Od vynálezu počítačů lidé používají termín „ Data ' odkazovat na informace o počítači, přenášené nebo uložené. Existují však data, která existují i v typech objednávek. Data mohou být čísla nebo texty napsané na kus papíru ve formě bitů a bajtů uložených v paměti elektronických zařízení nebo fakta uložená v mysli člověka. Jak se svět začal modernizovat, tato data se stala významným aspektem každodenního života každého člověka a různé implementace jim umožnily ukládat je jinak.
Data je sbírka faktů a čísel nebo soubor hodnot nebo hodnot určitého formátu, který odkazuje na jednu sadu hodnot položek. Datové položky jsou pak klasifikovány do podpoložek, což je skupina položek, které nejsou známy jako jednoduchá primární forma položky.
Uvažujme příklad, kdy lze jméno zaměstnance rozdělit na tři podpoložky: First, Middle a Last. Nicméně ID přidělené zaměstnanci bude obecně považováno za jednu položku.
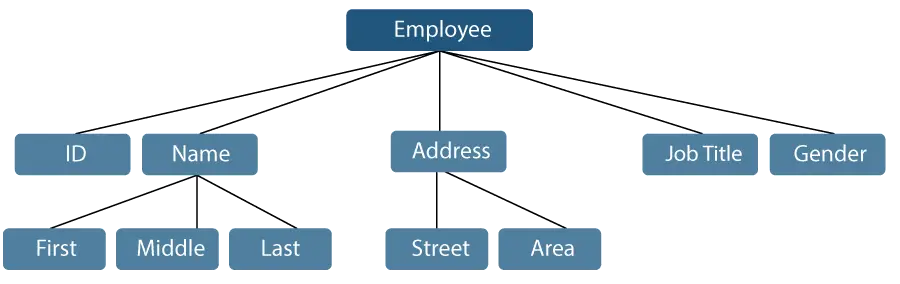
Obrázek 1: Reprezentace datových položek
Ve výše uvedeném příkladu jsou položky jako ID, Věk, Pohlaví, První, Prostřední, Poslední, Ulice, Lokalita atd. základní datové položky. Naproti tomu Název a Adresa jsou datové položky skupiny.
Co je datová struktura?
Datová struktura je obor informatiky. Studium struktury dat nám umožňuje porozumět organizaci dat a řízení toku dat za účelem zvýšení efektivity jakéhokoli procesu nebo programu. Struktura dat je zvláštní způsob ukládání a organizace dat v paměti počítače, takže tato data lze v případě potřeby snadno načíst a v budoucnu efektivně využít. Data lze spravovat různými způsoby, například logický nebo matematický model pro konkrétní organizaci dat je známý jako datová struktura.
Rozsah konkrétního datového modelu závisí na dvou faktorech:
- Nejprve musí být do struktury načten natolik, aby odrážel definitivní korelaci dat s objektem reálného světa.
- Zadruhé, tvorba by měla být tak přímočará, že se lze přizpůsobit tak, aby data zpracovávala efektivně, kdykoli je to nutné.
Některé příklady datových struktur jsou pole, propojené seznamy, zásobník, fronta, stromy atd. Datové struktury jsou široce používány téměř ve všech aspektech informatiky, tj. v designu kompilátorů, operačních systémech, grafice, umělé inteligenci a mnoha dalších.
Datové struktury jsou hlavní součástí mnoha algoritmů počítačové vědy, protože umožňují programátorům efektivně spravovat data. Hraje klíčovou roli při zlepšování výkonu programu nebo softwaru, protože hlavním cílem softwaru je ukládat a získávat uživatelská data co nejrychleji.
Algoritmus pro binární vyhledávání
Základní terminologie související s datovými strukturami
Datové struktury jsou stavebními kameny jakéhokoli softwaru nebo programu. Výběr vhodné datové struktury pro program je pro programátora extrémně náročný úkol.
Níže jsou uvedeny některé základní terminologie používané vždy, když se jedná o datové struktury:
| Atributy | ID | název | Rod | Pracovní pozice |
|---|---|---|---|---|
| Hodnoty | 1234 | Stacey M. Hillová | ženský | Vývojář softwaru |
Entity s podobnými atributy tvoří an Sada entit . Každý atribut množiny entit má rozsah hodnot, množinu všech možných hodnot, které by mohly být přiřazeny konkrétnímu atributu.
Termín „informace“ se někdy používá pro data s danými atributy smysluplných nebo zpracovaných dat.
Pochopení potřeby datových struktur
Vzhledem k tomu, že aplikace jsou stále složitější a množství dat se každým dnem zvyšuje, může to vést k problémům s vyhledáváním dat, rychlostí zpracování, zpracováním více požadavků a mnoha dalšími. Datové struktury podporují různé metody pro efektivní organizaci, správu a ukládání dat. Pomocí datových struktur můžeme snadno procházet datové položky. Datové struktury poskytují efektivitu, znovupoužitelnost a abstrakci.
Proč bychom se měli učit datové struktury?
- Datové struktury a algoritmy jsou dva klíčové aspekty informatiky.
- Datové struktury nám umožňují organizovat a ukládat data, zatímco algoritmy nám umožňují tato data smysluplně zpracovávat.
- Učení se datových struktur a algoritmů nám pomůže stát se lepšími programátory.
- Budeme schopni napsat kód, který bude efektivnější a spolehlivější.
- Budeme také schopni rychleji a efektivněji řešit problémy.
Pochopení cílů datových struktur
Datové struktury splňují dva doplňkové cíle:
Pochopení některých klíčových funkcí datových struktur
Některé z významných funkcí datových struktur jsou:
Klasifikace datových struktur
Datová struktura poskytuje strukturovanou sadu proměnných, které spolu navzájem souvisí různými způsoby. Tvoří základ programovacího nástroje, který označuje vztah mezi datovými prvky a umožňuje programátorům efektivně zpracovávat data.
Datové struktury můžeme rozdělit do dvou kategorií:
- Primitivní datová struktura
- Neprimitivní datová struktura
Následující obrázek ukazuje různé klasifikace datových struktur.

