Následující architektura vysvětluje tok odesílání dotazů do Hive.
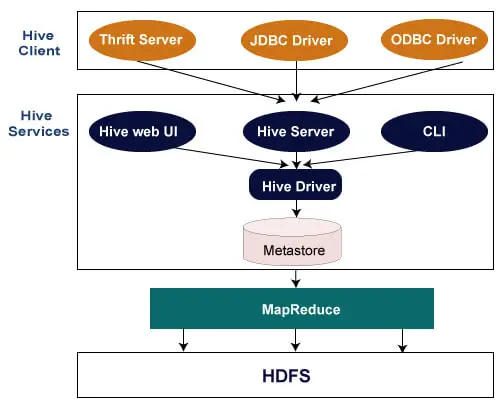
Klient Hive
Hive umožňuje psát aplikace v různých jazycích, včetně Javy, Pythonu a C++. Podporuje různé typy klientů, jako jsou: -
- Thrift Server – Jedná se o platformu poskytovatele služeb pro více jazyků, která slouží požadavkům všech programovacích jazyků, které podporují Thrift.
- JDBC Driver – Slouží k navázání spojení mezi úlem a Java aplikacemi. Ovladač JDBC je přítomen ve třídě org.apache.hadoop.hive.jdbc.HiveDriver.
- ODBC Driver – Umožňuje aplikacím, které podporují protokol ODBC, připojit se k Hive.
Úlové služby
Následující služby poskytuje Hive: -
- Hive CLI - Hive CLI (Command Line Interface) je shell, ve kterém můžeme provádět dotazy a příkazy Hive.
- Webové uživatelské rozhraní Hive – Webové uživatelské rozhraní Hive je pouze alternativou rozhraní Hive CLI. Poskytuje webové GUI pro provádění dotazů a příkazů Hive.
- Hive MetaStore – Jedná se o centrální úložiště, které ukládá všechny informace o struktuře různých tabulek a oddílů ve skladu. Zahrnuje také metadata sloupce a informace o jeho typu, serializátory a deserializátory, které se používají ke čtení a zápisu dat, a odpovídající soubory HDFS, kde jsou data uložena.
- Hive Server – Označuje se jako Apache Thrift Server. Přijímá požadavek od různých klientů a poskytuje jej Hive Driver.
- Hive Driver – přijímá dotazy z různých zdrojů, jako je webové uživatelské rozhraní, CLI, Thrift a ovladač JDBC/ODBC. Přenese dotazy do kompilátoru.
- Kompilátor úlu - Účelem kompilátoru je analyzovat dotaz a provádět sémantickou analýzu různých bloků dotazu a výrazů. Převádí příkazy HiveQL na úlohy MapReduce.
- Hive Execution Engine – Optimizer generuje logický plán ve formě DAG úkolů map-reduce a HDFS úkolů. Prováděcí jádro nakonec provede příchozí úlohy v pořadí jejich závislostí.