pandy dataframe.corr() se používá k nalezení párové korelace všech sloupců v datovém rámci Pandas v Pythonu. Žádný NaN hodnoty jsou automaticky vyloučeny. Chcete-li ignorovat jakékoli nečíselné hodnoty, použijte parametr numeric_only = True. V tomto článku se dozvíme o metodě DataFrame.corr() v Krajta .
řazení java arraylist
Syntaxe metody Pandas DataFrame corr().
Syntax: DataFrame.corr(self, method=’pearson’, min_periods=1, numeric_only = False)
Parametry:
- metoda:
- pearson: standardní korelační koeficient
- kendall: Kendall Tau korelační koeficient
- oštěpař: Korelace hodnosti oštěpaře
- min_periody : Minimální počet pozorování požadovaný na pár sloupců, aby byl výsledek platný. V současné době je k dispozici pouze pro korelaci pearson a spearman
- numeric_only : Zda se má či nemá pracovat pouze s číselnými hodnotami. Ve výchozím nastavení je nastavena na False.
Vrácení: count :y : DataFrame
Metoda korelace dat Pandas corr().
Dobrá korelace závisí na použití, ale lze s jistotou říci, že máte alespoň 0,6 (nebo -0,6), abyste to nazvali dobrou korelací. Jednoduchý příklad, který ukazuje, jak funguje korelace Krajta .
Python3
import> pandas as pd> df>=> {> >'Array_1'>: [>30>,>70>,>100>],> >'Array_2'>: [>65.1>,>49.50>,>30.7>]> }> data>=> pd.DataFrame(df)> print>(data.corr())> |
>
>
Výstup
Array_1 Array_2 Array_1 1.000000 -0.990773 Array_2 -0.990773 1.000000>
Vytvoření ukázkového datového rámce
Tisk prvních 10 řádků datového rámce.
Poznámka: Korelace proměnné sama se sebou je 1. Pro odkaz na soubor CSV použitý v kódu klikněte tady
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # Printing the first 10 rows of the data frame for visualization> df[:>10>]> |
>
>
Výstup

Příklady metody Python Pandas DataFrame corr().
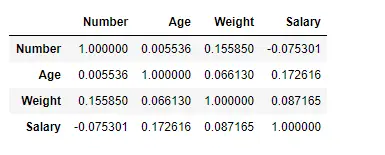
Najděte korelaci mezi sloupci pomocí Pearsonovy metody
Zde používáme funkci corr() k nalezení korelace mezi sloupci v datovém rámci pomocí metody ‚Pearson‘. V datovém rámci máme pouze čtyři číselné sloupce. Výstupní Dataframe lze interpretovat jako pro libovolnou buňku, korelace řádkové proměnné s proměnnou sloupce je hodnota buňky. Jak již bylo zmíněno dříve, korelace proměnné sama se sebou je 1. Z toho důvodu jsou všechny hodnoty diagonál 1,00.
Python3
# To find the correlation among> # the columns using pearson method> df.corr(method>=>'pearson'>)> |
>
>
Výstup
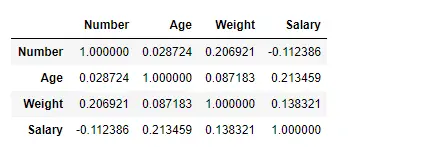
Najděte korelaci mezi sloupci pomocí Kendallovy metody
Použijte funkci Pandas df.corr() k nalezení korelace mezi sloupci v datovém rámci pomocí metody „kendall“. Výstupní Dataframe lze interpretovat jako pro libovolnou buňku, korelace řádkové proměnné s proměnnou sloupce je hodnota buňky. Jak již bylo zmíněno dříve, korelace proměnné sama se sebou je 1. Z toho důvodu jsou všechny hodnoty diagonál 1,00.
Python3
# importing pandas as pd> import> pandas as pd> # Making data frame from the csv file> df>=> pd.read_csv(>'nba.csv'>)> # To find the correlation among> # the columns using kendall method> df.corr(method>=>'kendall'>)> |
>
>
Výstup