Python je skvělý jazyk pro analýzu dat, především kvůli fantastickému ekosystému zaměřenému na data Krajta balíčky. pandy je jedním z těchto balíčků a značně usnadňuje import a analýzu dat.
Pandas DataFrame mean()
pandy dataframe.mean() funkce vrací průměr hodnot pro požadovanou osu. Pokud je metoda aplikována na objekt série pandas, pak metoda vrací skalární hodnotu, která je střední hodnotou všech pozorování v Dataframe Pandas . Pokud je metoda aplikována na objekt Pandas Dataframe, vrátí metoda a série Pandy objekt, který obsahuje průměr hodnot na zadané ose.
Syntax: DataFrame.mean(osa=0, skipna=True, level=None, numeric_only=False, **kwargs)
Parametry:
- osa: {index (0), sloupce (1)}
- objednat : Při výpočtu výsledku vylučte hodnoty NA/null
- úroveň : Pokud je osa MultiIndex (hierarchická), počítejte podél konkrétní úrovně a sbalte se do řady
- numeric_only : Zahrňte pouze sloupce float, int, boolean. Pokud Žádné, pokusí se použít vše, pak použijte pouze číselná data. Není implementováno pro Series.
Vrátí: střední : Series nebo DataFrame (pokud je úroveň specifikována)
binární strom v Javě
Příklady Pandas DataFrame.mean().
Příklad 1:
Použijte funkci mean() k nalezení střední hodnoty všech pozorování na ose indexu.
Krajta # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, 44, 1], 'B':[5, 2, 54, 3, 2], 'C':[20, 16, 7, 3, 8], 'D':[14, 3, 17, 2, 6]}) # Print the dataframe df> 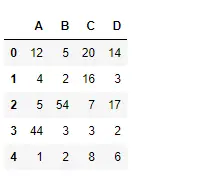
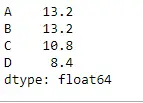
Použijme funkci Dataframe.mean() k nalezení střední hodnoty na ose indexu.
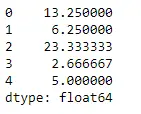
Krajta # Even if we do not specify axis = 0, # the method will return the mean over # the index axis by default df.mean(axis = 0)>
Výstup:
Příklad 2:
Použijte funkci mean() na Dataframe, který nemá žádné hodnoty. Také najděte průměr přes osu sloupce.
Krajta # importing pandas as pd import pandas as pd # Creating the dataframe df = pd.DataFrame({'A':[12, 4, 5, None, 1], 'B':[7, 2, 54, 3, None], 'C':[20, 16, 11, 3, 8], 'D':[14, 3, None, 2, 6]}) # skip the Na values while finding the mean df.mean(axis = 1, skipna = True)> Výstup: