Neinformované vyhledávání je třída obecných vyhledávacích algoritmů, které fungují způsobem hrubé síly. Neinformované vyhledávací algoritmy nemají další informace o stavu nebo prohledávacím prostoru kromě toho, jak procházet stromem, takže se také nazývá slepé vyhledávání.
Níže jsou uvedeny různé typy neinformovaných vyhledávacích algoritmů:
1. Hledání do šířky:
- Hledání do šířky je nejběžnější vyhledávací strategií pro procházení stromu nebo grafu. Tento algoritmus prohledává ve stromu nebo grafu po šířce, proto se nazývá prohledávání do šířky.
- Algoritmus BFS začne hledat od kořenového uzlu stromu a rozšíří všechny následnické uzel na aktuální úrovni, než se přesune na uzly další úrovně.
- Algoritmus prohledávání do šířky je příkladem algoritmu prohledávání obecného grafu.
- Prohledávání do šířky implementované pomocí datové struktury fronty FIFO.
výhody:
- BFS poskytne řešení, pokud nějaké řešení existuje.
- Pokud pro daný problém existuje více než jedno řešení, pak BFS poskytne minimální řešení, které vyžaduje nejmenší počet kroků.
Nevýhody:
- Vyžaduje spoustu paměti, protože každá úroveň stromu musí být uložena do paměti, aby se rozšířila další úroveň.
- BFS potřebuje spoustu času, pokud je řešení daleko od kořenového uzlu.
Příklad:
V níže uvedené stromové struktuře jsme ukázali procházení stromu pomocí algoritmu BFS z kořenového uzlu S do cílového uzlu K. Algoritmus hledání BFS prochází ve vrstvách, takže bude sledovat cestu, která je znázorněna tečkovanou šipkou a projetá cesta bude:
S---> A--->B---->C--->D---->G--->H--->E---->F---->I---->K
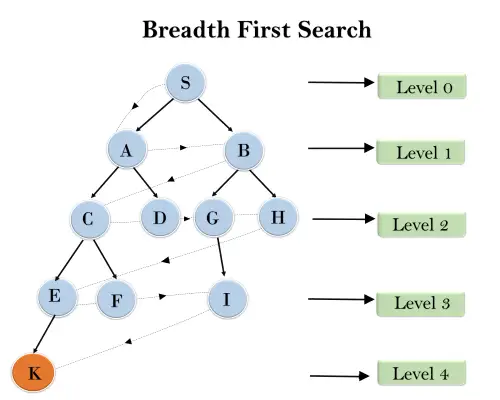
Časová náročnost: Časovou složitost algoritmu BFS lze získat počtem uzlů procházejících v BFS až do nejmělčího uzlu. Kde d= hloubka nejmělčího řešení a b je uzel v každém stavu.
T(b) = 1+b2+b3+.......+ bd= O (bd)
Prostorová složitost: Prostorová složitost algoritmu BFS je dána velikostí paměti hranice, která je O(bd).
Úplnost: BFS je kompletní, což znamená, že pokud je nejmělčí cílový uzel v nějaké konečné hloubce, pak BFS najde řešení.
Optimalita: BFS je optimální, pokud jsou náklady na cestu neklesající funkcí hloubky uzlu.
2. Hloubkové vyhledávání
- Hloubkové vyhledávání je rekurzivní algoritmus pro procházení stromové nebo grafové datové struktury.
- Říká se mu hloubkové prohledávání, protože začíná od kořenového uzlu a sleduje každou cestu k uzlu s největší hloubkou, než se přesune na další cestu.
- DFS používá pro svou implementaci datovou strukturu zásobníku.
- Proces algoritmu DFS je podobný algoritmu BFS.
Poznámka: Backtracking je technika algoritmu pro nalezení všech možných řešení pomocí rekurze.
Výhoda:
- DFS vyžaduje velmi méně paměti, protože potřebuje pouze uložit zásobník uzlů na cestě od kořenového uzlu k aktuálnímu uzlu.
- Dosažení cílového uzlu trvá méně času než algoritmu BFS (pokud prochází správnou cestou).
Nevýhoda:
- Existuje možnost, že mnoho států se bude opakovat a neexistuje žádná záruka, že se najde řešení.
- Algoritmus DFS se zaměřuje na hluboké vyhledávání a někdy může přejít do nekonečné smyčky.
Příklad:
V níže uvedeném vyhledávacím stromě jsme ukázali tok vyhledávání nejprve do hloubky a bude se řídit následujícím pořadím:
Kořenový uzel--->Levý uzel ----> pravý uzel.
Začne hledat od kořenového uzlu S a projde A, pak B, pak D a E, po projití E se vrátí zpět ke stromu, protože E nemá žádného dalšího nástupce a cílový uzel stále nebyl nalezen. Po zpětném sledování projde uzel C a poté G a zde skončí, když našel cílový uzel.

