Logistická regrese v R Programming je klasifikační algoritmus používaný k nalezení pravděpodobnosti úspěchu a selhání události. Logistická regrese se používá, když je závislá proměnná binární (0/1, pravda/nepravda, ano/ne). Funkce logit se používá jako spojovací funkce v binomickém rozdělení.
Pravděpodobnost binární výsledné proměnné lze předpovědět pomocí techniky statistického modelování známé jako logistická regrese. Je široce používán v mnoha různých odvětvích, včetně marketingu, financí, společenských věd a lékařského výzkumu.
Logistická funkce, běžně označovaná jako sigmoidní funkce, je základní myšlenkou, na níž je založena logistická regrese. Tato sigmoidní funkce se používá v logistické regresi k popisu korelace mezi prediktorovými proměnnými a pravděpodobností binárního výsledku.

Logistická regrese v R programování
Logistická regrese je také známá jako Binomická logistická regrese . Je založena na sigmoidní funkci, kde výstup je pravděpodobnost a vstup může být od -nekonečna do +nekonečna.
Teorie
Logistická regrese je také známá jako zobecněný lineární model. Protože se používá jako klasifikační technika k predikci kvalitativní odezvy, hodnota y se pohybuje od 0 do 1 a může být reprezentována následující rovnicí:
Logistická regrese v R programování
p je pravděpodobnost charakteristiky zájmu. Poměr šancí je definován jako pravděpodobnost úspěchu ve srovnání s pravděpodobností neúspěchu. Je to klíčová reprezentace koeficientů logistické regrese a může nabývat hodnot mezi 0 a nekonečnem. Poměr šancí 1 je, když se pravděpodobnost úspěchu rovná pravděpodobnosti neúspěchu. Poměr šancí 2 je, když pravděpodobnost úspěchu je dvojnásobkem pravděpodobnosti neúspěchu. Poměr šancí 0,5 je, když pravděpodobnost neúspěchu je dvojnásobkem pravděpodobnosti úspěchu.
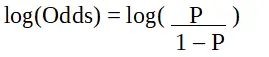
Logistická regrese v R programování
Protože pracujeme s binomickým rozdělením (závislá proměnná), musíme zvolit funkci odkazu, která je pro toto rozdělení nejvhodnější.
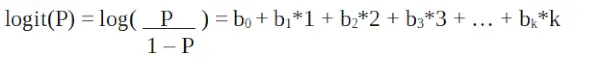
Logistická regrese v R programování
Je to a funkce logit . Ve výše uvedené rovnici je závorka zvolena tak, aby maximalizovala pravděpodobnost pozorování hodnot vzorku spíše než minimalizovala součet čtvercových chyb (jako běžná regrese). Logit je také známý jako log odds. Logit funkce musí být lineárně vztažena k nezávislým proměnným. Toto je z rovnice A, kde levá strana je lineární kombinací x. To je podobné předpokladu OLS, že y je lineárně závislé na x. Proměnné b0, b1, b2 … atd. jsou neznámé a musí být odhadnuty na dostupných tréninkových datech. V modelu logistické regrese se vynásobením b1 jednou jednotkou změní logit b0. Změny P v důsledku změny o jednu jednotku budou záviset na vynásobené hodnotě. Pokud je b1 kladné, P se zvýší a pokud je b1 záporné, P se sníží.
Soubor dat
mtcars (motor trend car road test) zahrnuje spotřebu paliva, výkon a 10 aspektů automobilového designu pro 32 automobilů. Dodává se s předinstalovaným dplyr balíček v R.
R
nahradit řetězec java
# Installing the package> install.packages>(>'dplyr'>)> # Loading package> library>(dplyr)> # Summary of dataset in package> summary>(mtcars)> |
>
>
Provádění logistické regrese na datové sadě
Logistická regrese je implementována v R pomocí glm() trénováním modelu pomocí funkcí nebo proměnných v datové sadě.
