Glob je obecný termín používaný k definování technik pro porovnání specifikovaných vzorů podle pravidel souvisejících s unixovým shellem. Linuxové a unixové systémy a shelly také podporují glob a také poskytují funkceglob()>v systémových knihovnách.
V Pythonu se k načítání používá modul glob soubory/názvy cest odpovídající zadanému vzoru. Pravidla vzoru glob se řídí standardními pravidly rozšíření cest Unixu. Také se předpokládá, že podle benchmarků je rychlejší než jiné metody přiřazování názvů cest v adresářích. S glob můžeme také použít zástupné znaky('*, ?, [ranges])>kromě přesného vyhledávání řetězců, aby bylo vyhledávání cesty jednodušší a pohodlnější.
parametr ve skriptu shellu
Poznámka: Tento modul je dodáván vestavěný s Pythonem, takže jej není třeba instalovat externě.
Příklad:
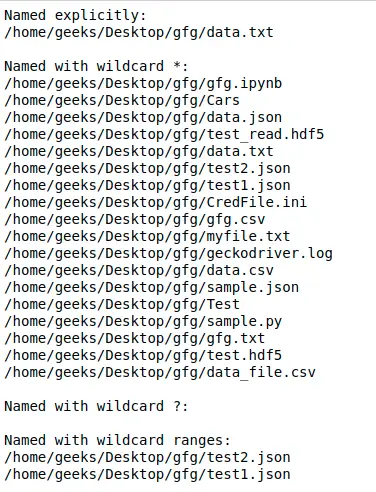
# Python program to demonstrate> # glob using different wildcards> > > import> glob> > > print>(>'Named explicitly:'>)> for> name>in> glob.glob(>'/home/geeks/Desktop/gfg/data.txt'>):> >print>(name)> > # Using '*' pattern> print>(>'
Named with wildcard *:'>)> for> name>in> glob.glob(>'/home/geeks/Desktop/gfg/*'>):> >print>(name)> > # Using '?' pattern> print>(>'
Named with wildcard ?:'>)> for> name>in> glob.glob(>'/home/geeks/Desktop/gfg/data?.txt'>):> >print>(name)> > # Using [0-9] pattern> print>(>'
Named with wildcard ranges:'>)> for> name>in> glob.glob(>'/home/geeks/Desktop/gfg/*[0-9].*'>):> >print>(name)> |
>
>
Výstup :
uml diagram java
Použití funkce Glob() k rekurzivnímu vyhledání souborů
Můžeme použít funkciglob.glob()>neboglob.iglob()>přímo z modulu glob pro rekurzivní načítání cest z adresářů/souborů a podadresářů/podsouborů.
kolekce java
Syntax:
glob.glob(pathname, *, recursive=False)>
glob.iglob(pathname, *, recursive=False)>
Poznámka: Když je nastaveno rekurzivníTrue> **>následuje oddělovač cesty('./**/')>bude odpovídat všem souborům nebo adresářům.
Příklad:
# Python program to find files> # recursively using Python> > > import> glob> > > # Returns a list of names in list files.> print>(>'Using glob.glob()'>)> files>=> glob.glob(>'/home/geeks/Desktop/gfg/**/*.txt'>,> >recursive>=> True>)> for> file> in> files:> >print>(>file>)> > > # It returns an iterator which will> # be printed simultaneously.> print>(>'
Using glob.iglob()'>)> for> filename>in> glob.iglob(>'/home/geeks/Desktop/gfg/**/*.txt'>,> >recursive>=> True>):> >print>(filename)> |
>
>
Výstup :

Pro starší verze pythonu:
Nejjednodušší metodou je použití os.walk() protože je speciálně navržen a optimalizován tak, aby umožňoval rekurzivní procházení stromu adresářů. Nebo můžeme také použít os.listdir() získat všechny soubory v adresáři a podadresářích a poté odfiltrovat.
jak spárovat sluchátka beats
Podívejme se na to na příkladu -
Příklad:
jak inicializovat pole v Javě
# Python program to find files> # recursively using Python> > > import> os> > # Using os.walk()> for> dirpath, dirs, files>in> os.walk(>'src'>):> >for> filename>in> files:> >fname>=> os.path.join(dirpath,filename)> >if> fname.endswith(>'.c'>):> >print>(fname)> > '''> Or> We can also use fnmatch.filter()> to filter out results.> '''> for> dirpath, dirs, files>in> os.walk(>'src'>):> >for> filename>in> fnmatch.>filter>(files,>'*.c'>):> >print>(os.path.join(dirpath, filename))> > # Using os.listdir()> path>=> 'src'> dir_list>=> os.listdir(path)> for> filename>in> fnmatch.>filter>(dir_list,>'*.c'>):> >print>(os.path.join(dirpath, filename))> |
>
>
Výstup :
./src/add.c ./src/subtract.c ./src/sub/mul.c ./src/sub/div.c ./src/add.c ./src/subtract.c ./src/sub/mul.c ./src/sub/div.c ./src/add.c ./src/subtract.c ./src/sub/mul.c ./src/sub/div.c>