Obrázek 2: Klasifikace datových struktur
Primitivní datové struktury
- S těmito datovými strukturami lze manipulovat nebo je ovládat přímo instrukcemi na úrovni stroje.
- Základní datové typy jako Integer, Float, Character , a Boolean spadají pod primitivní datové struktury.
- Tyto datové typy se také nazývají Jednoduché datové typy , protože obsahují znaky, které nelze dále dělit
Neprimitivní datové struktury
- S těmito datovými strukturami nelze manipulovat nebo je ovládat přímo instrukcemi na úrovni stroje.
- Těžištěm těchto datových struktur je vytvoření sady datových prvků, které jsou buď homogenní (stejný datový typ) popř heterogenní (různé datové typy).
- Na základě struktury a uspořádání dat můžeme tyto datové struktury rozdělit do dvou podkategorií -
- Lineární datové struktury
- Nelineární datové struktury
Lineární datové struktury
Datová struktura, která zachovává lineární spojení mezi svými datovými prvky, se nazývá lineární datová struktura. Uspořádání dat je provedeno lineárně, kde každý prvek se skládá z následníků a předchůdců kromě prvního a posledního datového prvku. To však nemusí být nutně pravda v případě paměti, protože uspořádání nemusí být sekvenční.
Na základě alokace paměti se lineární datové struktury dále dělí na dva typy:
The Pole je nejlepším příkladem statické datové struktury, protože má pevnou velikost a její data lze později upravit.
Propojené seznamy, zásobníky , a Ocasy jsou běžné příklady dynamických datových struktur
Typy lineárních datových struktur
Níže je uveden seznam lineárních datových struktur, které obecně používáme:
1. Pole
An Pole je datová struktura používaná ke shromažďování více datových prvků stejného datového typu do jedné proměnné. Namísto ukládání více hodnot stejných datových typů do samostatných názvů proměnných bychom je mohli uložit všechny dohromady do jedné proměnné. Toto tvrzení neznamená, že budeme muset sjednotit všechny hodnoty stejného datového typu v libovolném programu do jednoho pole tohoto datového typu. Často však nastanou situace, kdy některé specifické proměnné stejného datového typu spolu navzájem souvisí způsobem vhodným pro pole.
Pole je seznam prvků, kde každý prvek má v seznamu jedinečné místo. Datové prvky pole sdílejí stejný název proměnné; každý však nese jiné indexové číslo nazývané dolní index. K libovolnému datovému prvku ze seznamu můžeme přistupovat pomocí jeho umístění v seznamu. Klíčovou vlastností polí, které je třeba pochopit, je tedy to, že data jsou uložena v souvislých paměťových místech, což uživatelům umožňuje procházet datovými prvky pole pomocí jejich příslušných indexů.
řetězec délky