R
# Installing the package> # For Logistic regression> install.packages>(>'caTools'>)> # For ROC curve to evaluate model> install.packages>(>'ROCR'>)> > # Loading package> library>(caTools)> library>(ROCR)> |
>
>
Rozdělení dat
R
# Splitting dataset> split <->sample.split>(mtcars, SplitRatio = 0.8)> split> train_reg <->subset>(mtcars, split ==>'TRUE'>)> test_reg <->subset>(mtcars, split ==>'FALSE'>)> # Training model> logistic_model <->glm>(vs ~ wt + disp,> >data = train_reg,> >family =>'binomial'>)> logistic_model> # Summary> summary>(logistic_model)> |
>
>
Výstup:
Call: glm(formula = vs ~ wt + disp, family = 'binomial', data = train_reg) Deviance Residuals: Min 1Q Median 3Q Max -1.6552 -0.4051 0.4446 0.6180 1.9191 Coefficients: Estimate Std. Error z value Pr(>|z|) (Zachycení) 1,58781 2,60087 0,610 0,5415 hmotn. 1,36958 1,60524 0,853 0,3936 rozp. -0,02969 0,01577 -1,898 0,05 --- Signif. kódy: 0 '***' 0,001 '**' 0,01 '*' 0,05 '.' 0,1 ' ' 1 (Parametr rozptylu pro binomickou rodinu považován za 1) Nulová odchylka: 34,617 na 24 stupních volnosti Zbytková odchylka: 20,21 22 stupňů volnosti AIC: 26,212 Počet iterací Fisher Scoring: 6>
- Volání: Zobrazí se volání funkce použité k přizpůsobení modelu logistické regrese spolu s informacemi o rodině, vzorci a datech. Zbytky deviace: Toto jsou zbytky deviace, které měří stupeň dobré shody modelu. Představují nesrovnalosti mezi skutečnými odpověďmi a pravděpodobností předpovězenou modelem logistické regrese. Koeficienty: Tyto koeficienty v logistické regresi představují logaritmus nebo logit pravděpodobnosti proměnné odezvy. Směrodatné chyby související s odhadovanými koeficienty jsou uvedeny ve Std. Sloupec chyb. Kódy významnosti: Úroveň významnosti každé proměnné prediktoru je označena kódy významnosti. Parametr disperze: V logistické regresi slouží parametr disperze jako parametr škálování pro binomické rozdělení. V tomto případě je nastavena na 1, což znamená, že předpokládaný rozptyl je 1. Nulová odchylka: Nulová odchylka vypočítá odchylku modelu, když se vezme v úvahu pouze průsečík. Symbolizuje odchylku, která by byla výsledkem modelu bez prediktorů. Zbytková odchylka: Zbytková odchylka vypočítá odchylku modelu poté, co byly přizpůsobeny prediktory. Znamená zbytkovou odchylku po zohlednění prediktorů. AIC: Akaike Information Criterion (AIC), které odpovídá počtu prediktorů, je měřítkem dobré shody modelu. Penalizuje složitější modely, aby se zabránilo nadměrnému vybavení. Lépe padnoucí modely jsou označeny nižšími hodnotami AIC. Počet iterací Fisher Scoring: Počet iterací potřebných pro postup Fisher skórování k odhadu parametrů modelu je indikován počtem iterací.
Předvídejte testovací data na základě modelu
R
jak převést celé číslo na řetězec java
predict_reg <->predict>(logistic_model,> >test_reg, type =>'response'>)> predict_reg> |
>
>
Výstup:
Hornet Sportabout Merc 280C Merc 450SE Chrysler Imperial 0.01226166 0.78972164 0.26380531 0.01544309 AMC Javelin Camaro Z28 Ford Pantera L 0.06104267 0.02807992 0.01107943>
R
# Changing probabilities> predict_reg <->ifelse>(predict_reg>0,5, 1, 0)> # Evaluating model accuracy> # using confusion matrix> table>(test_reg$vs, predict_reg)> missing_classerr <->mean>(predict_reg != test_reg$vs)> print>(>paste>(>'Accuracy ='>, 1 - missing_classerr))> # ROC-AUC Curve> ROCPred <->prediction>(predict_reg, test_reg$vs)> ROCPer <->performance>(ROCPred, measure =>'tpr'>,> >x.measure =>'fpr'>)> auc <->performance>(ROCPred, measure =>'auc'>)> auc <- [email protected][[1]]> auc> # Plotting curve> plot>(ROCPer)> plot>(ROCPer, colorize =>TRUE>,> >print.cutoffs.at =>seq>(0.1, by = 0.1),> >main =>'ROC CURVE'>)> abline>(a = 0, b = 1)> auc <->round>(auc, 4)> legend>(.6, .4, auc, title =>'AUC'>, cex = 1)> |
>
>
Výstup:
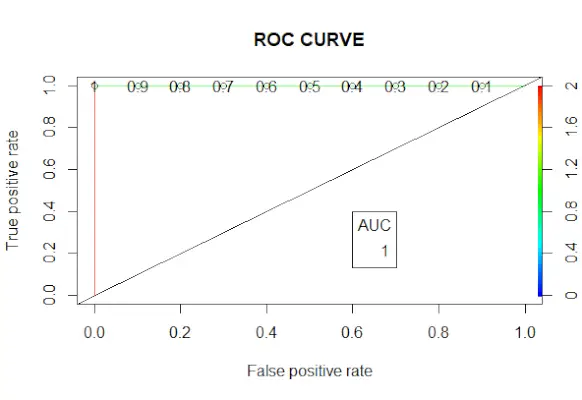
ROC křivka
Příklad 2:
Můžeme provést logistický regresní model Titanic Data set v R.
