Thegrep>příkaz v Unixu/Linuxu je mocný nástroj používaný pro vyhledávání a manipulaci s textovými vzory v souborech. Jeho název je odvozen od ed (editorského) příkazu g/re/p (globálně vyhledat regulární výraz a vytisknout odpovídající řádky), což odráží jeho základní funkcionalitu.grep>je široce používán programátory, správci systému i uživateli pro jeho efektivitu a všestrannost při práci s textovými daty. V tomto článku prozkoumáme různé aspektygrep>příkaz.
Obsah
- Syntaxe příkazu grep v Unixu/Linuxu
- Možnosti dostupné v příkazu grep
- Praktický příklad příkazu grep v Linuxu
- 1. Vyhledávání bez rozlišení malých a velkých písmen
- 2. Zobrazení počtu shod pomocí grep
- 3. Zobrazte názvy souborů, které odpovídají vzoru pomocí grep
- 4. Kontrola celých slov v souboru pomocí grep
- 5. Zobrazení pouze shodného vzoru Pomocí grep
- 6. Zobrazte číslo řádku při zobrazení výstupu pomocí grep -n
- 7. Invertování shody vzoru pomocí grep
- 8. Porovnání řádků, které začínají řetězcem pomocí grep
- 9. Porovnání čar, které končí řetězcem pomocí grep
- 10.Určuje výraz s volbou -e
- 11. Volba -f soubor Převezme vzory ze souboru, jeden na řádek
- 12. Tisk n konkrétních řádků ze souboru pomocí grep
- 13. Rekurzivně vyhledejte vzor v adresáři
Syntaxe příkazu grep v Unixu/Linuxu
Základní syntaxe ` grep`> příkaz je následující:
nekonečná smyčka
grep [options] pattern [files]>
Tady,
[> options> ]>: Toto jsou příznaky příkazového řádku, které upravují chovánígrep>.
[> pattern> ]>: Toto je regulární výraz, který chcete vyhledat.
[> file> ]>: Toto je název souboru (souborů), ve kterém chcete hledat. Můžete zadat více souborů pro současné vyhledávání.
Možnosti dostupné v příkazu grep
| Možnosti | Popis |
|---|---|
| -C | Tím se vytiskne pouze počet řádků, které odpovídají vzoru |
| -h | Zobrazit odpovídající řádky, ale nezobrazovat názvy souborů. |
| – i | Ignoruje, případ pro shodu |
| -l | Zobrazí pouze seznam názvů souborů. |
| -n | Zobrazte odpovídající řádky a jejich čísla řádků. |
| -v | Tím se vytisknou všechny čáry, které neodpovídají vzoru |
| -e zk | Určuje výraz s touto volbou. Lze použít vícekrát. |
| -f soubor | Přebírá vzory ze souboru, jeden na řádek. |
| -A | Zachází se vzorem jako s rozšířeným regulárním výrazem (ERE) powershell víceřádkový komentář |
| -V | Spoj celé slovo |
| -Ó | Vytiskněte pouze odpovídající části odpovídající čáry, přičemž každá taková část bude na samostatném výstupním řádku. |
| -A n | Vytiskne hledaný řádek a nřádky po výsledku. |
| -B n linuxový příkaz spustit | Vytiskne hledaný řádek a n řádek před výsledkem. |
| -C n | Vytiskne hledaný řádek a n řádků před výsledkem. |
Ukázkové příkazy
Považujte níže uvedený soubor za vstup.
cat>geekfile.txt>
unix je skvělý operační systém. unix byl vyvinut v Bellových laboratořích.
naučit se operační systém.
Unix linux, který si vyberete.
uNix se snadno učí.unix je víceuživatelský operační systém.Učte se unix .unix je výkonný.
Praktický příklad příkazu grep v Linuxu
1. Vyhledávání bez rozlišení malých a velkých písmen
Volba -i umožňuje v daném souboru necitlivě hledat malá a velká písmena. Odpovídá slovům jako UNIX, Unix, unix.
grep -i 'UNix' geekfile.txt>
Výstup:

Vyhledávání bez rozlišení malých a velkých písmen
2. Zobrazení počtu shod pomocí grep
Můžeme najít počet řádků, které odpovídají danému řetězci/vzoru
grep -c 'unix' geekfile.txt>
Výstup:

Zobrazení počtu zápasů
3. Zobrazte názvy souborů, které odpovídají vzoru pomocí grep
Můžeme pouze zobrazit soubory, které obsahují daný řetězec/vzor.
grep -l 'unix' *>
nebo
grep -l 'unix' f1.txt f2.txt f3.xt f4.txt>
Výstup:
Důležité

Název souboru, který odpovídá vzoru
4. Kontrola celých slov v souboru pomocí grep
Ve výchozím nastavení grep odpovídá danému řetězci/vzoru, i když je v souboru nalezen jako podřetězec. Volba -w pro grep způsobí, že bude odpovídat pouze celým slovům.
grep -w 'unix' geekfile.txt>
Výstup:

kontrola celých slov v souboru
5. Zobrazení pouze shodného vzoru Pomocí grep
Ve výchozím nastavení grep zobrazuje celý řádek, který má odpovídající řetězec. Pomocí volby -o můžeme nastavit grep tak, aby zobrazoval pouze odpovídající řetězec.
grep -o 'unix' geekfile.txt>
Výstup:
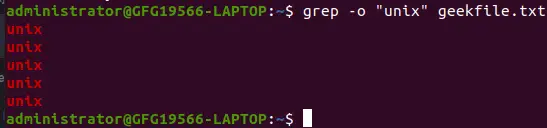
Zobrazení pouze shodného vzoru
6. Zobrazte číslo řádku při zobrazení výstupu pomocí grep -n
Chcete-li zobrazit číslo řádku souboru s odpovídajícím řádkem.
grep -n 'unix' geekfile.txt>
Výstup:

Při zobrazení výstupu zobrazit číslo řádku
7. Invertování shody vzoru pomocí grep
Řádky, které neodpovídají zadanému vzoru vyhledávacího řetězce, můžete zobrazit pomocí volby -v.
grep -v 'unix' geekfile.txt>
Výstup:

Invertování shody vzoru
8. Porovnání řádků, které začínají řetězcem pomocí grep
Vzor regulárního výrazu ^ určuje začátek řádku. To lze použít v grep, aby odpovídalo řádkům, které začínají daným řetězcem nebo vzorem.
grep '^unix' geekfile.txt>
Výstup:

Přiřazení řádků, které začínají řetězcem
co je shlukování
9. Porovnání čar, které končí řetězcem pomocí grep
Vzor regulárního výrazu $ určuje konec řádku. To lze použít v grep k přiřazení řádků, které končí daným řetězcem nebo vzorem.
grep 'os$' geekfile.txt>
10.Určuje výraz s volbou -e
Lze použít vícekrát:
grep –e 'Agarwal' –e 'Aggarwal' –e 'Agrawal' geekfile.txt>
11. Volba -f soubor Převezme vzory ze souboru, jeden na řádek
cat pattern.txt>
Agarwal
Aggarwal
Agrawal
grep –f pattern.txt geekfile.txt>
12. Tisk n konkrétních řádků ze souboru pomocí grep
-A vytiskne hledaný řádek a n řádků za výsledkem, -B vytiskne hledaný řádek a n řádků před výsledkem a -C vytiskne hledaný řádek a n řádků za a před výsledkem.
Syntax:
grep -A[NumberOfLines(n)] [search] [file] grep -B[NumberOfLines(n)] [search] [file] grep -C[NumberOfLines(n)] [search] [file]>
Příklad:
grep -A1 learn geekfile.txt>
Výstup:

Tisk n konkrétních řádků ze souboru
13. Rekurzivně vyhledejte vzor v D sborník
-R vytiskne hledaný vzor v daném adresáři rekurzivně ve všech souborech.
Syntax:
grep -R [Search] [directory]>
Příklad:
grep -iR geeks /home/geeks>
Výstup:
./geeks2.txt:Well Hello Geeks ./geeks1.txt:I am a big time geek ---------------------------------- -i to search for a string case insensitively -R to recursively check all the files in the directory.>
Závěr
V tomto článku jsme diskutovali ogrep>příkaz v Linuxu, což je výkonný nástroj pro vyhledávání textu, který používá regulární výrazy k nalezení vzorů nebo textu v souborech. Nabízí různé možnosti, jako je rozlišování malých a velkých písmen, počítání shod a výpis názvů souborů. Díky možnosti rekurzivního vyhledávání, používání příznaků regulárních výrazů a přizpůsobení výstupu,grep>je životně důležitý nástroj pro uživatele Linuxu k efektivnímu zpracování úloh souvisejících s textem. Masteringgrep>zlepšuje vaši schopnost pracovat s textovými daty v prostředí Linuxu.