Obrázek 3 Pole
Pole lze rozdělit do různých typů:
Některé aplikace Array:
- Můžeme uložit seznam datových prvků patřících ke stejnému datovému typu.
- Pole funguje jako pomocné úložiště pro další datové struktury.
- Pole také pomáhá ukládat datové prvky binárního stromu pevného počtu.
- Pole také funguje jako úložiště matic.
2. Propojené seznamy
A Spojový seznam je dalším příkladem lineární datové struktury používané k dynamickému ukládání kolekce datových prvků. Datové prvky v této datové struktuře jsou reprezentovány uzly, spojenými pomocí odkazů nebo ukazatelů. Každý uzel obsahuje dvě pole, informační pole se skládá ze skutečných dat a pole ukazatele se skládá z adresy následujících uzlů v seznamu. Ukazatel posledního uzlu propojeného seznamu se skládá z nulového ukazatele, protože neukazuje na nic. Na rozdíl od polí může uživatel dynamicky upravovat velikost propojeného seznamu podle požadavků.

Obrázek 4. Propojený seznam
Propojené seznamy lze rozdělit do různých typů:
Některé aplikace propojených seznamů:
- Propojené seznamy nám pomáhají implementovat zásobníky, fronty, binární stromy a grafy předem definované velikosti.
- Můžeme také implementovat funkci operačního systému pro dynamickou správu paměti.
- Propojené seznamy také umožňují polynomiální implementaci pro matematické operace.
- Můžeme použít Circular Linked List k implementaci operačních systémů nebo funkcí aplikací, které Round Robin provádění úkolů.
- Kruhový propojený seznam je také užitečný v prezentaci, kde se uživatel po zobrazení posledního snímku musí vrátit na první snímek.
- Dvojitě propojený seznam se používá k implementaci tlačítek vpřed a vzad v prohlížeči pro pohyb vpřed a vzad na otevřených stránkách webu.
3. Hromady
A Zásobník je lineární datová struktura, která následuje LIFO (Last In, First Out) princip, který umožňuje operace jako vkládání a mazání z jednoho konce zásobníku, tj. Top. Zásobníky lze implementovat pomocí souvislé paměti, pole a nesouvislé paměti, propojeného seznamu. Skutečnými příklady stacků jsou hromady knih, balíček karet, hromady peněz a mnoho dalších.

Obrázek 5. Příklad zásobníku ze skutečného života
Výše uvedený obrázek představuje skutečný příklad zásobníku, kde se operace provádějí pouze z jednoho konce, jako je vkládání a vyjímání nových knih z horní části zásobníku. To znamená, že vkládání a mazání v zásobníku lze provést pouze z horní části zásobníku. V daný okamžik máme přístup pouze k vrcholům zásobníku.
Primární operace v zásobníku jsou následující:
powershell menší nebo rovno

Obrázek 6. Zásobník
Některé aplikace stacků:
- Zásobník se používá jako dočasná struktura úložiště pro rekurzivní operace.
- Stack se také používá jako pomocná struktura úložiště pro volání funkcí, vnořené operace a odložené/odložené funkce.
- Volání funkcí můžeme spravovat pomocí Stacks.
- Zásobníky se také používají k vyhodnocení aritmetických výrazů v různých programovacích jazycích.
- Zásobníky jsou také užitečné při převodu infixových výrazů na postfixové výrazy.
- Zásobníky nám umožňují zkontrolovat syntaxi výrazu v programovacím prostředí.
- Můžeme spárovat závorky pomocí Stacks.
- Zásobníky lze použít k obrácení řetězce.
- Zásobníky jsou užitečné při řešení problémů založených na backtrackingu.
- Hromady můžeme použít v hloubkovém vyhledávání v grafu a procházení stromů.
- Zásobníky se také používají ve funkcích operačního systému.
- Zásobníky se také používají ve funkcích UNDO a REDO v úpravě.
4. Ocasy
A Fronta je lineární datová struktura podobná Stack s určitými omezeními na vkládání a mazání prvků. Vložení prvku do fronty se provádí na jednom konci a odstranění se provádí na druhém nebo opačném konci. Můžeme tedy dojít k závěru, že datová struktura Queue se řídí principem FIFO (First In, First Out) pro manipulaci s datovými prvky. Implementaci front lze provést pomocí polí, propojených seznamů nebo zásobníků. Některé příklady front ze skutečného života jsou fronta u pokladní přepážky, eskalátor, myčka aut a mnoho dalších.