Úplnost: Algoritmus hledání DFS je dokončen v konečném stavovém prostoru, protože rozšíří každý uzel v omezeném vyhledávacím stromu.
Časová náročnost: Časová složitost DFS bude ekvivalentní uzlu, kterým algoritmus prochází. Je dáno:
T(n)= 1+ n2+ n3+.........+ nm=O(nm)
Kde, m = maximální hloubka libovolného uzlu a může být mnohem větší než d (nejmělčí hloubka řešení)
Prostorová složitost: Algoritmus DFS potřebuje ukládat pouze jednu cestu z kořenového uzlu, takže prostorová složitost DFS je ekvivalentní velikosti množiny okrajů, což je O .
Optimální: Algoritmus vyhledávání DFS není optimální, protože může generovat velký počet kroků nebo vysoké náklady na dosažení cílového uzlu.
3. Algoritmus hledání s omezenou hloubkou:
Algoritmus hledání s omezenou hloubkou je podobný prohledávání do hloubky s předem stanoveným limitem. Hloubkově omezené vyhledávání může vyřešit nevýhodu nekonečné cesty v hloubkovém vyhledávání. V tomto algoritmu bude uzel na hloubkovém limitu zacházet tak, že nemá žádné následnické uzly.
Hloubkově omezené hledání lze ukončit se dvěma podmínkami selhání:
- Standardní hodnota selhání: Znamená, že problém nemá žádné řešení.
- Hodnota selhání cutoff: Nedefinuje žádné řešení problému v rámci daného limitu hloubky.
výhody:
Hledání s omezenou hloubkou je efektivní z hlediska paměti.
Nevýhody:
- Hloubkově omezené hledání má také nevýhodu neúplnosti.
- Nemusí být optimální, pokud má problém více než jedno řešení.
Příklad:

Úplnost: Algoritmus vyhledávání DLS je dokončen, pokud je řešení nad limitem hloubky.
Časová náročnost: Časová složitost algoritmu DLS je O(bℓ) .
Prostorová složitost: Prostorová složitost algoritmu DLS je O (b�ℓ) .
Optimální: Hloubkově omezené vyhledávání lze považovat za zvláštní případ DFS a také není optimální, i když ℓ>d.
4. Algoritmus hledání s jednotnou cenou:
Uniform-cost search je vyhledávací algoritmus používaný k procházení váženým stromem nebo grafem. Tento algoritmus přichází do hry, když je pro každou hranu k dispozici jiná cena. Primárním cílem hledání jednotných nákladů je najít cestu k cílovému uzlu, který má nejnižší kumulativní náklady. Hledání podle jednotných nákladů rozšiřuje uzly podle jejich nákladů na cestu z kořenového uzlu. Lze jej použít k řešení libovolného grafu/stromu, kde je požadována optimální cena. Prioritní fronta implementuje vyhledávací algoritmus s jednotnými náklady. Maximální prioritu dává nejnižším kumulativním nákladům. Jednotné hledání nákladů je ekvivalentní algoritmu BFS, pokud jsou náklady na cestu všech hran stejné.
výhody:
- Jednotné hledání nákladů je optimální, protože v každém stavu je zvolena cesta s nejnižšími náklady.
Nevýhody:
- Nezáleží na počtu kroků při hledání a zajímá se pouze o náklady na cestu. Díky tomu může tento algoritmus uvíznout v nekonečné smyčce.
Příklad:

Úplnost:
Hledání jednotných nákladů je dokončeno, například pokud existuje řešení, UCS ho najde.
Časová náročnost:
Nechat C* jsou náklady na optimální řešení , a E je každý krok k přiblížení se k cílovému uzlu. Potom je počet kroků = C*/ε+1. Zde jsme vzali +1, protože začínáme od stavu 0 a končíme u C*/ε.
Nejhorším případem časové složitosti je tedy hledání jednotných nákladů O(b1 + [C*/e])/ .
Prostorová složitost:
Stejná logika platí pro prostorovou složitost, takže nejhorší případ prostorové složitosti hledání jednotných nákladů je O(b1 + [C*/e]) .
Optimální:
Hledání jednotných nákladů je vždy optimální, protože vybírá pouze cestu s nejnižšími náklady.
5. Iterativní prohlubování hloubka-první vyhledávání:
Algoritmus iterativního prohlubování je kombinací algoritmů DFS a BFS. Tento vyhledávací algoritmus zjišťuje nejlepší limit hloubky a dělá to postupným zvyšováním limitu, dokud není nalezen cíl.
Tento algoritmus provádí hloubkové prohledávání až do určitého „hloubkového limitu“ a po každé iteraci neustále zvyšuje hloubkový limit, dokud není nalezen cílový uzel.
Tento vyhledávací algoritmus kombinuje výhody rychlého vyhledávání do šířky a paměťové efektivity vyhledávání napřed do hloubky.
Iterativní vyhledávací algoritmus je užitečné neinformované vyhledávání, když je prohledávací prostor velký a hloubka cílového uzlu není známa.
výhody:
- Kombinuje výhody vyhledávacího algoritmu BFS a DFS, pokud jde o rychlé vyhledávání a efektivitu paměti.
Nevýhody:
- Hlavní nevýhodou IDDFS je, že opakuje veškerou práci předchozí fáze.
Příklad:
Následující stromová struktura ukazuje iterativní prohlubování prohledávání do hloubky. Algoritmus IDDFS provádí různé iterace, dokud nenajde cílový uzel. Iterace provedená algoritmem je dána jako:

1. iterace -----> A
2. iterace ----> A, B, C
3. iterace ------> A, B, D, E, C, F, G
4. iterace------>A, B, D, H, I, E, C, F, K, G
Ve čtvrté iteraci algoritmus najde cílový uzel.
Úplnost:
Tento algoritmus je kompletní, pokud je faktor větvení konečný.
Časová náročnost:
Předpokládejme, že b je faktor větvení a hloubka je d, pak je nejhorší případ časová složitost O(bd) .
Prostorová složitost:
Prostorová složitost IDDFS bude O(bd) .
Optimální:
Algoritmus IDDFS je optimální, pokud je cena cesty neklesající funkcí hloubky uzlu.
6. Obousměrný vyhledávací algoritmus:
Obousměrný vyhledávací algoritmus spouští dvě současná vyhledávání, jedno z počátečního stavu zvaného jako dopředné vyhledávání a druhé z cílového uzlu zvaného jako zpětné vyhledávání, aby našel cílový uzel. Obousměrné vyhledávání nahrazuje jeden jediný vyhledávací graf dvěma malými podgrafy, ve kterých jeden začíná vyhledávání od počátečního vrcholu a druhý začíná od cílového vrcholu. Vyhledávání se zastaví, když se tyto dva grafy protnou.
Obousměrné vyhledávání může využívat vyhledávací techniky jako BFS, DFS, DLS atd.
výhody:
- Obousměrné vyhledávání je rychlé.
- Obousměrné vyhledávání vyžaduje méně paměti
Nevýhody:
- Implementace obousměrného vyhledávacího stromu je obtížná.
Příklad:
V níže uvedeném vyhledávacím stromě je použit obousměrný vyhledávací algoritmus. Tento algoritmus rozděluje jeden graf/strom na dva podgrafy. Začíná procházet z uzlu 1 směrem dopředu a začíná z cílového uzlu 16 směrem dozadu.
Algoritmus končí v uzlu 9, kde se setkají dvě hledání.
jak spustit skript v linuxu

Úplnost: Obousměrné vyhledávání je dokončeno, pokud použijeme BFS v obou vyhledáváních.
Časová náročnost: Časová náročnost obousměrného vyhledávání pomocí BFS je O(bd) .
Prostorová složitost: Prostorová složitost obousměrného vyhledávání je O(bd) .
Optimální: Obousměrné vyhledávání je optimální.