V reálném světě strojové učení aplikace, je běžné, že má mnoho relevantních funkcí, ale pouze část z nich může být pozorovatelná. Při práci s proměnnými, které jsou někdy pozorovatelné a někdy ne, je skutečně možné využít případy, kdy je tato proměnná viditelná nebo pozorovaná, k učení a předpovědi pro případy, kdy není pozorovatelná. Tento přístup se často nazývá zpracování chybějících dat. Pomocí dostupných instancí, kde je proměnná pozorovatelná, se algoritmy strojového učení mohou naučit vzory a vztahy z pozorovaných dat. Tyto naučené vzorce pak lze použít k predikci hodnot proměnné v případech, kdy chybí nebo není pozorovatelná.
Algoritmus očekávání-maximalizace lze použít k řešení situací, kdy jsou proměnné částečně pozorovatelné. Když jsou určité proměnné pozorovatelné, můžeme tyto instance použít k učení a odhadu jejich hodnot. Potom můžeme předpovídat hodnoty těchto proměnných v případech, kdy to není pozorovatelné.
Algoritmus EM byl navržen a pojmenován v klíčovém článku publikovaném v roce 1977 Arthurem Dempsterem, Nan Lairdem a Donaldem Rubinem. Jejich práce formalizovala algoritmus a prokázala jeho užitečnost ve statistickém modelování a odhadech.
Algoritmus EM je použitelný pro latentní proměnné, což jsou proměnné, které nejsou přímo pozorovatelné, ale jsou odvozeny z hodnot jiných pozorovaných proměnných. Využitím známé obecné formy rozdělení pravděpodobnosti řídící tyto latentní proměnné může EM algoritmus předpovídat jejich hodnoty.
Algoritmus EM slouží jako základ pro mnoho neřízených shlukovacích algoritmů v oblasti strojového učení. Poskytuje rámec pro nalezení lokálních parametrů maximální pravděpodobnosti statistického modelu a odvození latentních proměnných v případech, kdy data chybí nebo jsou neúplná.
Algoritmus očekávání-maximalizace (EM).
Algoritmus Expectation-Maximization (EM) je iterativní optimalizační metoda, která kombinuje různé nekontrolované strojové učení algoritmy k nalezení maximální pravděpodobnosti nebo maximálních zadních odhadů parametrů ve statistických modelech, které zahrnují nepozorované latentní proměnné. Algoritmus EM se běžně používá pro modely latentních proměnných a dokáže zpracovat chybějící data. Skládá se z kroku odhadu (E-krok) a kroku maximalizace (M-krok), které tvoří iterativní proces pro zlepšení přizpůsobení modelu.
- V kroku E algoritmus vypočítává latentní proměnné, tj. očekávání logaritmické pravděpodobnosti pomocí aktuálních odhadů parametrů.
- V kroku M algoritmus určuje parametry, které maximalizují očekávanou logaritmickou pravděpodobnost získanou v kroku E, a odpovídající parametry modelu jsou aktualizovány na základě odhadovaných latentních proměnných.

Očekávání-Maximalizace v EM algoritmu
Iterativním opakováním těchto kroků se EM algoritmus snaží maximalizovat pravděpodobnost pozorovaných dat. Běžně se používá pro výukové úlohy bez dozoru, jako je shlukování, kde se odvozují latentní proměnné a má aplikace v různých oblastech, včetně strojového učení, počítačového vidění a zpracování přirozeného jazyka.
Klíčové pojmy v algoritmu Expectation-Maximization (EM).
Některé z nejčastěji používaných klíčových termínů v algoritmu Expectation-Maximization (EM) jsou následující:
- Latentní proměnné: Latentní proměnné jsou nepozorované proměnné ve statistických modelech, které lze odvodit pouze nepřímo prostřednictvím jejich účinků na pozorovatelné proměnné. Nemohou být přímo měřeny, ale lze je detekovat jejich dopadem na pozorovatelné proměnné. Pravděpodobnost: Je to pravděpodobnost pozorování daných dat daná parametry modelu. V EM algoritmu je cílem najít parametry, které maximalizují pravděpodobnost. Log-Likelihood: Je to logaritmus věrohodnostní funkce, která měří dobrou shodu mezi pozorovanými daty a modelem. EM algoritmus se snaží maximalizovat logaritmickou pravděpodobnost. Maximální pravděpodobnostní odhad (MLE): MLE je metoda pro odhad parametrů statistického modelu nalezením hodnot parametrů, které maximalizují pravděpodobnostní funkci, která měří, jak dobře model vysvětluje pozorovaná data. Posteriorní pravděpodobnost: V kontextu Bayesovské inference může být EM algoritmus rozšířen tak, aby odhadoval maximum a posteriori (MAP) odhadů, kde se zadní pravděpodobnost parametrů vypočítává na základě předchozí distribuce a pravděpodobnostní funkce. Očekávaný (E) krok: E-krok EM algoritmu vypočítává očekávanou hodnotu nebo pozdější pravděpodobnost latentních proměnných na základě pozorovaných dat a aktuálních odhadů parametrů. Zahrnuje výpočet pravděpodobností každé latentní proměnné pro každý datový bod. Maximalizační (M) krok: M-krok EM algoritmu aktualizuje odhady parametrů maximalizací očekávané logaritmické pravděpodobnosti získané z E-kroku. Zahrnuje nalezení hodnot parametrů, které optimalizují věrohodnostní funkci, obvykle pomocí numerických optimalizačních metod. Konvergence: Konvergence se týká stavu, kdy EM algoritmus dosáhl stabilního řešení. Obvykle se určuje kontrolou, zda změna logaritmické pravděpodobnosti nebo odhadů parametrů nespadá pod předem definovaný práh.
