.
- Analýza genomických dat : Identifikujte vzory nebo skupiny genů s podobnými profily exprese.
- Segmentace obrazu : Segmentujte obrázky do smysluplných oblastí.
- Detekce komunity na sociálních sítích : Identifikujte komunity nebo skupiny jednotlivců s podobnými zájmy nebo vazbami.
- Analýza chování zákazníků : Odhalte vzory a poznatky pro lepší marketing a doporučení produktů.
- Doporučení obsahu : Klasifikujte a označujte obsah, abyste uživatelům snáze doporučovali podobné položky.
- Průzkumná analýza dat (EDA) : Prozkoumejte data a získejte přehled před definováním konkrétních úkolů.
3. Semi-supervised learning
Semi-supervised learning je algoritmus strojového učení, který funguje mezi pod dohledem i bez dozoru učení, takže používá obojí označené a neoznačené data. Je to užitečné zejména tehdy, když je získávání označených dat nákladné, časově náročné nebo náročné na zdroje. Tento přístup je užitečný, když je datová sada drahá a časově náročná. Semi-supervised learning se volí, když označená data vyžadují dovednosti a relevantní zdroje, aby je bylo možné trénovat nebo se z nich učit.
Tyto techniky používáme, když se zabýváme daty, která jsou trochu označená a velká část z nich je neoznačená. Můžeme použít techniky bez dozoru k predikci štítků a poté tyto štítky předat technikám pod dohledem. Tato technika je většinou použitelná v případě sad obrazových dat, kde obvykle nejsou všechny obrázky označeny.
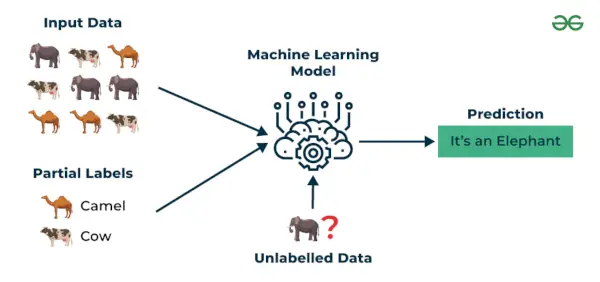
Semi-supervised learning
Pojďme to pochopit pomocí příkladu.
Příklad : Vezměte v úvahu, že budujeme model jazykového překladu. Označení překladů pro každý pár vět může být náročné na zdroje. Umožňuje modelům učit se z označených a neoznačených dvojic vět, což je činí přesnějšími. Tato technika vedla k výraznému zlepšení kvality služeb strojového překladu.
Typy metod učení s částečným dohledem
Existuje celá řada různých metod učení pod dohledem, z nichž každá má své vlastní charakteristiky. Mezi ty nejběžnější patří:
- Výuka pod dohledem založená na grafech: Tento přístup používá graf pro znázornění vztahů mezi datovými body. Graf se pak používá k šíření značek z označených datových bodů do neoznačených datových bodů.
- Šíření štítků: Tento přístup iterativně šíří značky z označených datových bodů do neoznačených datových bodů na základě podobnosti mezi datovými body.
- Společný trénink: Tento přístup trénuje dva různé modely strojového učení na různých podskupinách neoznačených dat. Tyto dva modely se pak používají ke vzájemnému označení předpovědí.
- Samotrénink: Tento přístup trénuje model strojového učení na označených datech a poté tento model používá k predikci označení pro neoznačená data. Model je poté přeškolen na označená data a předpokládané značky pro neoznačená data.
- Generativní adversariální sítě (GAN) : GAN jsou typem algoritmu hlubokého učení, který lze použít ke generování syntetických dat. GAN lze použít ke generování neoznačených dat pro polořízené učení pomocí trénování dvou neuronových sítí, generátoru a diskriminátoru.
Výhody polořízeného strojového učení
- Vede k lepšímu zobecnění ve srovnání s učení pod dohledem, protože bere jak označená, tak neoznačená data.
- Lze použít na širokou škálu dat.
Nevýhody polořízeného strojového učení
- Částečně pod dohledem metody mohou být složitější na implementaci ve srovnání s jinými přístupy.
