Co je LRU Cache?
Algoritmy výměny mezipaměti jsou efektivně navrženy tak, aby nahradily mezipaměť, když je místo plné. The Nejméně uživaný v poslední době (LRU) je jedním z těchto algoritmů. Jak název napovídá, když je vyrovnávací paměť plná, LRU vybere data, která byla naposledy použitá, a odstraní je, aby se uvolnilo místo pro nová data. Priorita dat v mezipaměti se mění podle potřeby těchto dat, tj. pokud jsou některá data načtena nebo aktualizována nedávno, priorita těchto dat by byla změněna a přiřazena k nejvyšší prioritě a priorita dat se sníží, pokud zůstává po operacích nevyužité operace.
Obsah
- Co je LRU Cache?
- Operace na mezipaměti LRU:
- Fungování LRU Cache:
- Způsoby implementace LRU Cache:
- Implementace mezipaměti LRU pomocí fronty a hašování:
- Implementace mezipaměti LRU pomocí dvojitě propojeného seznamu a hašování:
- Implementace mezipaměti LRU pomocí Deque & Hashmap:
- Implementace mezipaměti LRU pomocí Stack & Hashmap:
- Mezipaměť LRU pomocí implementace Counter:
- Implementace mezipaměti LRU pomocí Lazy Updates:
- Analýza komplexnosti mezipaměti LRU:
- Výhody LRU cache:
- Nevýhody LRU cache:
- Aplikace LRU Cache v reálném světě:
LRU Algoritmus je standardní problém a může mít odchylky podle potřeby, například v operačních systémech LRU hraje klíčovou roli, protože může být použit jako algoritmus náhrady stránky, aby se minimalizovaly chyby stránky.
Operace na mezipaměti LRU:
- LRUCache (kapacita c): Inicializujte mezipaměť LRU s kladnou kapacitou C.
- získat (klíč) : Vrátí hodnotu klíče ' k' pokud je přítomen v mezipaměti, jinak vrátí -1. Aktualizuje také prioritu dat v mezipaměti LRU.
- dát (klíč, hodnota): Aktualizujte hodnotu klíče, pokud tento klíč existuje. V opačném případě přidejte pár klíč–hodnota do mezipaměti. Pokud počet klíčů překročí kapacitu mezipaměti LRU, zrušte poslední použitý klíč.
Fungování LRU Cache:
Předpokládejme, že máme mezipaměť LRU o kapacitě 3 a chtěli bychom provést následující operace:
- Vložte (klíč=1, hodnota=A) do mezipaměti
- Vložte (klíč=2, hodnota=B) do mezipaměti
- Vložte (klíč=3, hodnota=C) do mezipaměti
- Získejte (klíč=2) z mezipaměti
- Získejte (klíč=4) z mezipaměti
- Vložte (klíč=4, hodnota=D) do mezipaměti
- Vložte (klíč=3, hodnota=E) do mezipaměti
- Získejte (klíč=4) z mezipaměti
- Vložte (klíč=1, hodnota=A) do mezipaměti
Výše uvedené operace se provádějí jedna po druhé, jak je znázorněno na obrázku níže:
Podrobné vysvětlení každé operace:
- Dejte (klíč 1, hodnota A) : Vzhledem k tomu, že mezipaměť LRU má prázdnou kapacitu=3, není potřeba žádná výměna a na začátek jsme umístili {1 : A}, tj. {1 : A} má nejvyšší prioritu.
- Dejte (klíč 2, hodnota B) : Vzhledem k tomu, že mezipaměť LRU má prázdnou kapacitu=2, opět není potřeba žádná výměna, ale nyní má {2 : B} nejvyšší prioritu a prioritu snížení {1 : A}.
- Dejte (klíč 3, hodnota C) : Stále je v mezipaměti 1 volné místo, proto vložte {3 : C} bez jakékoli náhrady, všimněte si, že nyní je mezipaměť plná a aktuální pořadí priorit od nejvyšší po nejnižší je {3:C}, {2:B }, {1:A}.
- Získat (klíč 2) : Nyní vraťte hodnotu klíče=2 během této operace, také protože je použit klíč=2, nyní je nové pořadí priority {2:B}, {3:C}, {1:A}
- Získejte (klíč 4): Všimněte si, že klíč 4 není přítomen v mezipaměti, pro tuto operaci vrátíme „-1“.
