Následují podmíněné výrazy v SQL
- Výraz CASE: Umožňuje používat příkazy IF-THEN-ELSE, aniž byste museli vyvolávat procedury.
-
Input: SELECT GREATEST('XYZ', 'xyz') from dual;>Output: GREATEST('XYZ', 'xyz') xyz>Vysvětlení: Hodnota ASCII malých abeced je větší.
-
Input: SELECT GREATEST('XYZ', null, 'xyz') from dual; Output: GREATEST('XYZ', null, 'xyz') ->Vysvětlení: Protože je zde přítomno null, bude null zobrazeno jako výstup (jak je uvedeno v popisu výše).
-
Input: SELECT IFNULL(1,0) FROM dual;>
Output: - 1>
Vysvětlení : Protože žádný výraz není null.
-
Input: SELECT IFNULL(NULL,10) FROM dual; Output: -- 10>
Vysvětlení: Protože výraz expr1 je nulový, zobrazí se výraz expr2.
význam xdxd
-
strong>Vstup: SELECT LEAST('XYZ', 'xyz') z dual; Výstup: LEAST('XYZ', 'xyz') XYZ>Vysvětlení: ASCII hodnota velkých abeced je menší.
-
Input: SELECT LEAST('XYZ', null, 'xyz') from dual; Output: LEAST('XYZ', null, 'xyz') ->Vysvětlení: Protože je tedy přítomno null, bude null zobrazeno jako výstup (jak je uvedeno v popisu výše).
V jednoduchém výrazu CASE vyhledá SQL první pár WHEN……THEN, pro který se výraz rovná porovnávacímu_výrazu a vrátí návratový_výraz. Pokud výše uvedená podmínka není splněna, existuje klauzule ELSE, SQL vrátí else_expr. V opačném případě vrátí hodnotu NULL.
Nemůžeme zadat doslovnou hodnotu null pro return_expr a else_expr. Všechny výrazy (výraz, porovnávací_výraz, návratový_výraz) musí být stejného datového typu.
Syntax:
concat java řetězec
CASE expr WHEN comparison_expr1 THEN return_expr1 [ WHEN comparison_expr2 THEN return_expr2 . . . WHEN comparison_exprn THEN return_exprn ELSE else_expr] END>
Příklad:
Input : SELECT first_name, department_id, salary, CASE department_id WHEN 50 THEN 1.5*salary WHEN 12 THEN 2.0*salary ELSE salary END 'REVISED SALARY' FROM Employee;>
Výstup :
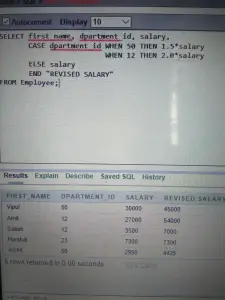
Vysvětlení : Ve výše uvedených příkazech SQL je dekódována hodnota department_id. Pokud je to 50, pak se plat vyplácí 1,5krát, pokud je to 12, pak se plat vyplácí 2krát, jinak se plat nemění. Funkce DECODE: Usnadňuje podmíněné dotazy provedením práce příkazu CASE nebo IF-THEN-ELSE.
Funkce DECODE dekóduje výraz podobným způsobem jako logika IF-THEN-ELSE používaná v různých jazycích. Funkce DECODE dekóduje výraz po jeho porovnání s každou hledanou hodnotou. Pokud je výraz stejný jako hledání, vrátí se výsledek.
Pokud je výchozí hodnota vynechána, je vrácena hodnota null, kde hledaná hodnota neodpovídá žádné z hodnot výsledku.
Syntax:
DECODE (col/expression, search1, result1 [, search2, result2,........,] [, default])>
Input : SELECT first_name, department_id, salary, DECODE(department_id, 50, 1.5*salary, 12, 2.0*salary, salary) 'REVISED SALARY' FROM Employee;>
Výstup :

Vysvětlení: Ve výše uvedených příkazech SQL je testována hodnota department_id. Pokud je to 50, pak se plat vyplácí 1,5krát, pokud je to 12, pak se plat vyplácí 2krát, jinak se plat nemění.
POZNÁMKA: Stejně jako výrazy CASE, COALESCE také nevyhodnotí argumenty napravo od prvního nalezeného argumentu bez hodnoty null.
Syntax:
COALESCE( value [, ......] )>
Input: SELECT COALESCE(last_name, '- NA -') from Employee;>
Výstup:
Vysvětlení: - NA - zobrazí se na místě, kde je příjmení null, jinak se zobrazí příslušná příjmení. GREATEST: Vrátí největší hodnotu ze seznamu libovolného počtu výrazů. Při porovnávání se rozlišují velká a malá písmena. Pokud datové typy všech výrazů v seznamu nejsou stejné, ostatní všechny výrazy se pro porovnání převedou na datový typ prvního výrazu a pokud tento převod není možný, SQL vyvolá chybu.
POZNÁMKA: Vrátí hodnotu null, pokud je některý výraz v seznamu prázdný.
Syntax:
GREATEST( expr1, expr2 [, .....] )>
Syntax:
'kruskalův algoritmus'
IFNULL( expr1, expr2 )>
POZNÁMKA: Stejně jako výrazy CASE a COALESCE, IN také nevyhodnotí argumenty napravo od prvního nalezeného nenulového argumentu.
Syntax:
WHERE column IN ( x1, x2, x3 [,......] )>
Input: SELECT * from Employee WHERE department_id IN(50, 12);>
Výstup:
Vysvětlení: Všechny údaje o zaměstnancích se zobrazují s ID oddělení 50 nebo 12.
LEAST: Vrátí nejmenší hodnotu ze seznamu libovolného počtu výrazů. Při porovnávání se rozlišují velká a malá písmena. Pokud datové typy všech výrazů v seznamu nejsou stejné, ostatní všechny výrazy se pro porovnání převedou na datový typ prvního výrazu a pokud tento převod není možný, SQL vyvolá chybu.POZNÁMKA: Vrátí hodnotu null, pokud má jakýkoli výraz v seznamu hodnotu null.
Syntax:
LEAST( expr1, expr2 [, ......] )>
Syntax:
NULLIF( value1, value2 )>
Příklad:
Input: SELECT NULLIF(9995463931, contact_num) from Employee;>
Výstup:

nový řádek python
Vysvětlení: U zaměstnance, jehož číslo se shoduje s daným číslem, se zobrazí NULL. Pro zbytek hodnoty Zaměstnanci je vrácena hodnota1.