- Stále to nějaké vyžaduje označené údaje které nemusí být vždy dostupné nebo snadno dostupné.
- Neoznačená data mohou odpovídajícím způsobem ovlivnit výkon modelu.
Aplikace polořízeného učení
Zde jsou některé běžné aplikace polořízeného učení:
- Klasifikace obrazu a rozpoznávání objektů : Zlepšete přesnost modelů kombinací malé sady označených obrázků s větší sadou neoznačených obrázků.
- Zpracování přirozeného jazyka (NLP) : Zvyšte výkon jazykových modelů a klasifikátorů kombinací malé sady dat označených textů s velkým množstvím textu bez označení.
- Rozpoznávání řeči: Zlepšete přesnost rozpoznávání řeči využitím omezeného množství přepsaných řečových dat a rozsáhlejší sady neoznačeného zvuku.
- Systémy doporučení : Zlepšete přesnost personalizovaných doporučení tím, že doplníte řídkou sadu interakcí mezi uživateli (označená data) velkým množstvím neoznačených dat o chování uživatelů.
- Zdravotní péče a lékařské zobrazování : Vylepšete analýzu lékařských snímků využitím malé sady označených lékařských snímků vedle větší sady neoznačených snímků.
4. Posílení strojového učení
Posílení strojového učení Algoritmus je metoda učení, která interaguje s prostředím vytvářením akcí a odhalováním chyb. Pokus, omyl a zpoždění jsou nejdůležitější charakteristiky posilovacího učení. V této technice model neustále zvyšuje svůj výkon pomocí zpětné vazby odměňování, aby se naučil chování nebo vzor. Tyto algoritmy jsou specifické pro konkrétní problém, např. Samořídící auto Google, AlphaGo, kde robot soutěží s lidmi a dokonce sám se sebou, aby ve hře Go získal stále lepší výkon. Pokaždé, když vkládáme data, učí se a přidávají data ke svým znalostem, což jsou trénovací data. Čím více se tedy učí, tím lépe se trénuje a tím pádem i prožívá.
Zde jsou některé z nejběžnějších výukových algoritmů:
- Q-learning: Q-learning je bezmodelový RL algoritmus, který se učí Q-funkci, která mapuje stavy na akce. Q-funkce odhaduje očekávanou odměnu za provedení konkrétní akce v daném stavu.
- SARSA (State-Action-Reward-State-Action): SARSA je další bezmodelový RL algoritmus, který se učí Q-funkci. Na rozdíl od Q-learningu však SARSA aktualizuje Q-funkci pro akci, která byla skutečně provedena, spíše než pro optimální akci.
- Hluboké Q-učení : Hluboké Q-learning je kombinací Q-learningu a hlubokého učení. Hluboké Q-učení využívá neuronovou síť k reprezentaci Q-funkce, která mu umožňuje učit se složité vztahy mezi stavy a akcemi.
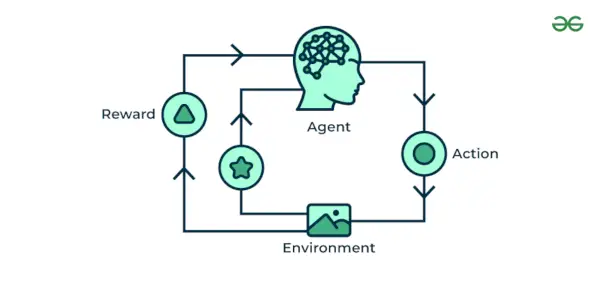
Posílení strojového učení
Pojďme to pochopit pomocí příkladů.
Příklad: Zvažte, že trénujete an AI agent hrát hru jako šachy. Agent zkoumá různé pohyby a na základě výsledku dostává pozitivní nebo negativní zpětnou vazbu. Posílení učení také nachází aplikace, ve kterých se učí plnit úkoly interakcí se svým okolím.
Typy strojového učení výztuže
Existují dva hlavní typy posilovacího učení:
Pozitivní posílení
- Odměňuje agenta za provedení požadované akce.
- Povzbuzuje agenta k opakování chování.
- Příklady: Podání pamlsku psovi na sezení, udělení bodu ve hře za správnou odpověď.