Jak funguje algoritmus Expectation-Maximization (EM):
Podstatou algoritmu Expectation-Maximization je použít dostupná pozorovaná data datové sady k odhadu chybějících dat a poté tato data použít k aktualizaci hodnot parametrů. Pojďme podrobně pochopit EM algoritmus.
Vývojový diagram EM algoritmu
- Inicializace:
- Nejprve je uvažován soubor počátečních hodnot parametrů. Soubor neúplných pozorovaných dat je předán systému s předpokladem, že pozorovaná data pocházejí z konkrétního modelu.
- Vypočítejte zadní pravděpodobnost nebo odpovědnost každé latentní proměnné na základě pozorovaných dat a aktuálních odhadů parametrů.
- Odhadněte chybějící nebo neúplné hodnoty dat pomocí aktuálních odhadů parametrů.
- Vypočítejte logaritmickou pravděpodobnost pozorovaných dat na základě aktuálních odhadů parametrů a odhadovaných chybějících dat.
- Aktualizujte parametry modelu maximalizací očekávané pravděpodobnosti úplného záznamu dat získané z E-kroku.
- To obvykle zahrnuje řešení optimalizačních problémů k nalezení hodnot parametrů, které maximalizují pravděpodobnost logování.
- Konkrétní použitá optimalizační technika závisí na povaze problému a použitém modelu.
- Zkontrolujte konvergenci porovnáním změny pravděpodobnosti logaritmu nebo hodnot parametrů mezi iteracemi.
- Pokud je změna pod předem definovanou prahovou hodnotou, zastavte se a zvažte, zda je algoritmus konvergovaný.
- V opačném případě se vraťte ke kroku E a opakujte proces, dokud nedosáhnete konvergence.
Algoritmus očekávání-maximalizace Krok za krokem implementace
Importujte potřebné knihovny
Python3
zobrazit skryté aplikace
import> numpy as np> import> matplotlib.pyplot as plt> from> scipy.stats>import> norm> |
>
>
Vygenerujte datovou sadu se dvěma gaussovskými komponentami
Python3
# Generate a dataset with two Gaussian components> mu1, sigma1>=> 2>,>1> mu2, sigma2>=> ->1>,>0.8> X1>=> np.random.normal(mu1, sigma1, size>=>200>)> X2>=> np.random.normal(mu2, sigma2, size>=>600>)> X>=> np.concatenate([X1, X2])> # Plot the density estimation using seaborn> sns.kdeplot(X)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.show()> |
markdown obrázky
>
>
Výstup :
Graf hustoty
Inicializovat parametry
Python3
# Initialize parameters> mu1_hat, sigma1_hat>=> np.mean(X1), np.std(X1)> mu2_hat, sigma2_hat>=> np.mean(X2), np.std(X2)> pi1_hat, pi2_hat>=> len>(X1)>/> len>(X),>len>(X2)>/> len>(X)> |
>
>
Proveďte EM algoritmus
- Iteruje pro zadaný počet epoch (v tomto případě 20).
- V každé epoše E-krok vypočítá odpovědnosti (hodnoty gama) vyhodnocením Gaussových hustot pravděpodobnosti pro každou složku a jejich vážením odpovídajícími proporcemi.