- Dejte (klíč 4, hodnota D) : Všimněte si, že mezipaměť je PLNÁ, nyní pomocí algoritmu LRU určete, který klíč byl naposledy použit. Protože {1:A} mělo nejmenší prioritu, odstraňte {1:A} z naší mezipaměti a vložte do mezipaměti {4:D}. Všimněte si, že nové pořadí priority je {4:D}, {2:B}, {3:C}
- Dejte (klíč 3, hodnota E) : Vzhledem k tomu, že klíč=3 již byl v mezipaměti přítomen s hodnotou=C, tato operace nepovede k odstranění žádného klíče, spíše aktualizuje hodnotu klíče=3 na „ A' . Nyní se nové pořadí priority stane {3:E}, {4:D}, {2:B}
- Získejte (klíč 4) : Vrátí hodnotu key=4. Nyní se nová priorita stane {4:D}, {3:E}, {2:B}
- Dejte (klíč 1, hodnota A) : Protože je naše mezipaměť PLNÁ, použijte náš algoritmus LRU k určení, který klíč byl naposledy použit, a protože {2:B} měl nejmenší prioritu, odeberte {2:B} z naší mezipaměti a vložte {1:A} do mezipaměti. Nyní je nové pořadí priority {1:A}, {4:D}, {3:E}
Způsoby implementace LRU Cache:
LRU cache lze implementovat různými způsoby a každý programátor může zvolit jiný přístup. Níže jsou však běžně používané přístupy:
- LRU pomocí fronty a hashování
- pomocí LRU Dvojitě propojený seznam + hašování
- LRU pomocí Deque
- LRU pomocí Stack
- pomocí LRU Implementace pultu
- LRU pomocí Lazy Updates
Implementace mezipaměti LRU pomocí fronty a hašování:
K implementaci LRU Cache používáme dvě datové struktury.
- Fronta je implementován pomocí dvojitě propojeného seznamu. Maximální velikost fronty bude rovna celkovému počtu dostupných snímků (velikost mezipaměti). Naposledy použité stránky budou blízko předního konce a nejméně naposledy použité stránky budou blízko zadního konce.
- Hash s číslem stránky jako klíčem a adresou odpovídajícího uzlu fronty jako hodnotou.
Když je odkazováno na stránku, požadovaná stránka může být v paměti. Pokud je v paměti, musíme odpojit uzel seznamu a přenést jej na začátek fronty.
Pokud požadovaná stránka není v paměti, přeneseme ji do paměti. Jednoduše řečeno, přidáme nový uzel na začátek fronty a aktualizujeme odpovídající adresu uzlu v hash. Pokud je fronta plná, tj. všechny rámce jsou plné, odebereme uzel ze zadní části fronty a přidáme nový uzel do přední části fronty.
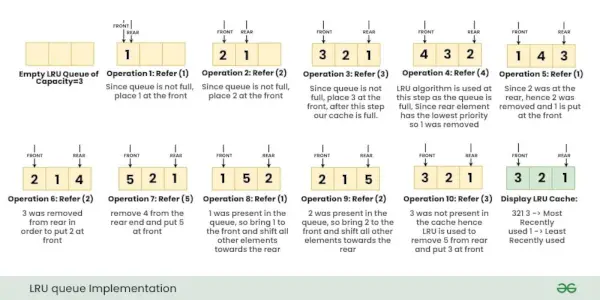
Ilustrace:
Podívejme se na operace, Odkazy klíč X s v mezipaměti LRU: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Poznámka: Zpočátku není v paměti žádná stránka.Níže uvedené obrázky ukazují krok za krokem provádění výše uvedených operací na mezipaměti LRU.