Obrázek 7. Reálný příklad fronty
Obrázek nahoře je skutečná ilustrace přepážky vstupenek do kina, která nám může pomoci porozumět frontě, kde je vždy první obsloužený zákazník, který přijde jako první. Zákazník, který dorazí jako poslední, bude nepochybně obsluhován jako poslední. Oba konce fronty jsou otevřené a mohou provádět různé operace. Dalším příkladem je linka food courtu, kde je zákazník vložen ze zadní části, zatímco zákazník je odstraněn na přední straně po poskytnutí služby, o kterou požádal.
Níže jsou uvedeny primární operace fronty:
jak převést řetězec na int v java

Postavení 8. Fronta
Některé aplikace front:
- Fronty se obecně používají v operaci prohledávání šířky v Graphs.
- Fronty se také používají v operacích plánovače úloh operačních systémů, jako je fronta vyrovnávací paměti klávesnice k ukládání kláves stisknutých uživateli a fronta tiskové vyrovnávací paměti k ukládání dokumentů vytištěných tiskárnou.
- Fronty jsou zodpovědné za plánování CPU, plánování úloh a plánování disku.
- Prioritní fronty se používají při operacích stahování souborů v prohlížeči.
- Fronty se také používají k přenosu dat mezi periferními zařízeními a CPU.
- Fronty jsou také zodpovědné za zpracování přerušení generovaných uživatelskými aplikacemi pro CPU.
Nelineární datové struktury
Nelineární datové struktury jsou datové struktury, kde datové prvky nejsou uspořádány v sekvenčním pořadí. Zde vkládání a odstraňování dat není možné lineárním způsobem. Mezi jednotlivými datovými položkami existuje hierarchický vztah.
Typy nelineárních datových struktur
Níže je uveden seznam nelineárních datových struktur, které obecně používáme:
1. Stromy
Strom je nelineární datová struktura a hierarchie obsahující kolekci uzlů tak, že každý uzel stromu ukládá hodnotu a seznam odkazů na jiné uzly („děti“).
Stromová datová struktura je specializovaná metoda pro uspořádání a shromažďování dat v počítači, aby byla efektivněji využívána. Obsahuje centrální uzel, strukturální uzly a dílčí uzly spojené hranami. Můžeme také říci, že stromová datová struktura se skládá ze spojených kořenů, větví a listů.

Obrázek 9. Strom
Stromy lze rozdělit do několika typů:
Některé aplikace stromů:
- Stromy implementují hierarchické struktury v počítačových systémech, jako jsou adresáře a systémy souborů.
- Stromy se také používají k implementaci navigační struktury webu.
- Můžeme generovat kód jako Huffmanův kód pomocí Stromů.
- Stromy jsou také užitečné při rozhodování v herních aplikacích.
- Stromy jsou zodpovědné za implementaci prioritních front pro funkce plánování OS založené na prioritách.
- Stromy jsou také zodpovědné za analýzu výrazů a příkazů v kompilátorech různých programovacích jazyků.
- Stromy můžeme použít k ukládání datových klíčů pro indexování pro Database Management System (DBMS).
- Spanning Trees nám umožňuje směrovat rozhodnutí v počítačových a komunikačních sítích.
- Stromy se také používají v algoritmu hledání cesty implementovaném v aplikacích umělé inteligence (AI), robotiky a videoher.
2. Grafy
Graf je dalším příkladem nelineární datové struktury obsahující konečný počet uzlů nebo vrcholů a hran, které je spojují. Grafy se používají k řešení problémů reálného světa, ve kterém označují problémovou oblast jako síť, jako jsou sociální sítě, obvodové sítě a telefonní sítě. Například uzly nebo vrcholy grafu mohou představovat jednoho uživatele v telefonní síti, zatímco hrany představují spojení mezi nimi prostřednictvím telefonu.
Datová struktura Graph G je považována za matematickou strukturu složenou ze sady vrcholů V a sady hran E, jak je uvedeno níže:
G = (V,E)