Negativní zesílení
- Odstraňuje nežádoucí podněty k povzbuzení žádoucího chování.
- Odrazuje agenta od opakování chování.
- Příklady: Vypnutí hlasitého bzučáku při stisknutí páky, vyhnutí se trestu dokončením úkolu.
Výhody posilovacího strojového učení
- Má autonomní rozhodování, které se dobře hodí pro úkoly a které se může naučit dělat řadu rozhodnutí, jako je robotika a hraní her.
- Tato technika je preferována pro dosažení dlouhodobých výsledků, kterých je velmi obtížné dosáhnout.
- Používá se k řešení složitých problémů, které nelze vyřešit konvenčními technikami.
Nevýhody posilovacího strojového učení
- Posílení školení Učící agenti mohou být výpočetně nákladní a časově nároční.
- Posilování učení není lepší než řešení jednoduchých problémů.
- Potřebuje mnoho dat a mnoho výpočtů, což jej činí nepraktickým a nákladným.
Aplikace strojového učení výztuže
Zde jsou některé aplikace posilovacího učení:
- Hraní her : RL může naučit agenty hrát hry, dokonce i ty složité.
- Robotika : RL může naučit roboty vykonávat úkoly autonomně.
- Autonomní vozidla : RL může pomoci samořídícím vozům navigovat a rozhodovat se.
- Systémy doporučení : RL může zlepšit algoritmy doporučení tím, že se naučí uživatelské preference.
- Zdravotní péče : RL lze použít k optimalizaci léčebných plánů a objevování léků.
- Zpracování přirozeného jazyka (NLP) : RL lze použít v dialogových systémech a chatbotech.
- Finance a obchodování : RL lze použít pro algoritmické obchodování.
- Řízení dodavatelského řetězce a zásob : RL lze použít k optimalizaci operací dodavatelského řetězce.
- Energetický management : RL lze použít k optimalizaci spotřeby energie.
- AI hry : RL lze použít k vytvoření inteligentnějších a adaptivnějších NPC ve videohrách.
- Adaptivní osobní asistenti : RL lze použít ke zlepšení osobních asistentů.
- Virtuální realita (VR) a rozšířená realita (AR): RL lze použít k vytvoření pohlcujících a interaktivních zážitků.
- Průmyslová kontrola : RL lze použít k optimalizaci průmyslových procesů.
- Vzdělání : RL lze použít k vytvoření adaptivních učebních systémů.
- Zemědělství : RL lze použít k optimalizaci zemědělských operací.
Musíte zkontrolovat, náš podrobný článek o : Algoritmy strojového učení
mapování na stroji
Závěr
Závěrem lze říci, že každý typ strojového učení slouží svému vlastnímu účelu a přispívá k celkové úloze ve vývoji vylepšených schopností predikce dat a má potenciál změnit různá odvětví, jako je např. Data Science . Pomáhá řešit masivní produkci dat a správu datových sad.
Typy strojového učení – FAQ
1. Jakým výzvám čelíte při učení pod dohledem?
Některé z výzev, kterým čelí učení pod dohledem, zahrnují především řešení nerovnováhy ve třídě, vysoce kvalitní označená data a vyhýbání se nadměrnému vybavení tam, kde modely fungují špatně na datech v reálném čase.
2. Kde můžeme uplatnit řízené učení?
Učení pod dohledem se běžně používá pro úkoly, jako je analýza spamových e-mailů, rozpoznávání obrázků a analýza sentimentu.
3. Jak vypadá budoucnost strojového učení?
Strojové učení jako výhled do budoucna může fungovat v oblastech, jako je analýza počasí nebo klimatu, zdravotnické systémy a autonomní modelování.
4. Jaké jsou různé typy strojového učení?
Existují tři hlavní typy strojového učení:
- Učení pod dohledem
- Učení bez dozoru
- Posílení učení
5. Jaké jsou nejběžnější algoritmy strojového učení?
Některé z nejběžnějších algoritmů strojového učení zahrnují:
- Lineární regrese
- Logistická regrese
- Podpora vektorových strojů (SVM)
- K-nejbližší sousedé (KNN)
- Rozhodovací stromy
- Náhodné lesy
- Umělé neuronové sítě