Algoritmus:
- Vytvořte třídu LRUCache s deklarací seznamu typu int, neuspořádané mapy typu
- V referenční funkci LRUCache
- Pokud tato hodnota není přítomna ve frontě, vložte tuto hodnotu před frontu a odstraňte poslední hodnotu, pokud je fronta plná
- Pokud je hodnota již přítomna, odeberte ji z fronty a posuňte ji do přední části fronty
- V zobrazení funkce tisku, LRUCache pomocí fronty začínající zepředu
Níže je uvedena implementace výše uvedeného přístupu:
C++
weby jako coomeet
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;> > >// store references of key in cache> >unordered_map<>int>, list<>int>>::iterator> ma;> >int> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->pageNumber = pageNumber;> > >// Initialize prev and next as NULL> >temp->předchozí = temp->další = NULL;> > >return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->počet = 0;> >queue->přední = fronta->zadní = NULL;> > >// Number of frames that can be stored in memory> >queue->počet snímků = počet snímků;> > >return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->kapacita = kapacita;> > >// Create an array of pointers for referring queue nodes> >hash->pole> >= (QNode**)>malloc>(hash->kapacita *>sizeof>(QNode*));> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->pole[i] = NULL;> > >return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->počet == fronta->počet snímků;> }> > // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->zadní == NULL;> }> > // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->přední == fronta->zadní)> >queue->přední = NULL;> > >// Change rear and remove the previous rear> >QNode* temp = queue->zadní;> >queue->zadní = fronta->zadní->předchozí;> > >if> (queue->zadní)> >queue->zadní->další = NULL;> > >free>(temp);> > >// decrement the number of full frames by 1> >queue->počet--;> }> > // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->pole[fronta->zadni->číslo stránky] = NULL;> >deQueue(queue);> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->další = fronta->přední;> > >// If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->zadní = fronta->přední = teplota;> >else> // Else change the front> >{> >queue->přední->předchozí = teplota;> >queue->přední = teplota;> >}> > >// Add page entry to hash also> >hash->pole[číslo stránky] = temp;> > >// increment number of full frames> >queue->počet++;> }> > // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->pole[číslo stránky];> > >// the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->přední) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->předchozí->další = reqStránka->další;> >if> (reqPage->další)> >reqPage->next->prev = reqPage->prev;> > >// If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->zadní) {> >queue->zadní = reqPage->prev;> >queue->zadní->další = NULL;> >}> > >// Put the requested page before current front> >reqPage->další = fronta->přední;> >reqPage->předchozí = NULL;> > >// Change prev of current front> >reqPage->dalsi->prev = reqPage;> > >// Change front to the requested page> >queue->front = reqPage;> >}> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->front->pageNumber);> >printf>(>'%d '>, q->front->next->pageNumber);> >printf>(>'%d '>, q->front->next->next->pageNumber);> >printf>(>'%d '>, q->front->next->next->next->pageNumber);> > >return> 0;> }> |
>
>
Jáva
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doubleQueue;> > >// store references of key in cache> >private> HashSet<>int>>hashSet;> > >// maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();> >hashSet =>new> HashSet<>int>>();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
Implementace mezipaměti LRU pomocí dvojitě propojeného seznamu a hašování :
Myšlenka je velmi základní, tj. vkládat prvky do hlavy.
- pokud prvek není v seznamu přítomen, přidejte jej na začátek seznamu
- pokud je prvek v seznamu přítomen, přesuňte prvek do záhlaví a posuňte zbývající prvek seznamu
Všimněte si, že priorita uzlu bude záviset na vzdálenosti tohoto uzlu od hlavy, čím nejblíže je uzel k hlavě, tím vyšší prioritu má. Takže když je velikost mezipaměti plná a potřebujeme odstranit nějaký prvek, odstraníme prvek sousedící s koncem dvojitě propojeného seznamu.
Implementace mezipaměti LRU pomocí Deque & Hashmap:
Struktura dat deque umožňuje vkládání a mazání zepředu i z konce, tato vlastnost umožňuje implementaci LRU, protože Front element může představovat prvek s vysokou prioritou, zatímco koncový prvek může být prvek s nízkou prioritou, tj. Nejméně nedávno použitý.
Pracovní:
- Získejte operaci : Zkontroluje, zda klíč existuje v hash mapě mezipaměti, a postupujte podle níže uvedených případů na deque:
- Pokud je klíč nalezen:
- Položka je považována za nedávno použitou, proto je přesunuta na přední stranu deque.
- Hodnota spojená s klíčem je vrácena jako výsledek
get>úkon.- Pokud klíč není nalezen:
- návrat -1 označující, že žádný takový klíč není přítomen.
- Uvedení operace: Nejprve zkontrolujte, zda klíč již existuje v hash mapě mezipaměti, a postupujte podle níže uvedených případů na deque
- Pokud klíč existuje:
- Hodnota spojená s klíčem se aktualizuje.
- Položka se přesune na přední stranu deque, protože je nyní naposledy použitá.