Obrázek 10. Graf
Výše uvedený obrázek představuje graf se sedmi vrcholy A, B, C, D, E, F, G a deseti hranami [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] a [E, G].
V závislosti na poloze vrcholů a hran lze grafy rozdělit do různých typů:
v.další java
Některé aplikace grafů:
- Grafy nám pomáhají reprezentovat trasy a sítě v dopravních, cestovních a komunikačních aplikacích.
- Pro zobrazení tras v GPS se používají grafy.
- Grafy nám také pomáhají reprezentovat propojení v sociálních sítích a dalších síťových aplikacích.
- Grafy se používají v mapových aplikacích.
- Grafy jsou zodpovědné za reprezentaci uživatelských preferencí v aplikacích elektronického obchodování.
- Grafy se také používají v inženýrských sítích za účelem identifikace problémů, s nimiž se místní nebo obecní podniky setkávají.
- Grafy také pomáhají řídit využití a dostupnost zdrojů v organizaci.
- Grafy se také používají k vytváření map odkazů na dokumenty na webových stránkách, aby bylo možné zobrazit propojení mezi stránkami prostřednictvím hypertextových odkazů.
- Grafy se také používají v robotických pohybech a neuronových sítích.
Základní operace s datovými strukturami
V následující části probereme různé typy operací, které můžeme provádět při manipulaci s daty v každé datové struktuře:
- Doba kompilace
- Doba běhu
Například, malloc() Funkce se používá v jazyce C k vytvoření datové struktury.
Pochopení abstraktního datového typu
Podle Národní institut pro standardy a technologie (NIST) , datová struktura je uspořádání informací, obecně v paměti, pro lepší účinnost algoritmu. Datové struktury zahrnují propojené seznamy, zásobníky, fronty, stromy a slovníky. Mohou to být také teoretické entity, jako je jméno a adresa osoby.
Z výše uvedené definice můžeme usoudit, že operace v datové struktuře zahrnují:
- Vysoká úroveň abstrakcí, jako je přidání nebo odstranění položky ze seznamu.
- Vyhledávání a řazení položky v seznamu.
- Přístup k položce s nejvyšší prioritou v seznamu.
Kdykoli datová struktura provádí takové operace, je známá jako an Abstraktní datový typ (ADT) .
Můžeme jej definovat jako soubor datových prvků spolu s operacemi s daty. Termín „abstrakt“ odkazuje na skutečnost, že data a základní operace na nich definované jsou studovány nezávisle na jejich implementaci. Zahrnuje to, co můžeme s daty dělat, nikoli jak to můžeme udělat.
Implementace ADI obsahuje strukturu úložiště za účelem uložení datových prvků a algoritmů pro základní operace. Všechny datové struktury, jako je pole, propojený seznam, fronta, zásobník atd., jsou příklady ADT.
Pochopení výhod používání ADT
V reálném světě se programy vyvíjejí jako důsledek nových omezení nebo požadavků, takže úprava programu obecně vyžaduje změnu jedné nebo více datových struktur. Předpokládejme například, že chceme do záznamu zaměstnance vložit nové pole, abychom měli přehled o dalších podrobnostech o každém zaměstnanci. V takovém případě můžeme zvýšit efektivitu programu tím, že nahradíme Array strukturou Linked. V takové situaci je přepisování každé procedury, která využívá upravenou strukturu, nevhodné. Lepší alternativou je tedy oddělení datové struktury od jejích implementačních informací. Toto je princip použití abstraktních datových typů (ADT).
Některé aplikace datových struktur
Níže jsou uvedeny některé aplikace datových struktur:
- Datové struktury pomáhají při organizaci dat v paměti počítače.
- Datové struktury také pomáhají při reprezentaci informací v databázích.
- Datové struktury umožňují implementaci algoritmů pro vyhledávání v datech (například vyhledávač).
- Můžeme použít datové struktury k implementaci algoritmů pro manipulaci s daty (například textové procesory).
- Můžeme také implementovat algoritmy pro analýzu dat pomocí datových struktur (například data mining).
- Datové struktury podporují algoritmy pro generování dat (například generátor náhodných čísel).
- Datové struktury také podporují algoritmy pro kompresi a dekomprimaci dat (například utilita zip).
- Můžeme také použít datové struktury k implementaci algoritmů pro šifrování a dešifrování dat (například bezpečnostní systém).
- S pomocí Data Structures můžeme vytvořit software, který dokáže spravovat soubory a adresáře (například správce souborů).
- Můžeme také vyvinout software, který dokáže vykreslovat grafiku pomocí datových struktur. (Například webový prohlížeč nebo 3D renderovací software).
Kromě těch, jak již bylo zmíněno, existuje mnoho dalších aplikací datových struktur, které nám mohou pomoci vytvořit jakýkoli požadovaný software.