Předpoklad – Data Mining , míra podobnosti odkazuje na vzdálenost s dimenzemi reprezentujícími vlastnosti datového objektu v datové sadě. Pokud je tato vzdálenost menší, bude zde vysoká míra podobnosti, ale pokud je vzdálenost velká, bude míra podobnosti nízká. Některé z oblíbených měřítek podobnosti jsou –
- Euklidovská vzdálenost.
- Vzdálenost Manhattan.
- Podobnost Jaccard.
- Minkowski Vzdálenost.
- Kosinová podobnost.
Kosinusová podobnost je metrika, která pomáhá určit, jak podobné jsou datové objekty bez ohledu na jejich velikost. Můžeme měřit podobnost mezi dvěma větami v Pythonu pomocí kosinové podobnosti. V kosinové podobnosti se s datovými objekty v datové množině zachází jako s vektorem. Vzorec pro nalezení kosinové podobnosti mezi dvěma vektory je –
(x, y) = x . y / ||x|| ||y||>
kde,
- X . y = součin (tečka) vektorů ‚x‘ a ‚y‘.||x|| a ||a|| = délka (velikost) dvou vektorů ‚x‘ a ‚y‘.||x||
 ||a|| = pravidelný součin dvou vektorů ‚x‘ a ‚y‘.
||a|| = pravidelný součin dvou vektorů ‚x‘ a ‚y‘. Příklad: Zvažte příklad, abyste našli podobnost mezi dvěma vektory – 'X' a 'a' pomocí Kosinové podobnosti. Vektor „x“ má hodnoty, x = { 3, 2, 0, 5 } Vektor „y“ má hodnoty, y = { 1, 0, 0, 0} Vzorec pro výpočet kosinové podobnosti je:  (x, y) = x. y / ||x|| ||a||
(x, y) = x. y / ||x|| ||a||
x . y = 3*1 + 2*0 + 0*0 + 5*0 = 3 ||x|| = √ (3)^2 + (2)^2 + (0)^2 + (5)^2 = 6.16 ||y|| = √ (1)^2 + (0)^2 + (0)^2 + (0)^2 = 1 ∴ (x, y) = 3 / (6.16 * 1) = 0.49>
Rozdílnost mezi dvěma vektory „x“ a „y“ je dána –
∴ (x, y) = 1 - (x, y) = 1 - 0.49 = 0.51>
- Kosinová podobnost mezi dvěma vektory se měří v ‚θ‘.
- Pokud θ = 0°, vektory „x“ a „y“ se překrývají, což dokazuje, že jsou podobné.
- Pokud θ = 90°, vektory „x“ a „y“ jsou odlišné.
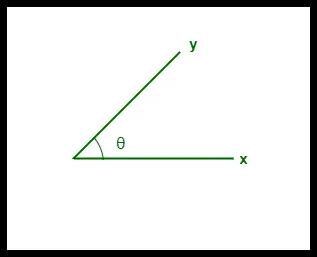
Kosinová podobnost mezi dvěma vektory
výhody:
- Kosinusová podobnost je výhodná, protože i když jsou dva podobné datové objekty daleko od sebe o euklidovskou vzdálenost kvůli velikosti, stále mezi sebou mohou mít menší úhel. Čím menší úhel, tím vyšší podobnost.
- Při vykreslování do vícerozměrného prostoru zachycuje kosinusová podobnost orientaci (úhel) datových objektů a nikoli velikost.