R
# Load the dataset> data>(Titanic)> # Convert the table to a data frame> data <->as.data.frame>(Titanic)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # View the summary of the model> summary>(model)> |
>
>
Výstup:
Call: glm(formula = Survived ~ Class + Sex + Age, family = binomial, data = data) Deviance Residuals: Min 1Q Median 3Q Max -1.177 -1.177 0.000 1.177 1.177 Coefficients: Estimate Std. Error z value Pr(>|z|) (Zásah) 4.022e-16 8.660e-01 0 1 Třída2. -9.762e-16 1.000e+00 0 1 Třída3. -4.699e-16 1.000e+00 0 1 TřídaePosádka -5.551.00 00 0 1 SexFemale -3.140e-16 7.071e-01 0 1 AgeAdult 5.103e-16 7.071e-01 0 1 (Parametr rozptylu pro binomickou rodinu je považován za 1) Nulová odchylka: 44.361 volnosti 443. deviances 31 stupňů na 26 stupních volnosti AIC: 56,361 Počet iterací Fisher Scoring: 2>
Vyneste křivku ROC pro soubor dat Titanicu
R
iterační mapa java
# Install and load the required packages> install.packages>(>'ROCR'>)> library>(ROCR)> # Fit the logistic regression model> model <->glm>(Survived ~ Class + Sex + Age, family = binomial, data = data)> # Make predictions on the dataset> predictions <->predict>(model, type =>'response'>)> # Create a prediction object for ROCR> prediction_objects <->prediction>(predictions, titanic_df$Survived)> # Create an ROC curve object> roc_object <->performance>(prediction_obj, measure =>'tpr'>, x.measure =>'fpr'>)> # Plot the ROC curve> plot>(roc_object, main =>'ROC Curve'>, col =>'blue'>, lwd = 2)> # Add labels and a legend to the plot> legend>(>'bottomright'>, legend => >paste>(>'AUC ='>,>round>(>performance>(prediction_objects, measure =>'auc'>)> >@y.values[[1]], 2)), col =>'blue'>, lwd = 2)> |
>
>
Výstup:
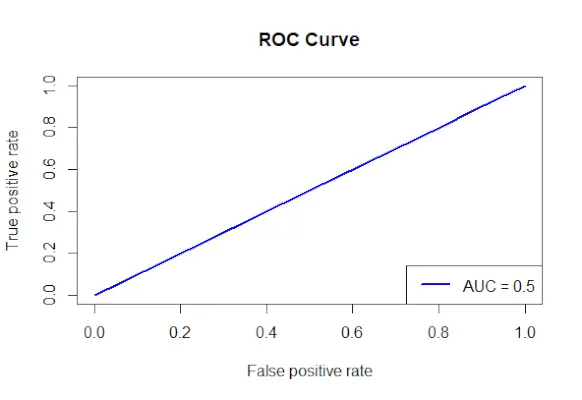
ROC křivka
- Jsou specifikovány faktory používané k predikci přežití a k vytvoření modelu logistické regrese je použit vzorec Přeživší třída + pohlaví + věk.
- Pomocí funkce Predikce() se provádějí předpovědi na množině dat pomocí přizpůsobeného modelu.
- Předpokládané pravděpodobnosti jsou kombinovány se skutečnými výstupními hodnotami za účelem vytvoření objektu predikce pomocí metody forecast() z balíku ROCR.
- Stanoví se míra skutečné pozitivní frekvence (tpr) a míra falešné pozitivní osy (fpr) na ose x a pomocí funkce performance() z balíku ROCR se vytvoří objekt ROC křivky.
- Objekt ROC křivky (roc_obj), který určuje hlavní nadpis, barvu a šířku čáry, se vykresluje pomocí funkce plot().
- K určení hodnoty AUC (plocha pod křivkou) používá funkci performance() s mírou = auc a ke grafu přidává popisky a legendu.