- Pokud klíč neexistuje:
- Pokud je mezipaměť plná, znamená to, že je třeba vložit novou položku a nejméně nedávno použitou položku je nutné vyřadit. To se provádí odstraněním položky z konce deque a odpovídající položky z hash mapy.
- Nový pár klíč–hodnota se pak vloží jak do hashové mapy, tak do přední části deque, což znamená, že se jedná o naposledy použitou položku.
Implementace mezipaměti LRU pomocí Stack & Hashmap:
Implementace mezipaměti LRU (nejméně nedávno použité) pomocí datové struktury zásobníku a hašování může být trochu složitější, protože jednoduchý zásobník neposkytuje efektivní přístup k nejméně nedávno použité položce. Můžete však kombinovat zásobník s hašovací mapou, abyste toho dosáhli efektivně. Zde je přístup na vysoké úrovni k jeho implementaci:
- Použijte hash mapu : Mapa hash bude ukládat páry klíč-hodnota mezipaměti. Klíče se namapují na odpovídající uzly v zásobníku.
- Použijte zásobník : Zásobník zachová pořadí klíčů na základě jejich použití. Nejméně nedávno použitá položka bude ve spodní části zásobníku a naposledy použitá položka bude nahoře
Tento přístup není tak účinný, a proto se často nepoužívá.
soukromá vs veřejná java
Mezipaměť LRU pomocí implementace Counter:
Každý blok v mezipaměti bude mít svůj vlastní čítač LRU, ke kterému patří hodnota čítače {0 až n-1} , tady ' n ‘ představuje velikost mezipaměti. Blok, který se změní při výměně bloku, se stane blokem MRU a v důsledku toho se jeho hodnota čítače změní na n – 1. Hodnoty čítače větší než hodnota čítače zpřístupněného bloku se sníží o jednu. Zbývající bloky jsou beze změny.
| Hodnota Conter | Přednost | Použitý stav |
|---|---|---|
| 0 | Nízký | Nejméně uživaný v poslední době |
| n-1 | Vysoký | Naposledy použité |
Implementace mezipaměti LRU pomocí Lazy Updates:
Implementace mezipaměti LRU (nejméně nedávno používaná) pomocí líných aktualizací je běžnou technikou ke zlepšení efektivity operací mezipaměti. Líné aktualizace zahrnují sledování pořadí, ve kterém se přistupuje k položkám, aniž by se okamžitě aktualizovala celá datová struktura. Když dojde k chybě mezipaměti, můžete se na základě určitých kritérií rozhodnout, zda provést úplnou aktualizaci či nikoli.
Analýza komplexnosti mezipaměti LRU:
- Časová náročnost:
- Operace Put(): O(1), tj. čas potřebný k vložení nebo aktualizaci nového páru klíč–hodnota je konstantní
- Operace Get(): O(1) tj. čas potřebný k získání hodnoty klíče je konstantní
- Pomocný prostor: O(N), kde N je kapacita mezipaměti.
Výhody LRU cache:
- Rychlý přístup : Přístup k datům z mezipaměti LRU trvá O(1).
- Rychlá aktualizace : Aktualizace páru klíč–hodnota v mezipaměti LRU trvá O(1).
- Rychlé odstranění nejméně nedávno použitých dat : Trvá O(1) smazat to, co nebylo nedávno použito.
- Žádné mlácení: LRU je ve srovnání s FIFO méně náchylná k thrashování, protože bere v úvahu historii používání stránek. Dokáže zjistit, které stránky jsou často používány, a upřednostnit je pro alokaci paměti, čímž se sníží počet chyb stránek a diskových I/O operací.
Nevýhody LRU cache:
- Ke zvýšení efektivity vyžaduje velkou velikost mezipaměti.
- Vyžaduje implementaci další datové struktury.
- Hardwarová pomoc je vysoká.
- V LRU je detekce chyb ve srovnání s jinými algoritmy obtížná.
- Má omezenou přijatelnost.
Aplikace LRU Cache v reálném světě:
- V databázových systémech pro rychlé výsledky dotazů.
- V operačních systémech k minimalizaci chyb stránek.
- Textové editory a IDE pro ukládání často používaných souborů nebo úryvků kódu
- Síťové směrovače a přepínače využívají LRU ke zvýšení efektivity počítačové sítě
- V optimalizacích kompilátoru
- Nástroje pro predikci textu a automatické dokončování