- M-krok aktualizuje parametry výpočtem váženého průměru a standardní odchylky pro každou složku
Python3
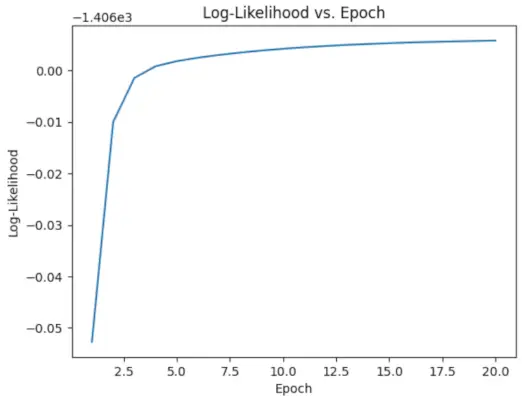
# Perform EM algorithm for 20 epochs> num_epochs>=> 20> log_likelihoods>=> []> for> epoch>in> range>(num_epochs):> ># E-step: Compute responsibilities> >gamma1>=> pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >gamma2>=> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)> >total>=> gamma1>+> gamma2> >gamma1>/>=> total> >gamma2>/>=> total> > ># M-step: Update parameters> >mu1_hat>=> np.>sum>(gamma1>*> X)>/> np.>sum>(gamma1)> >mu2_hat>=> np.>sum>(gamma2>*> X)>/> np.>sum>(gamma2)> >sigma1_hat>=> np.sqrt(np.>sum>(gamma1>*> (X>-> mu1_hat)>*>*>2>)>/> np.>sum>(gamma1))> >sigma2_hat>=> np.sqrt(np.>sum>(gamma2>*> (X>-> mu2_hat)>*>*>2>)>/> np.>sum>(gamma2))> >pi1_hat>=> np.mean(gamma1)> >pi2_hat>=> np.mean(gamma2)> > ># Compute log-likelihood> >log_likelihood>=> np.>sum>(np.log(pi1_hat>*> norm.pdf(X, mu1_hat, sigma1_hat)> >+> pi2_hat>*> norm.pdf(X, mu2_hat, sigma2_hat)))> >log_likelihoods.append(log_likelihood)> # Plot log-likelihood values over epochs> plt.plot(>range>(>1>, num_epochs>+>1>), log_likelihoods)> plt.xlabel(>'Epoch'>)> plt.ylabel(>'Log-Likelihood'>)> plt.title(>'Log-Likelihood vs. Epoch'>)> plt.show()> |
>
>
vyvolání zpracování výjimek v jazyce Java
Výstup :
Epocha vs Log-pravděpodobnost
Vyneste konečnou odhadovanou hustotu
Python3
# Plot the final estimated density> X_sorted>=> np.sort(X)> density_estimation>=> pi1_hat>*>norm.pdf(X_sorted,> >mu1_hat,> >sigma1_hat)>+> pi2_hat>*> norm.pdf(X_sorted,> >mu2_hat,> >sigma2_hat)> plt.plot(X_sorted, gaussian_kde(X_sorted)(X_sorted), color>=>'green'>, linewidth>=>2>)> plt.plot(X_sorted, density_estimation, color>=>'red'>, linewidth>=>2>)> plt.xlabel(>'X'>)> plt.ylabel(>'Density'>)> plt.title(>'Density Estimation of X'>)> plt.legend([>'Kernel Density Estimation'>,>'Mixture Density'>])> plt.show()> |
>
>
Výstup :
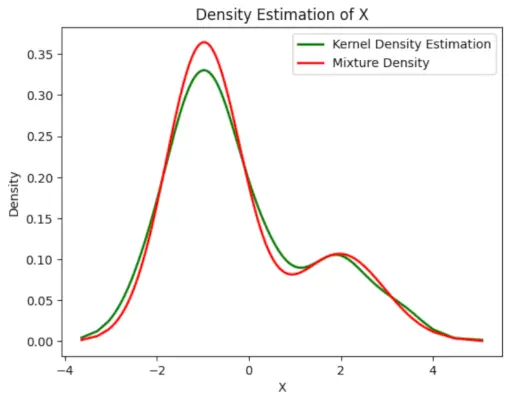
Odhadovaná hustota
Aplikace EM algoritmus
- Lze jej použít k doplnění chybějících údajů ve vzorku.
- Lze jej použít jako základ neřízeného učení klastrů.
- Lze jej použít pro účely odhadu parametrů skrytého Markovova modelu (HMM).
- Lze jej použít pro zjišťování hodnot latentních proměnných.
Výhody EM algoritmu
- Vždy je zaručeno, že se pravděpodobnost s každou iterací zvýší.
- E-krok a M-krok jsou často velmi snadné pro mnoho problémů z hlediska implementace.
- Řešení M-kroků často existují v uzavřené formě.
Nevýhody EM algoritmu
- Má pomalou konvergenci.
- Dosahuje pouze konvergence k lokálnímu optimu.
- Vyžaduje obě pravděpodobnosti, dopřednou i zpětnou (numerická optimalizace vyžaduje pouze dopřednou pravděpodobnost).